一面 (电话面试)
1、介绍自己比较熟悉的项目和项目中遇到的难点
2、Springbean生命周期
bean创建: new一个对象到容器–>属性注入–>是否实现了Aware类–>后置处理器,执行初始化前的方法–>初始化–>后置处理器,执行初始化完成后的方法–>完成bean创建
销毁: 执行@PostDestroy 注解的方法–>bean实现了DisposableBean,执行destroy方法–>执行配置文件中的destroy-method
3、谈谈依赖注入和面向切面
依赖注入: 通过发射的方式,把创建bean的权限交由spring来统一管理,可以避免硬编码造成的代码耦合
面向切面: aop是面向切面编程的思想,spring通过代理的方式,将面向切面编程定义成一个规范,通过代理模式,将两个或多个有关联的业务,在代码层面实现节藕
4、HashMap原理和扩容机制
hashmap的内部实现是数组和链表的结合,新建hashmap的时候会默认初始化数组长度为16,精准度为0.75;执行插入操作时,通过通过给key做hash处理,将得到的值和16求膜,将value插入与之对应的小标;当出现相同的下标,value将通过链表的形式链接起来,并且是将value插入到最顶端;
5、常用并发包下的类
接口: Callback,Future ,FutureService ,Executor,BlockingQueue
类: ConcurrentHashMap,ConcurrentListMap,ConcurrentListSet,CopyOnWriteArrayList, CopyOnWriteArraySet,ArrayBlockingQueue,FutureTask,ListedBlockingQueue,Executors,ThreadPoolExecutor
6、Redis持久化方式,为什么这么快?
自己总结:
- 内存数据库,一减少对磁盘读取的IO
- 非阻塞IO,IO多路复用
- 单线程模型,减少线程上下文切换和竞争
参考其他的总结:
一、 Redis是纯内存数据库,一般都是简单的存取操作,线程占用的时间很多,时间的花费主要集中在IO上,所以读取速度快。
二、 再说一下IO,Redis使用的是__非阻塞IO,IO多路复用__,使用了__单线程来轮询描述符__,将数据库的开、关、读、写都转换成了事件,减少了线程切换时上下文的切 换和竞争。
三、 Redis采用了__单线程的模型__,保证了每个操作的原子性,也减少了线程的上下文切换和竞争。
四、另外,数据结构也帮了不少忙,Redis全程使用hash结构,读取速度快,还有一些特殊的数据结构,对数据存储进行了优化,如压缩表,对短数据进行压缩存储 ,再如,跳表,使用有序的数据结构加快读取的速度。
五、还有一点,Redis采用自己实现的事件分离器,效率比较高,内部采用非阻塞的执行方式,吞吐能力比较大。
7、自己平时如何提升的,看书或者网站?
二面
1、Jvm类加载机制,分别每一步做了什么工作?
加载–>校验–>解析–>准备–>解析–>初始化–>使用–>卸载
加载: 将Class类加载到内存,接着在JVM的方法区创建一个对应的Class对象
校验: JVM代码规范娇艳,代码逻辑校验
准备: 分配内存并初始化,这里需要注意两个关键点,内存分配的对象以及初始化的类型。初始化的是static 修饰的类变量
解析: JVM 针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用点限定符 7 类引用进行解析
初始化: JVM 会根据语句执行顺序对类对象进行初始化,一般来说当 JVM 遇到下面 5 种情况的时候会触发初始化
使用: JVM 开始从入口方法开始执行用户的程序代码
卸载: JVM 开始销毁创建的 Class 对象
2、Jvm内存模型,垃圾回收机制,如何确定被清除的对象?
共享内存区: 堆,方法区
私有内存区: 栈,计数器,本地方法区
堆: 存放对象和数组,也是GC处理的区域
方法区: 用于存放常量,静态变量,Class
栈: 保存栈帧,栈帧中包括:局部变量表(方法参数,也可以是方法的局部变量)、操作数栈、动态链接、方法出口
计数器: 当线程数大于CPU核数,线程之间就要根据时间片轮询抢夺CPU时间资源,计数器会记录线程的状态及上下文
本地方法区: 调用扩展方法,通常是通过 JNI 调用 C或C++
垃圾回收机制: 引用计数算法 可达性分析算法 分代收集算法
触发轻GC的条件:
当新对象生成,并且在Eden申请空间失败时,就会触发,通常就是 Eden 空间满的时候触发
触发重GC的条件:
a) 年老代(Tenured)被写满;
b) 持久代(Perm)被写满;
c) System.gc()被显示调用;
d) 上一次GC之后Heap的各域分配策略动态变化;
3、了解哪些垃圾回收器和区别?
| 垃圾回收器 | 说明 | 特性 | JVM参数 |
|---|---|---|---|
| 单行垃圾回收器 | 为单线程环境设计,只使用一个单线程进行垃圾回收 | 通过持有应用程序所有的线程进行工作 | -XX:+UseSerialGC |
| 并行垃圾回收器 | 多线程垃圾回收 | 也会冻结所有的应用程序线程当执行垃圾回收的时候 | 默认使用,不需要单独配置 |
| 并发标记垃圾回收器 | 使用多线程扫描堆内存 | 标记需要清理的实例并且清理被标记过的实例 | XX:+USeParNewGC |
| G1垃圾回收器 | 可以在回收内存之后对剩余的堆内存空间进行压缩 | 适用于堆内存很大的情况,他将堆内存分割成不同的区域,并且并发的对其进行垃圾回收 | –XX:+UseG1GC |
4、多线程相关,线程池的参数列表和拒绝策略
public ThreadPoolExecutor(int corePoolSize, // 核心线程数
int maximumPoolSize, // 最大线程数
long keepAliveTime, // 超时时间数
TimeUnit unit, // 超时时间单位
BlockingQueue<Runnable> workQueue, // 设置排队线程
ThreadFactory threadFactory, // 线程工厂
RejectedExecutionHandler handler // 拒绝策略 ) {
。。。。
}
-
直接丢弃(DiscardPolicy)
-
丢弃队列中最老的任务(DiscardOldestPolicy)。
-
抛异常(AbortPolicy)
-
将任务分给调用线程来执行(CallerRunsPolicy)。
5、Jvm如何分析出哪个对象上锁?
6、Mysql索引类型和区别,事务的隔离级别和事务原理
索引的概念:
- 索引是特殊的文件,饱含着对所有数据表里所有记录的引用指针
- 索引分为:聚簇索引、非聚簇索引,聚簇索引是按照数据存放的物理位置为顺序的,而非聚簇索引就不一样了;聚簇索引:能提高多行检索的速度,非聚簇索引:单行的检索很快。
- 要注意的是,建立太多的索引将会影响更新和插入的速度,因为它需要同样更新每个索引文件。对于一个经常需要更新和插入的表格,就没有必要为一个很少使用的where字句单独建立索引了,对于比较小的表,排序的开销不会很大,也没有必要建立另外的索引。
索引的类型:
- 普通索引: 唯一任务是加快对数据的访问速度
- 唯一性索引: 与普通索引类似,不同的就是:索引列的值必须唯一
- 全文索引: 全文索引只能作用在 CHAR、VARCHAR、TEXT、类型的字段上。创建全文索引需要使用 FULLTEXT 参数进行约束
- 单列索引: 创建单列索引,即在数据表的单个字段上创建索引。创建该类型索引不需要引入约束参数,用户在建立时只需要指定单列字段名,即可创建单列索引
- 多列索引: 创建多列索引,即在数据表的多个字段上创建索引。与上述单列索引类似,创建该类型索引不需要引入约束参数。
- 空间索引: 只有 MyISAM 类型的表支持该类型 ‘ 空间索引 ’。而且,索引字段必须有非空约束
MySQL 事务隔离级别分为四个不同层次:
- 读未提交: 事务能够看到其他事务尚未提交的修改
- 读已提交: 事务能够看到的数据都是其他事务已经提交的修改,并不保证再次读取时能够获取同样的数据
- 可重复读(MySQL InnoDB 引擎的默认隔离级别):
- 串行化: 并发事务之间是串行化的,通常意味着读取需要获取共享读锁,更新需要获取排他写锁
7、Spring scope 和设计模式
饿汉模式 懒汉模式 内部类 枚举
8、Sql优化
- sql 命令优化,比如 count(1) 比count(*) 效率高,可通过在sql命令前加 explain
- 添加索引
- 分库分表,读写分离
- 数据库分区
三面
1、fullgc的时候会导致接口的响应速度特别慢,该如何排查和解决?
- Full GC次数过多
- CPU过高
- 不定期出现的接口耗时现象
- 某个线程进入WAITING状态
- 死锁
2、项目内存或者CPU占用率过高如何排查?
3、ConcurrentHashmap原理
-
一个ConcurrentHashMap维护一个Segment数组,一个Segment维护一个HashEntry数组
-
对于同一个Segment的操作才需考虑线程同步,不同的Segment则无需考虑
-
我们说Segment类似哈希表,那么一些属性就跟我们之前提到的HashMap差不离,比如负载因子loadFactor,比如阈值threshold等等,看下Segment的构造方法
Segment(float lf, int threshold, HashEntry<K,V>[] tab) {
this.loadFactor = lf;//负载因子
this.threshold = threshold;//阈值
this.table = tab;//主干数组即HashEntry数组
}
4、数据库分库分表
- 纵向:
- 垂直分库:根据业务耦合性,将关联度低的不同表存储在不同的数据库
- 垂直分表:基于数据库中的”列”进行,某个表字段较多
- 横向:
- 根据数值范围
- 根据数值取模
5、MQ相关,为什么kafka这么快,什么是零拷贝?
-
kafka这么快
- kaffa保存数据是按照顺序保存到磁盘,磁盘顺序读写速度 > 内存随机读写速度
-
Memory Mapped Files(内存映射文件)
- 基于sendfile实现Zero Copy,减少拷贝次数
- 批量压缩
6、小算法题
7、http和https协议区别,具体原理
HTTP与HTTPS有什么区别?
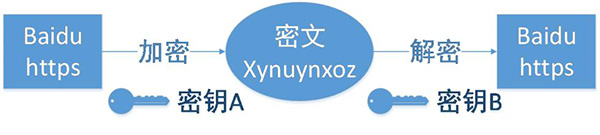
HTTP协议传输的数据都是未加密的,也就是明文的,因此使用HTTP协议传输隐私信息非常不安全,为了保证这些隐私数据能加密传输,于是网景公司设计了SSL(Secure Sockets Layer)协议用于对HTTP协议传输的数据进行加密,从而就诞生了HTTPS。简单来说,HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全。
HTTPS和HTTP的区别主要如下:
1、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
HTTPS的工作原理
我们都知道HTTPS能够加密信息,以免敏感信息被第三方获取,所以很多银行网站或电子邮箱等等安全级别较高的服务都会采用HTTPS协议。
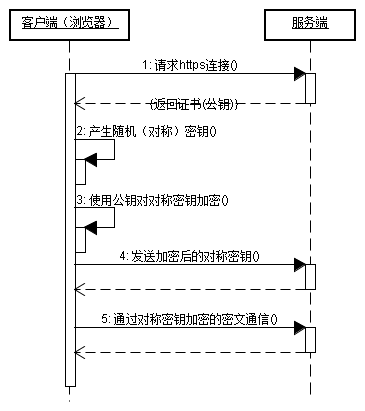
客户端在使用HTTPS方式与Web服务器通信时有以下几个步骤,如图所示。
(1)客户使用https的URL访问Web服务器,要求与Web服务器建立SSL连接。
(2)Web服务器收到客户端请求后,会将网站的证书信息(证书中包含公钥)传送一份给客户端。
(3)客户端的浏览器与Web服务器开始协商SSL连接的安全等级,也就是信息加密的等级。
(4)客户端的浏览器根据双方同意的安全等级,建立会话密钥,然后利用网站的公钥将会话密钥加密,并传送给网站。
(5)Web服务器利用自己的私钥解密出会话密钥。
(6)Web服务器利用会话密钥加密与客户端之间的通信。