蚂蚁集团面试题
1 Dubbo
1.1 服务调用超时问题怎么解决?
1.2 Dubbo支持哪些序列化方式?
- Hessian 序列化:是修改过的 hessian lite,默认启用
- json 序列化:使用 FastJson 库
- java 序列化:JDK 提供的序列化,性能不理想
- dubbo 序列化:未成熟的高效 java 序列化实现,不建议在生产环境使用
1.3 Dubbo和SpringCloud的关系?
| dubbo | springcloud |
|---|---|
| 消费者,生产者,注册中心,管理中心 | 消费者,生产者,注册中心,管理中心,短路器,分布式配置,消息总线,服务追踪 |
| Netty这样的NIO框架,是基于TCP协议传输的,配合以Hession序列化完成RPC | 基于Http协议+rest接口调用远程请求,相对来说,Http请求会有更大的报文,占的带宽也会更多。 |
| dubbo类似组装机,开发相对复杂 | springcloud类似一体机,一站式开发,相对简单 |
1.4 Dubbo的架构设计?一共划分了哪些层?
- 服务接口层(Service):该层是与实际业务逻辑相关的,根据服务提供方和服务消费方的业务设计对应的接口和实现
- 配置层(Config):对外配置接口,以 ServiceConfig 和 ReferenceConfig 为中心
- 服务代理层(Proxy):服务接口透明代理,生成服务的客户端 Stub 和服务器端 Skeleton
- 服务注册层(Registry):封装服务地址的注册与发现,以服务 URL 为中心
- 集群层(Cluster):封装多个提供者的路由及负载均衡,并桥接注册中心,以 Invoker 为中心
- 监控层(Monitor):RPC 调用次数和调用时间监控
- 远程调用层(Protocol):封将 RPC 调用,以 Invocation 和 Result 为中心,扩展接口为 Protocol、Invoker、Exporter
- 信息交换层(Exchange):封装请求响应模式,同步转异步,以 Request 和 Response 为中心
- 网络传输层(Transport):抽象 mina 和 netty 为统一接口,以 Message 为中心
1.5 Dubbo的默认集群容错方案?
-
Failover Cluster,失败自动切换,当出现失败,重试其它服务器。通常用于读操作,但重试会带来更长延迟。
-
Failfast Cluster,快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
-
Failsafe Cluster,失败安全,出现异常时,直接忽略。通常用于写入日志等。
-
Failback Cluster,失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知等。
-
Forking Cluster,并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks 来设置最大并行数。
-
Broadcast Cluster,广播调用所有提供者,逐个调用,任意一台报错则报错。通常用于通知所有提供者更新缓存本地资源信息。
默认 Failover Cluster
1.6 Dubbo使用的是什么通信框架?
1.7 Dubbo的主要应用场景?
1.8 Dubbo服务注册与发现的流程?流程说明。
1.9 Dubbo的集群容错方案有哪些?
1.10 Dubbo的四大组件
1.11 Dubbo在安全机制方面是如何解决的
1.12 Dubbo和SpringCloud的区别?
1.13 Dubbo支持哪些协议,每种协议的应用场景,优缺点?
1.14 Dubbo的核心功能有哪些?
1.15 Dubbo的注册中心集群挂掉,发布者和订阅者之间还能通信么?
1.16 Dubbo集群的负载均衡有哪些策略
1.17 为什么需要服务治理?
1.18 Dubbo超时时间怎样设置?
2 ElasticSearch
2.1 你们公司的ES集群,一个node一般会分配几个分片?
2.2 Elasticsearch是如何实现Master选举的?
2.3 你是如何做写入调优的?
2.4 如何避免脑裂?
2.5 Elasticsearch对于大数据量(上亿量级)的聚合如何实现?
2.6 ES主分片数量可以在后期更改吗?为什么?
2.7 如何监控集群状态?
2.8 ElasticSearch中的副本是什么?
2.9 ES更新数据的执行流程?
2.10 shard里面是什么组成的?
2.11 ElasticSearch中的分析器是什么?
2.12 什么是脑裂?
2.13 客户端在和集群连接时,如何选择特定的节点执行请求的?
2.14 Elasticsearch中的倒排索引是什么?
2.15 什么是索引?索引(名词) 一个索引(index)
2.16 详细描述一下Elasticsearch更新和删除文档的过程
3 JVM
3.1 JVM参数主要有⼏种分类
IBM 微软的 hotpot
3.2 Java中会存在内存泄漏吗,简述一下。
会出现内存泄漏,当垃圾回收器清理内存后,现有内存使用量+申请新增内存>最大使用内存时,会出现内存泄漏
主要场景包括以下两种
- 机器内存不够用
- 内存分配不合理
3.3 Java虚拟机是如何判定两个Java类是相同的?
在新建对象的过程中,需要新通过类加载,而在类加载中通过 双亲委派机制 来判断两个类是否相同
当某个加载器需要加载某个.class 文件时,他首先把这个任务委托过他的上一级加载器,递归这个操作,如果上级的类加载器没有加载,自己才会去加载这个类。
下面是类加载的过程
用于自定义类加载器 –> 系统类加载器 –> 扩展类加载 –> 启动类加载
3.4 Java 中都有哪些引用类型
- __强引用(strongreference)__就是指在程序代码之中普遍存在的,类似“Object obj=new Object()” 这类的引用,只要强引用还存在,垃圾收集器永远不会回收掉被引用的对象实例。
- __软引用(softreference)__是用来描述一些还有用但并非必需的对象。对于软引用关联着的对象, 在系统将要发生内存溢出异常之前,将会把这些对象实例列进回收范围之中进行 第二次回收。如果这次回收还没有足够的内存,才会抛出内存溢出异常。在 JDK 1.2 之后,提供了 SoftReference 类来实现软引用。
- __弱引用(weakreference)__也是用来描述非必需对象的,但是它的强度比软引用更弱一些,被弱 引用关联的对象实例只能生存到下一次垃圾收集发生之前。当垃圾收集器工作时, 无论当前内存是否足够,都会回收掉只被弱引用关联的对象实例。在 JDK 1.2 之 后,提供了 WeakReference 类来实现弱引用。
- __虚引用(phantomreference)__也称为幽灵引用或者幻影引用,它是最弱的一种引用关系。一个对象 实例是否有虚引用的存在,完全不会对其生存时间构成影响,也无法通过虚引用 来取得一个对象实例。为一个对象设置虚引用关联的唯一目的就是能在这个对象 实例被收集器回收时收到一个系统通知。在 JDK 1.2 之后,提供了 PhantomReference 类来实现虚引用
3.5 在 Java 中,对象什么时候可以被垃圾回收?
当对象被判定已经“死去”时,对象可以被垃圾回收,判断对象是否存活可通过以下算法
- __引用计数算法:__通过引用计数器,当被引用+1,当失去引用-1,计数为零的引用被清理
- 可达性分析算法: 通过跟对象作为起始点,从这个节点开始向下搜索,搜索过程所走的路径称为“引用链”,如果某个对象的到 __GC Roots __间没有连接,则说明该对象不能再被引用
3.6 StackOverflow异常有没有遇到过?一般你猜测会在什么情况下被触发?
栈内存溢出。栈内存保存的信息包括:函数地址、函数参数、局部变量等
出现__栈内存溢出的常见原因有2个__:
- 函数调用层次过深,每调用一次,函数的参数、局部变量等信息就压一次栈
- 局部静态变量体积太大
解决办法大致说来也有两种:
- 增加栈内存的数目
- 使用堆内存增加栈内存方法
3.7 堆空间分哪些部分?以及如何设置各个部分?
新生代,老年代
其中新生代,分为 伊甸,to,from 按照 8:1:1 的比例进行分割
3.8 什么是栈帧?栈帧存储了什么?
栈帧是方法运行期最重要的基本数据结构
存储包括:局部变量表,操作数栈,动态连接和方法返回地址
3.9 如何设置参数生成GC日志?
-XX:+PrintGC
3.10 GC 是什么?为什么要有 GC?
Garbage Collection 垃圾回收系统,
java提供的gc功能可以自动检测对象是否超出通过垃圾回收系统,由系统自动触发垃圾回收。java没有提供释放垃圾已分配内存的显示操作方法
3.12 使用过哪些jdk命令,并说明各个的作用是什么
jps:__用于显示__指定系统内所有HotSpot虚拟机进程,并且能显示虚拟机执行主类以及本地虚拟机唯一ID
jstat:__用于__监视虚拟机各种运行状态信息的工具,可以显示本地或者远程的虚拟机进程类装载、内存、GC、JIT等运行数据,在没有GUI图像界面的服务器上,主要就是用它在运行期定位性能问题
jmap:__用于生成堆转储快照(heapdump或dump文件),说白了就是把java堆使用情况快照一份导出来供我们查看,__用来排查问题。
__jhat:__这个就是和jmap搭配使用的,jmap导出来的堆快照文件用jhat 打开分析
jstack:__用于生成虚拟机当前时刻线程快照(threaddump或javacore)。__主要用来定位线程出现长时间停顿的原因,判断死锁啊,死循环的等。通过jstack就可知各线程的调用堆栈情况
__jinfo:__用来查看和调整虚拟机各项参数使用格式
3.13 JVM运行时数据区区域分为哪⼏部分?
堆,方法区,本地方法区,计数器,栈
3.14 是否了解类加载器双亲委派模型机制和破坏双亲委派模型?
在类加载的过程中,会用到双亲委派机制,目的是为了保障.class 文件的唯一性,
他首先把这个任务委托过他的上一级加载器,递归这个操作,如果上级的类加载器没有加载,自己才会去加载这个类。
双亲委派机制中类加载过程:自定义类加载器,程序类加载器,扩展类加载,系统类加载器
破坏双亲委派机制:通过继承 ClassLoader 并重写loadclass
3.15 逃逸分析有几种类型?
方法逃逸:对象的方法被外部方法所引用
线程逃逸:方法被外部线程访问到
3.16 -Xms这些参数的含义是什么?
设置堆内存
3.17 你知道哪几种垃圾收集器,各自的优缺点,重点讲下cms和G1,包括原理,流程,优缺点。
3.18 JVM的内存结构,Eden和Survivor比例是多少?
8:1:1
4 多线程/高并发
4.1 负载平衡的意义什么?
提高硬件的使用率,提升系统的容量
4.2 请说出同步线程及线程调度相关的方法?
线程调度相关方法:
yield():线程让步,暂停当前正在执行的线程,把执行机会让给优先级相同或更高的线程。若队列中没有同优先级的线程,忽略此方法。
join() :当某个程序执行流中调用其他线程的 join() 方法时,调用线程将被阻塞,直到 join() 方法加入的 join 线程执行完为止,低优先级的线程也可以获得执行
sleep(long millis)(毫秒) : 令当前活动线程在指定时间段内放弃对CPU控制,使其他线程有机会被执行,时间到后重排队。
isAlive():判断线程是否还活着
线程同步:
synchronized 同步代码快,同步方法
4.3 关于epoll和select的区别,哪些说法 是正确的?(多选)
A. epoll 和 select 都是 I/O 多路复用的技术,都可以实现同时监听 多个I/O事件的状态。 B. epoll 相比 select 效率更高,主要是基于其操作系统支持的 I/O 事件通知机制,而select是基于轮询机制。 C. epoll支持水平触发和边沿触发两种模式。 D. select能并行支持I/O比较小,且无法修改。
4.4 启动一个线程是调用run()方法还是start()方法?
run() 方法,start() 中饱含 run() 方法
4.5 如何确保N个线程可以访问N个资源同时又不导致死锁?
多线程产生死锁需要四个条件,分别是互斥性,保持和请求,不可剥夺性还有要形成闭环,这四个条件缺一不可,只要破坏了其中一个条件就可以破坏死锁,其中最简单的方法就是线程都是以同样的顺序加锁和释放锁,也就是破坏了第四个条件
4.6 编写多线程程序的几种实现方式(换个问法:创建多线程的方式)?
继承 Thread 重写run函数
实现Runnable 重写run函数
实现Callable接口,重写call函数
4.7 线程和进程的区别?
线程是进程执行程序的最小单元
进程:一个程序一个进程
线程:一个进程包含多个线程
4.8 什么是线程池,有哪些常用线程池?
若干个线程放入同一个容器中,使用的时候从池中获取而不用自行创建,使用完毕不需 要销毁线程而是放回池中, 从而减少创建和销毁线程对象的开销
常用线程池:
__newSingleThreadExecutor: __创建一个单线程的线程池, 此线程池保证所有任务的执行顺序按照任务的 提交顺序执行。
__newFixedThreadPool: __创建固定大小的线程池, 每次提交一个任务就创建一个线程, 直到线程达到线 程池的最大大小。
newCachedThreadPool: 创建一个可缓存的线程池, 此线程池不会对线程池大小做限制, 线程池大小 完全依赖于操作系统(或者说 JVM) 能够创建的最大线程大小。
__newScheduledThreadPool: __创建一个大小无限的线程池, 此线程池支持定时以及周期性执行任务的需 求。
__newSingleThreadExecutor: __创建一个单线程的线程池。 此线程池支持定时以及周期性执行任务的需 求
4.9 什么是死锁?
是指多个进程在运行过程中因争夺资源而造成的一种僵局,当进程处于这种僵持状态时,若无外力作用,它们都将无法再向前推进
多线程产生死锁需要四个条件,分别是互斥性,保持和请求,不可剥夺性还有要形成闭环,这四个条件缺一不可
4.10 怎么保证缓存和数据库数据的一致性?
- Cache aside (旁路缓存 )
这是最常用最常用的pattern了。其具体逻辑如下:
- 失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
- 命中:应用程序从cache中取数据,取到后返回。
- 更新:先把数据存到数据库中,成功后,再让缓存失效。
注意,我们的更新是先更新数据库,成功后,让缓存失效。那么,这种方式是否可以没有文章前面提到过的那个问题呢?我们可以脑补一下。
一个是查询操作,一个是更新操作的并发,首先,没有了删除cache数据的操作了,而是先更新了数据库中的数据,此时,缓存依然有效,所以,并发的查询操作拿的是没有更新的数据,但是,更新操作马上让缓存的失效了,后续的查询操作再把数据从数据库中拉出来。而不会像文章开头的那个逻辑产生的问题,后续的查询操作一直都在取老的数据。
这是标准的design pattern,包括Facebook的论文《Scaling Memcache at Facebook》也使用了这个策略。为什么不是写完数据库后更新缓存?你可以看一下Quora上的这个问答《Why does Facebook use delete to remove the key-value pair in Memcached instead of updating the Memcached during write request to the backend?》,主要是怕两个并发的写操作导致脏数据。
那么,是不是Cache Aside这个就不会有并发问题了?不是的,比如,一个是读操作,但是没有命中缓存,然后就到数据库中取数据,此时来了一个写操作,写完数据库后,让缓存失效,然后,之前的那个读操作再把老的数据放进去,所以,会造成脏数据。
但,这个case理论上会出现,不过,实际上出现的概率可能非常低,因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。
所以,这也就是Quora上的那个答案里说的,要么通过2PC或是Paxos协议保证一致性,要么就是拼命的降低并发时脏数据的概率,而Facebook使用了这个降低概率的玩法,因为2PC太慢,而Paxos太复杂。当然,最好还是为缓存设置上过期时间。
5 消息中间件
5.1 消费者获取消息有几种模式?
推送模式: consumer把轮询过程封装了,并注册到MessageListener监听器中,对于offset进行自动保存。取到消息后,唤醒MessageListener的consumeMessage()来消费,这种触发方法才会被调用的方式对用户而言感觉就像是被推送过来。
__拉取模式:__这种方法非常少用,它在取消息的过程中需要用户自己手动操作。首先在要消费的Topic中拿到MessageQueue的集合,遍历MessageQueue集合,然后针对每一个MessageQueue批量取消息,每取完一次,记录该队列下一次要取的开始offset,直到取完一整个MessageQueue,再换另一个MessageQueue。
5.2 RocketMQ的特点有哪些?
- 灵活可扩展性 RocketMQ 天然支持集群,其核心四组件(Name Server、Broker、Producer、Consumer)每一个都可以在没有单点故障的情况下进行水平扩展。
- 海量消息堆积能力 RocketMQ 采用零拷贝原理实现超大的消息的堆积能力,据说单机已可以支持亿级消息堆积,而且在堆积了这么多消息后依然保持写入低延迟。
- 支持顺序消息 可以保证消息消费者按照消息发送的顺序对消息进行消费。顺序消息分为全局有序和局部有序,一般推荐使用局部有序,即生产者通过将某一类消息按顺序发送至同一个队列来实现。
- 多种消息过滤方式 消息过滤分为在服务器端过滤和在消费端过滤。服务器端过滤时可以按照消息消费者的要求做过滤,优点是减少不必要消息传输,缺点是增加了消息服务器的负担,实现相对复杂。消费端过滤则完全由具体应用自定义实现,这种方式更加灵活,缺点是很多无用的消息会传输给消息消费者。
- 支持事务消息 RocketMQ 除了支持普通消息,顺序消息之外还支持事务消息,这个特性对于分布式事务来说提供了又一种解决思路。
- 回溯消费 回溯消费是指消费者已经消费成功的消息,由于业务上需求需要重新消费,RocketMQ 支持按照时间回溯消费,时间维度精确到毫秒,可以向前回溯,也可以向后回溯
5.3 kafka 同时设置了 7 天和 10G 清除数据,到第五天的时候消息达到了 10G,这个时候 kafka将如何处理?
这个时候 kafka 会执行数据清除工作,时间和大小不论那个满足条件,都会清空数据。
5.4 为何需要Kafka集群
提高信息吞吐量,
5.5 Kafka 数据存储设计
5.6 Kafka如何判断一个节点是否存活?
5.7 kafka消息发送的可靠性机制有几种 5.8 请详细说一下推送模式和拉取模式。 5.9 Kafka 与传统消息系统之间有三个关键区别
5.10 RocketMQ 由哪些角色组成?
生产者(Producer):负责产生消息,生产者向消息服务器发送由业务应用程序系统生成的消息。
消费者(Consumer):负责消费消息,消费者从消息服务器拉取信息并将其输入用户应用程序。
消息服务器(Broker):是消息存储中心,主要作用是接收来自 Producer 的消息并存储, Consumer 从这里取得消息。
名称服务器(NameServer):用来保存 Broker 相关 Topic 等元信息并给 Producer ,提供 Consumer 查找 Broker 信息。
5.12 Kafka的消费者如何消费数据 5.13 Kafka的优点 5.14 Kafka 的设计是什么样的呢? 5.15 说说你对Consumer的了解? 5.16 Kafka新建的分区会在哪个目录下创建
5.17 说一下Kafka消费者消费过程
消息的消费模型有两种:推送模型(push)和拉取模型(pull)
推送模型(push):
基于推送模型(push)的消息系统,由消息代理记录消费者的消费状态,消息代理在将消息推送到消费者后,标记这条消息为已消费,但这种方式无法很好地保证消息被处理,比如,消息代理把消息发送出去后,当消费进程挂掉或者由于网络原因没有收到这条消息时,就有可能造成消息丢失(因为消息代理已经把这条消息标记为已消费了,但实际上这条消息并没有被实际处理),如果要保证消息被处理,消息代理发送完消息后,要设置状态为“已发送”,只有收到消费者的确认请求后才更新为“已消费”,这就需要消息代理中记录所有的消费状态,这种做法显然是不可取的
拉取模型(pull):
Kafka采用拉取模型,由消费者自己记录消费状态,每个消费者互相独立地顺序读取每个分区的消息,有两个消费者(不同消费者组)拉取同一个主题的消息,消费者A的消费进度是3,消费者B的消费进度是6,消费者拉取的最大上限通过最高水位(watermark)控制,生产者最新写入的消息如果还没有达到备份数量,对消费者是不可见的,这种由消费者控制偏移量的优点是:消费者可以按照任意的顺序消费消息,比如:消费者可以重置到旧的偏移量,重新处理之前已经消费过的消息;或者直接跳到最近的位置,从当前的时刻开始消费
5.18 介绍下Kafka
kafka是一个 分布式的, __可分区__的, __可备份__的日志提交服务,它使用独特的设计实现了一个消息系统的功能。
5.19 什么情况会导致Kafka运行变慢?
-
cpu 性能瓶颈
-
磁盘读写瓶颈
-
网络瓶颈
5.20 kafka 可以脱离 zookeeper 单独使用吗?为什么?
kafka 不能脱离 zookeeper 单独使用,
因为 kafka 使用 zookeeper 管理和协调 kafka 的节点服务器。
5.21 使用 kafka 集群需要注意什么?
-
集群的数量不是越多越好,最好不要超过 7 个,
-
因为节点越多,消息复制需要的时间就越长,整个群组的吞吐量就越低。
-
集群数量最好是单数,因为超过一半故障集群就不能用了,设置为单数容错率更高。
5.22 为什么使用消息队列呢(即优势所在)?
-
实现解耦;举个简单例子,快递小哥手上有很多快递需要配送,若一一通知收件人,估计快递小哥要疯掉,有了丰巢快递柜后,快递小哥可以集中将快递放到快递柜子里面,后面只需发送短信给收件人即可,这样以来快递柜子就充当了消息中间件,实现了解耦,两个人互不耽误。
-
实现冗余备份;当快递小哥兴致冲冲的拉来一车快递后,正准备投递到丰巢快递柜子,但不幸的是蜂巢快递柜子坏了,无法投递快递,快递小哥也没招,只能老老实实的去下一个丰巢快递柜子投递快递,若快递柜子又坏了,快递小哥还可以去下一个快递柜子,如此一来,实现了消息队列的冗余备份,保证你的快递不被丢失;
-
异步;如果楼下有你的快递,快递小哥需要一直在楼下等你取走快递后,快递小哥才能进行下一个快递的派单,这样以来快递小哥的效率极其低下,而有了快递柜子后,快递小哥只需要将你的快递放到柜子,然后给你发送取件短信即可,这样以来效率大大提高,这正体现了中间件的好处;
-
削峰;当双十一来临后,快递小哥的业务量倍增,这样快递小哥直接怀疑人生,自从各种丰巢、菜鸟驿站等各种消息中间件后,快递小哥没那么繁忙了,这正是体现了消息中间件的削峰作用。
5.23 Kafka数据丢失问题解决方案?
首先对kafka进行限速, 其次启用重试机制,重试间隔时间设置长一些,最后Kafka设置 acks=all,即需要相应的所有处于ISR的分区都确认收到该消息后,才算发送成功。
5.24 Kafka数据重复问题解决方案?
把kafka消费者的配置 enable.auto.commit设为false, 禁止kafka自动提交offset,从而使用spring-kafka提供的offset提交策略。spring-kafka中的offset提交策略可以保证一批消息数据没有完成消费的情况下,也能提交offset,从而避免了提交失败而导致永远重复消费的问题。
5.24 kafka消息是否会丢失?为什么?
acks参数用于控制producer生产消息的持久性(durability)。对producer而言,kafka在乎的是已提交消息的持久性。一旦消息被提交成功,那么只要有任何一个保存了消息的副本存活,这条消息被视为不会丢失的。 acks有3个值:0,1,all(-1)
- acks=0:producer不进行消息接收是否成功的确认。
- acks=1(默认):当Leader副本接收成功后,返回接收成功确认信息;
- acks=all或者-1:当Leader和Follower副本都接收成功后,返回接收成功确认信息。
从上面acks的设置中可以知道,当acks=0时,一旦发生宕机,肯定会发生消息丢失的情况;acks=1时,只要leader broker一直存活,kafka能够保证消息不丢失;acks=all时,只要还有副本存活,那么这条消息肯定不会丢失。
Autowired的使用:推荐使用构造函数进行注入
近期看同事用idea开发的代码,发现在使用@Autowired的时候,大多使用构造函数进行注入。
以前自己在写代码的时候都是直接在变量上进行注入,也没注意过,查了些资料,发现如果直接在变量上进行注入,那么可能会造成NPE。
构造函数注入的方式:
public class TestController {
private final TestService testService;
@Autowired
public TestController(TestService testService) {
this.testService = testService;
}
…
}
变量注入的方式:
public class TestController {
@Autowired
private TestService testService;
…
}
那么为什么变量注入的方式可能会造成NPE?如下:
public class TestController {
@Autowired
private TestService testService;
private String testname;
public TestController(){
this.testname = testService.getTestName();
}
}
这段代码执行时会报NPE。
该类的构造函数中的变量值是通过TestService实例来调用TestService类中的方法获得,而Java类会先执行构造函数,然后在通过@Autowired注入实例,因此在执行构造函数的时候就会报错。
解决方案就是采用构造函数的注入方式,如下:
public class TestController {
private TestService testService;
private String testname;
@Autowired
public TestController(TestService testService){
this.testService = testService;
this.testname = testService.getTestName();
}
}
上面的方法中没有加入final来修饰,但是spring官方文档上是建议将成员变量加上final类型的,这是为什么呢?
有网友解释:
1.spring配置默认的bean的scope是singleton,可以通过设置bean的scope属性为prototype来声明该对象为动态创建。但是,如果你的service本身是singleton,注入只执行一次。
2.@Autowired本身就是单例模式,只会在程序启动时执行一次,即使不定义final也不会初始化第二次,所以这个final是没有意义的吧。
无论是spring的bean的scope是单例还是多例,成员变量加上了final后,只能被赋值一次,赋值后值不再改变。
注意:
1.如果使用变量注入的话,可能回导致循环依赖,即A里面注入B,B里面又注入A。
2.在代码中发现构造方法中注入了很多依赖,显得很臃肿,对于这个问题,说明类中有太多的责任,违反了类的单一性职责原则,这时候需要考虑使用单一职责原则进行代码重构
sql语句优化
关系型数据库本身比较容易成为系统瓶颈,单机存储容量、连接数、处理能力都有限。当单表的数据量达到1000W或100G以后,由于查询维度较多,即使添加从库、优化索引,做很多操作时性能仍下降严重。此时就要考虑对其进行切分了,切分的目的就在于减少数据库的负担,缩短查询时间。
数据库分布式核心内容无非就是数据切分(Sharding),以及切分后对数据的定位、整合。数据切分就是将数据分散存储到多个数据库中,使得单一数据库中的数据量变小,通过扩充主机的数量缓解单一数据库的性能问题,从而达到提升数据库操作性能的目的。
数据切分根据其切分类型,可以分为两种方式:垂直(纵向)切分和水平(横向)切分
1、垂直(纵向)切分
垂直切分常见有垂直分库和垂直分表两种。
垂直分库就是根据业务耦合性,将关联度低的不同表存储在不同的数据库。做法与大系统拆分为多个小系统类似,按业务分类进行独立划分。与”微服务治理”的做法相似,每个微服务使用单独的一个数据库。如图:
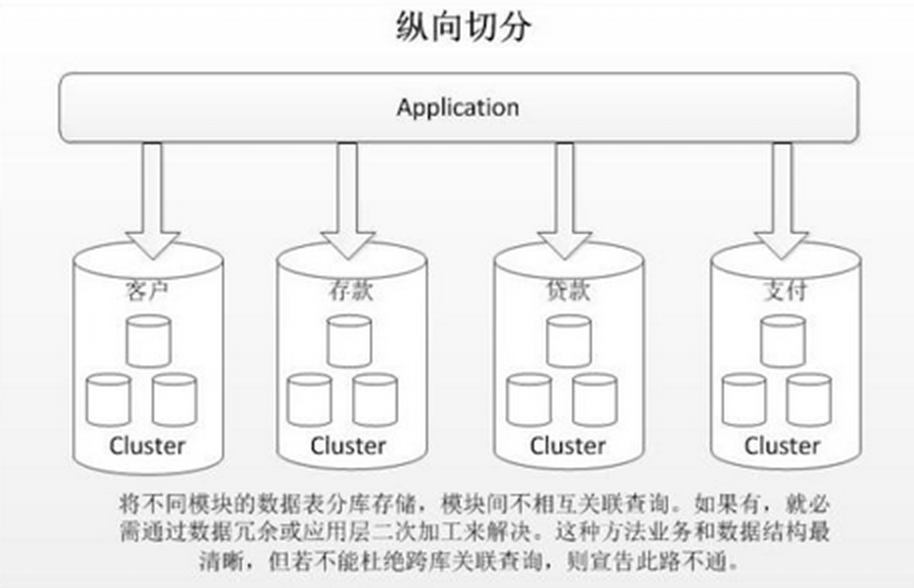
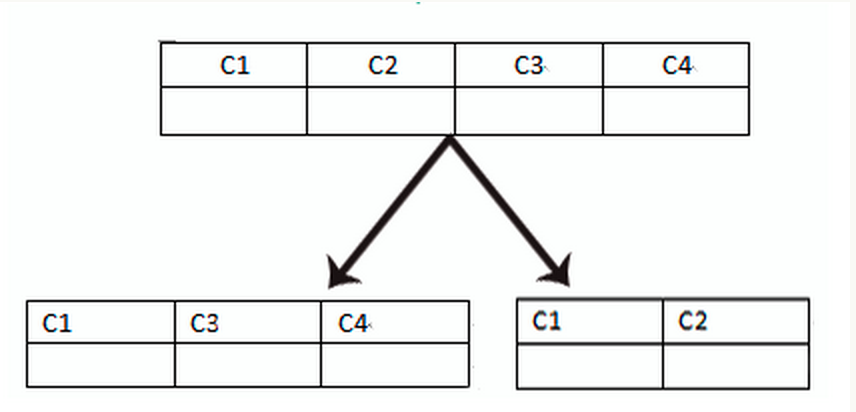
垂直分表是基于数据库中的”列”进行,某个表字段较多,可以新建一张扩展表,将不经常用或字段长度较大的字段拆分出去到扩展表中。在字段很多的情况下(例如一个大表有100多个字段),通过”大表拆小表”,更便于开发与维护,也能避免跨页问题,MySQL底层是通过数据页存储的,一条记录占用空间过大会导致跨页,造成额外的性能开销。另外数据库以行为单位将数据加载到内存中,这样表中字段长度较短且访问频率较高,内存能加载更多的数据,命中率更高,减少了磁盘IO,从而提升了数据库性能。
垂直切分的优点:
- 解决业务系统层面的耦合,业务清晰
- 与微服务的治理类似,也能对不同业务的数据进行分级管理、维护、监控、扩展等
- 高并发场景下,垂直切分一定程度的提升IO、数据库连接数、单机硬件资源的瓶颈
缺点:
- 部分表无法join,只能通过接口聚合方式解决,提升了开发的复杂度
- 分布式事务处理复杂
- 依然存在单表数据量过大的问题(需要水平切分)
2、水平(横向)切分
当一个应用难以再细粒度的垂直切分,或切分后数据量行数巨大,存在单库读写、存储性能瓶颈,这时候就需要进行水平切分了。
水平切分分为库内分表和分库分表,是根据表内数据内在的逻辑关系,将同一个表按不同的条件分散到多个数据库或多个表中,每个表中只包含一部分数据,从而使得单个表的数据量变小,达到分布式的效果。如图所示:

库内分表只解决了单一表数据量过大的问题,但没有将表分布到不同机器的库上,因此对于减轻MySQL数据库的压力来说,帮助不是很大,大家还是竞争同一个物理机的CPU、内存、网络IO,最好通过分库分表来解决。
水平切分的优点:
- 不存在单库数据量过大、高并发的性能瓶颈,提升系统稳定性和负载能力
- 应用端改造较小,不需要拆分业务模块
缺点:
- 跨分片的事务一致性难以保证
- 跨库的join关联查询性能较差
- 数据多次扩展难度和维护量极大
水平切分后同一张表会出现在多个数据库/表中,每个库/表的内容不同。几种典型的数据分片规则为:
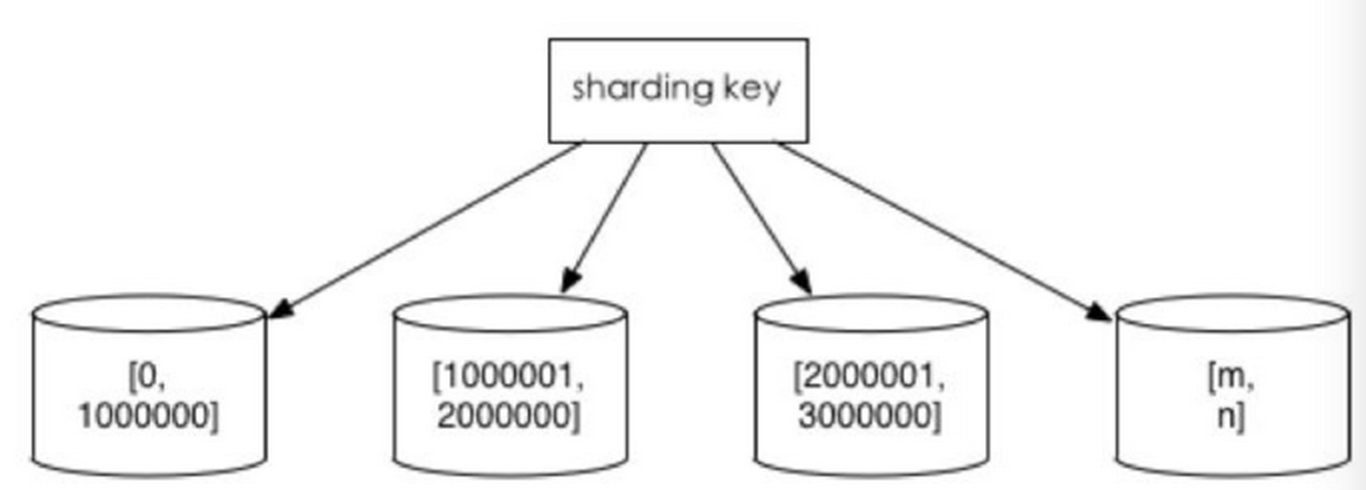
1、根据数值范围
按照时间区间或ID区间来切分。例如:按日期将不同月甚至是日的数据分散到不同的库中;将userId为1~9999的记录分到第一个库,10000~20000的分到第二个库,以此类推。某种意义上,某些系统中使用的”冷热数据分离”,将一些使用较少的历史数据迁移到其他库中,业务功能上只提供热点数据的查询,也是类似的实践。
这样的优点在于:
- 单表大小可控
- 天然便于水平扩展,后期如果想对整个分片集群扩容时,只需要添加节点即可,无需对其他分片的数据进行迁移
- 使用分片字段进行范围查找时,连续分片可快速定位分片进行快速查询,有效避免跨分片查询的问题。
缺点:
- 热点数据成为性能瓶颈。连续分片可能存在数据热点,例如按时间字段分片,有些分片存储最近时间段内的数据,可能会被频繁的读写,而有些分片存储的历史数据,则很少被查询
2、根据数值取模
一般采用hash取模mod的切分方式,例如:将 Customer 表根据 cusno 字段切分到4个库中,余数为0的放到第一个库,余数为1的放到第二个库,以此类推。这样同一个用户的数据会分散到同一个库中,如果查询条件带有cusno字段,则可明确定位到相应库去查询。
优点:
- 数据分片相对比较均匀,不容易出现热点和并发访问的瓶颈
缺点:
- 后期分片集群扩容时,需要迁移旧的数据(使用一致性hash算法能较好的避免这个问题)
- 容易面临跨分片查询的复杂问题。比如上例中,如果频繁用到的查询条件中不带cusno时,将会导致无法定位数据库,从而需要同时向4个库发起查询,再在内存中合并数据,取最小集返回给应用,分库反而成为拖累。

二. 分库分表带来的问题
分库分表能有效的环节单机和单库带来的性能瓶颈和压力,突破网络IO、硬件资源、连接数的瓶颈,同时也带来了一些问题。下面将描述这些技术挑战以及对应的解决思路。
1、事务一致性问题
分布式事务
当更新内容同时分布在不同库中,不可避免会带来跨库事务问题。跨分片事务也是分布式事务,没有简单的方案,一般可使用”XA协议”和”两阶段提交”处理。
分布式事务能最大限度保证了数据库操作的原子性。但在提交事务时需要协调多个节点,推后了提交事务的时间点,延长了事务的执行时间。导致事务在访问共享资源时发生冲突或死锁的概率增高。随着数据库节点的增多,这种趋势会越来越严重,从而成为系统在数据库层面上水平扩展的枷锁。
最终一致性
对于那些性能要求很高,但对一致性要求不高的系统,往往不苛求系统的实时一致性,只要在允许的时间段内达到最终一致性即可,可采用事务补偿的方式。与事务在执行中发生错误后立即回滚的方式不同,事务补偿是一种事后检查补救的措施,一些常见的实现方法有:对数据进行对账检查,基于日志进行对比,定期同标准数据来源进行同步等等。事务补偿还要结合业务系统来考虑。
2、跨节点关联查询 join 问题
切分之前,系统中很多列表和详情页所需的数据可以通过sql join来完成。而切分之后,数据可能分布在不同的节点上,此时join带来的问题就比较麻烦了,考虑到性能,尽量避免使用join查询。
解决这个问题的一些方法:
1)全局表
全局表,也可看做是”数据字典表”,就是系统中所有模块都可能依赖的一些表,为了避免跨库join查询,可以将这类表在每个数据库中都保存一份。这些数据通常很少会进行修改,所以也不担心一致性的问题。
2)字段冗余
一种典型的反范式设计,利用空间换时间,为了性能而避免join查询。例如:订单表保存userId时候,也将userName冗余保存一份,这样查询订单详情时就不需要再去查询”买家user表”了。
但这种方法适用场景也有限,比较适用于依赖字段比较少的情况。而冗余字段的数据一致性也较难保证,就像上面订单表的例子,买家修改了userName后,是否需要在历史订单中同步更新呢?这也要结合实际业务场景进行考虑。
3)数据组装
在系统层面,分两次查询,第一次查询的结果集中找出关联数据id,然后根据id发起第二次请求得到关联数据。最后将获得到的数据进行字段拼装。
4)ER分片
关系型数据库中,如果可以先确定表之间的关联关系,并将那些存在关联关系的表记录存放在同一个分片上,那么就能较好的避免跨分片join问题。在1:1或1:n的情况下,通常按照主表的ID主键切分。如下图所示:
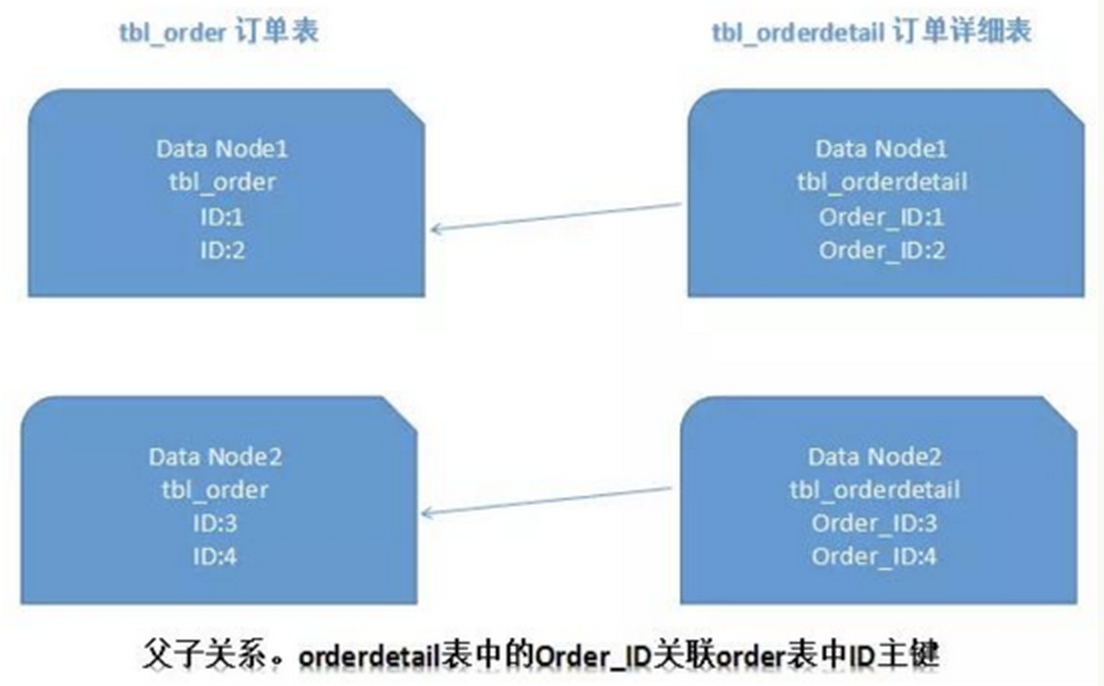
这样一来,Data Node1上面的order订单表与orderdetail订单详情表就可以通过orderId进行局部的关联查询了,Data Node2上也一样。
3、跨节点分页、排序、函数问题
跨节点多库进行查询时,会出现limit分页、order by排序等问题。分页需要按照指定字段进行排序,当排序字段就是分片字段时,通过分片规则就比较容易定位到指定的分片;当排序字段非分片字段时,就变得比较复杂了。需要先在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序,最终返回给用户。如图所示:
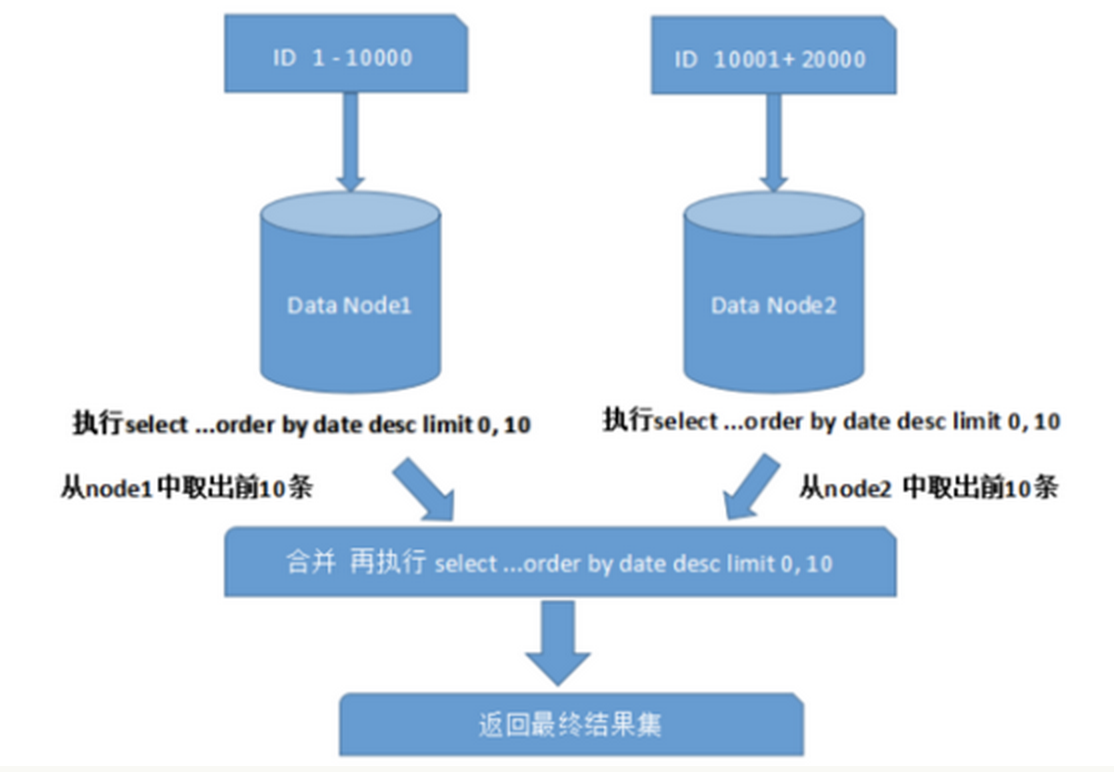
上图中只是取第一页的数据,对性能影响还不是很大。但是如果取得页数很大,情况则变得复杂很多,因为各分片节点中的数据可能是随机的,为了排序的准确性,需要将所有节点的前N页数据都排序好做合并,最后再进行整体的排序,这样的操作时很耗费CPU和内存资源的,所以页数越大,系统的性能也会越差。
在使用Max、Min、Sum、Count之类的函数进行计算的时候,也需要先在每个分片上执行相应的函数,然后将各个分片的结果集进行汇总和再次计算,最终将结果返回。如图所示:
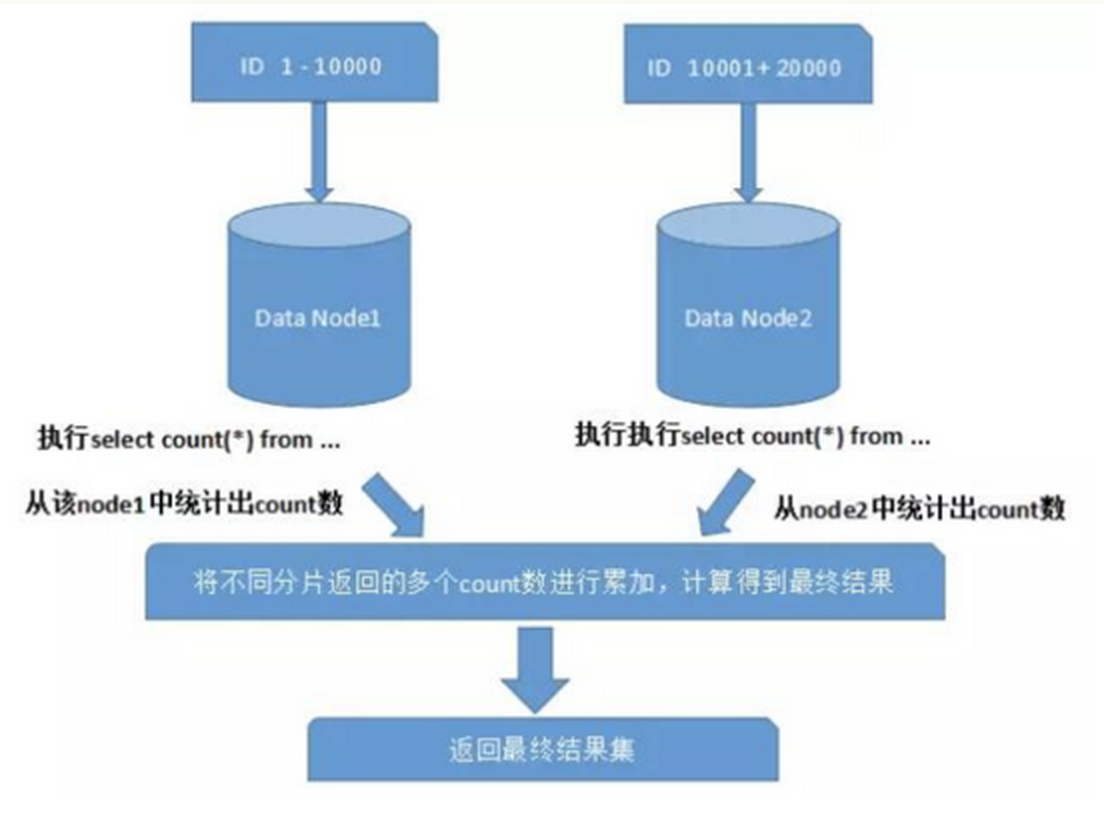
###
4、全局主键避重问题
在分库分表环境中,由于表中数据同时存在不同数据库中,主键值平时使用的自增长将无用武之地,某个分区数据库自生成的ID无法保证全局唯一。因此需要单独设计全局主键,以避免跨库主键重复问题。有一些常见的主键生成策略:
1)UUID
UUID标准形式包含32个16进制数字,分为5段,形式为8-4-4-4-12的36个字符,例如:550e8400-e29b-41d4-a716-446655440000
UUID是主键是最简单的方案,本地生成,性能高,没有网络耗时。但缺点也很明显,由于UUID非常长,会占用大量的存储空间;另外,作为主键建立索引和基于索引进行查询时都会存在性能问题,在InnoDB下,UUID的无序性会引起数据位置频繁变动,导致分页。
2)结合数据库维护主键ID表
在数据库中建立 sequence 表:
CREATE TABLE `sequence` (
`id` bigint(20) unsigned NOT NULL auto_increment,
`stub` char(1) NOT NULL default '',
PRIMARY KEY (`id`),
UNIQUE KEY `stub` (`stub`)
) ENGINE=MyISAM;
stub字段设置为唯一索引,同一stub值在sequence表中只有一条记录,可以同时为多张表生成全局ID。sequence表的内容,如下所示:
+-------------------+------+
| id | stub |
+-------------------+------+
| 72157623227190423 | a |
+-------------------+------+
使用 MyISAM 存储引擎而不是 InnoDB,以获取更高的性能。MyISAM使用的是表级别的锁,对表的读写是串行的,所以不用担心在并发时两次读取同一个ID值。
当需要全局唯一的64位ID时,执行:
REPLACE INTO sequence (stub) VALUES ('a');
SELECT LAST_INSERT_ID();
这两条语句是Connection级别的,select last_insert_id() 必须与 replace into 在同一数据库连接下才能得到刚刚插入的新ID。
使用replace into代替insert into好处是避免了表行数过大,不需要另外定期清理。
此方案较为简单,但缺点也明显:存在单点问题,强依赖DB,当DB异常时,整个系统都不可用。配置主从可以增加可用性,但当主库挂了,主从切换时,数据一致性在特殊情况下难以保证。另外性能瓶颈限制在单台MySQL的读写性能。
flickr团队使用的一种主键生成策略,与上面的sequence表方案类似,但更好的解决了单点和性能瓶颈的问题。
这一方案的整体思想是:建立2个以上的全局ID生成的服务器,每个服务器上只部署一个数据库,每个库有一张sequence表用于记录当前全局ID。表中ID增长的步长是库的数量,起始值依次错开,这样能将ID的生成散列到各个数据库上。如下图所示:
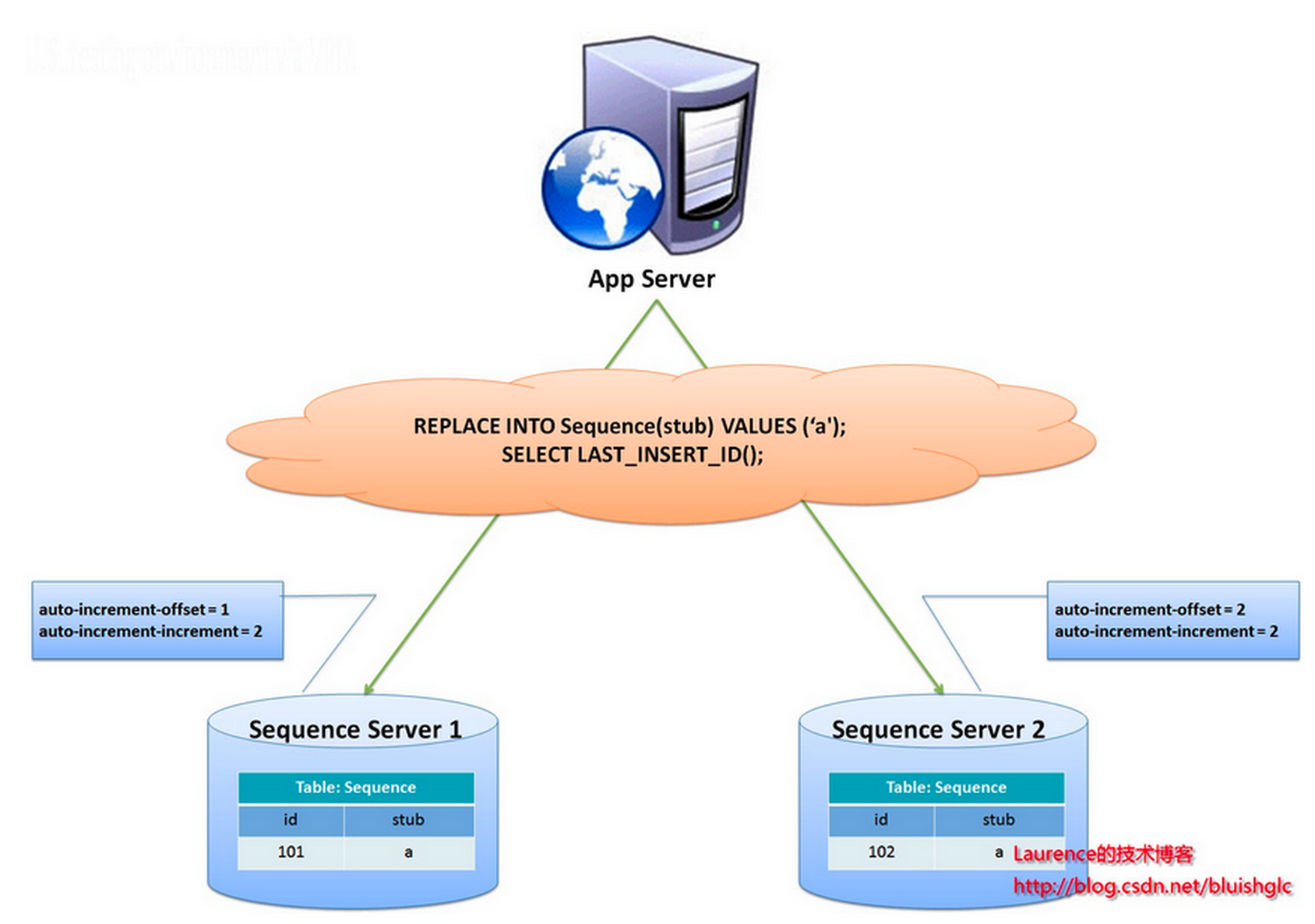
由两个数据库服务器生成ID,设置不同的auto_increment值。第一台sequence的起始值为1,每次步长增长2,另一台的sequence起始值为2,每次步长增长也是2。结果第一台生成的ID都是奇数(1, 3, 5, 7 …),第二台生成的ID都是偶数(2, 4, 6, 8 …)。
这种方案将生成ID的压力均匀分布在两台机器上。同时提供了系统容错,第一台出现了错误,可以自动切换到第二台机器上获取ID。但有以下几个缺点:系统添加机器,水平扩展时较复杂;每次获取ID都要读写一次DB,DB的压力还是很大,只能靠堆机器来提升性能。
可以基于flickr的方案继续优化,使用批量的方式降低数据库的写压力,每次获取一段区间的ID号段,用完之后再去数据库获取,可以大大减轻数据库的压力。如下图所示:
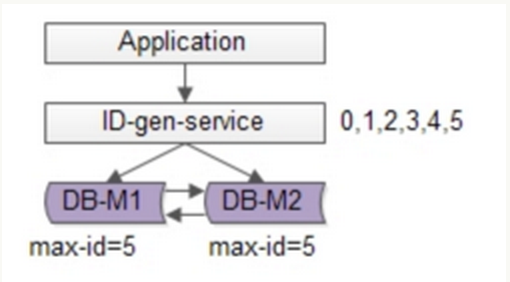
还是使用两台DB保证可用性,数据库中只存储当前的最大ID。ID生成服务每次批量拉取6个ID,先将max_id修改为5,当应用访问ID生成服务时,就不需要访问数据库,从号段缓存中依次派发0~5的ID。当这些ID发完后,再将max_id修改为11,下次就能派发6~11的ID。于是,数据库的压力降低为原来的1/6。
3)Snowflake分布式自增ID算法
Twitter的snowflake算法解决了分布式系统生成全局ID的需求,生成64位的Long型数字,组成部分:
- 第一位未使用
- 接下来41位是毫秒级时间,41位的长度可以表示69年的时间
- 5位datacenterId,5位workerId。10位的长度最多支持部署1024个节点
- 最后12位是毫秒内的计数,12位的计数顺序号支持每个节点每毫秒产生4096个ID序列

这样的好处是:毫秒数在高位,生成的ID整体上按时间趋势递增;不依赖第三方系统,稳定性和效率较高,理论上QPS约为409.6w/s(1000*2^12),并且整个分布式系统内不会产生ID碰撞;可根据自身业务灵活分配bit位。
不足就在于:强依赖机器时钟,如果时钟回拨,则可能导致生成ID重复。
综上
结合数据库和snowflake的唯一ID方案,可以参考业界较为成熟的解法:Leaf——美团点评分布式ID生成系统,并考虑到了高可用、容灾、分布式下时钟等问题。
5、数据迁移、扩容问题
当业务高速发展,面临性能和存储的瓶颈时,才会考虑分片设计,此时就不可避免的需要考虑历史数据迁移的问题。一般做法是先读出历史数据,然后按指定的分片规则再将数据写入到各个分片节点中。此外还需要根据当前的数据量和QPS,以及业务发展的速度,进行容量规划,推算出大概需要多少分片(一般建议单个分片上的单表数据量不超过1000W)
如果采用数值范围分片,只需要添加节点就可以进行扩容了,不需要对分片数据迁移。如果采用的是数值取模分片,则考虑后期的扩容问题就相对比较麻烦。
三. 什么时候考虑切分
下面讲述一下什么时候需要考虑做数据切分。
1、能不切分尽量不要切分
并不是所有表都需要进行切分,主要还是看数据的增长速度。切分后会在某种程度上提升业务的复杂度,数据库除了承载数据的存储和查询外,协助业务更好的实现需求也是其重要工作之一。
不到万不得已不用轻易使用分库分表这个大招,避免”过度设计”和”过早优化”。分库分表之前,不要为分而分,先尽力去做力所能及的事情,例如:升级硬件、升级网络、读写分离、索引优化等等。当数据量达到单表的瓶颈时候,再考虑分库分表。
2、数据量过大,正常运维影响业务访问
这里说的运维,指:
1)对数据库备份,如果单表太大,备份时需要大量的磁盘IO和网络IO。例如1T的数据,网络传输占50MB时候,需要20000秒才能传输完毕,整个过程的风险都是比较高的
2)对一个很大的表进行DDL修改时,MySQL会锁住全表,这个时间会很长,这段时间业务不能访问此表,影响很大。如果使用pt-online-schema-change,使用过程中会创建触发器和影子表,也需要很长的时间。在此操作过程中,都算为风险时间。将数据表拆分,总量减少,有助于降低这个风险。
3)大表会经常访问与更新,就更有可能出现锁等待。将数据切分,用空间换时间,变相降低访问压力
3、随着业务发展,需要对某些字段垂直拆分
举个例子,假如项目一开始设计的用户表如下:
id bigint #用户的ID
name varchar #用户的名字
last_login_time datetime #最近登录时间
personal_info text #私人信息
..... #其他信息字段
在项目初始阶段,这种设计是满足简单的业务需求的,也方便快速迭代开发。而当业务快速发展时,用户量从10w激增到10亿,用户非常的活跃,每次登录会更新 last_login_name 字段,使得 user 表被不断update,压力很大。而其他字段:id, name, personal_info 是不变的或很少更新的,此时在业务角度,就要将 last_login_time 拆分出去,新建一个 user_time 表。
personal_info 属性是更新和查询频率较低的,并且text字段占据了太多的空间。这时候,就要对此垂直拆分出 user_ext 表了。
4、数据量快速增长
随着业务的快速发展,单表中的数据量会持续增长,当性能接近瓶颈时,就需要考虑水平切分,做分库分表了。此时一定要选择合适的切分规则,提前预估好数据容量
5、安全性和可用性
鸡蛋不要放在一个篮子里。在业务层面上垂直切分,将不相关的业务的数据库分隔,因为每个业务的数据量、访问量都不同,不能因为一个业务把数据库搞挂而牵连到其他业务。利用水平切分,当一个数据库出现问题时,不会影响到100%的用户,每个库只承担业务的一部分数据,这样整体的可用性就能提高。
四. 案例分析
1、用户中心业务场景
用户中心是一个非常常见的业务,主要提供用户注册、登录、查询/修改等功能,其核心表为:
User(uid, login_name, passwd, sex, age, nickname)
uid为用户ID, 主键
login_name, passwd, sex, age, nickname, 用户属性
任何脱离业务的架构设计都是耍流氓,在进行分库分表前,需要对业务场景需求进行梳理:
- 用户侧:前台访问,访问量较大,需要保证高可用和高一致性。主要有两类需求:
- 用户登录:通过login_name/phone/email查询用户信息,1%请求属于这种类型
- 用户信息查询:登录之后,通过uid来查询用户信息,99%请求属这种类型
- 运营侧:后台访问,支持运营需求,按照年龄、性别、登陆时间、注册时间等进行分页的查询。是内部系统,访问量较低,对可用性、一致性的要求不高。
2、水平切分方法
当数据量越来越大时,需要对数据库进行水平切分,上文描述的切分方法有”根据数值范围”和”根据数值取模”。
“根据数值范围”:以主键uid为划分依据,按uid的范围将数据水平切分到多个数据库上。例如:user-db1存储uid范围为0~1000w的数据,user-db2存储uid范围为1000w~2000wuid数据。
- 优点是:扩容简单,如果容量不够,只要增加新db即可。
- 不足是:请求量不均匀,一般新注册的用户活跃度会比较高,所以新的user-db2会比user-db1负载高,导致服务器利用率不平衡
“根据数值取模”:也是以主键uid为划分依据,按uid取模的值将数据水平切分到多个数据库上。例如:user-db1存储uid取模得1的数据,user-db2存储uid取模得0的uid数据。
- 优点是:数据量和请求量分布均均匀
- 不足是:扩容麻烦,当容量不够时,新增加db,需要rehash。需要考虑对数据进行平滑的迁移。
3、非uid的查询方法
水平切分后,对于按uid查询的需求能很好的满足,可以直接路由到具体数据库。而按非uid的查询,例如login_name,就不知道具体该访问哪个库了,此时需要遍历所有库,性能会降低很多。
对于用户侧,可以采用”建立非uid属性到uid的映射关系”的方案;对于运营侧,可以采用”前台与后台分离”的方案。
3.1、建立非uid属性到uid的映射关系
1)映射关系
例如:login_name不能直接定位到数据库,可以建立login_name→uid的映射关系,用索引表或缓存来存储。当访问login_name时,先通过映射表查询出login_name对应的uid,再通过uid定位到具体的库。
映射表只有两列,可以承载很多数据,当数据量过大时,也可以对映射表再做水平切分。这类kv格式的索引结构,可以很好的使用cache来优化查询性能,而且映射关系不会频繁变更,缓存命中率会很高。
2)基因法
分库基因:假如通过uid分库,分为8个库,采用uid%8的方式进行路由,此时是由uid的最后3bit来决定这行User数据具体落到哪个库上,那么这3bit可以看为分库基因。
上面的映射关系的方法需要额外存储映射表,按非uid字段查询时,还需要多一次数据库或cache的访问。如果想要消除多余的存储和查询,可以通过f函数取login_name的基因作为uid的分库基因。生成uid时,参考上文所述的分布式唯一ID生成方案,再加上最后3位bit值=f(login_name)。当查询login_name时,只需计算f(login_name)%8的值,就可以定位到具体的库。不过这样需要提前做好容量规划,预估未来几年的数据量需要分多少库,要预留一定bit的分库基因。
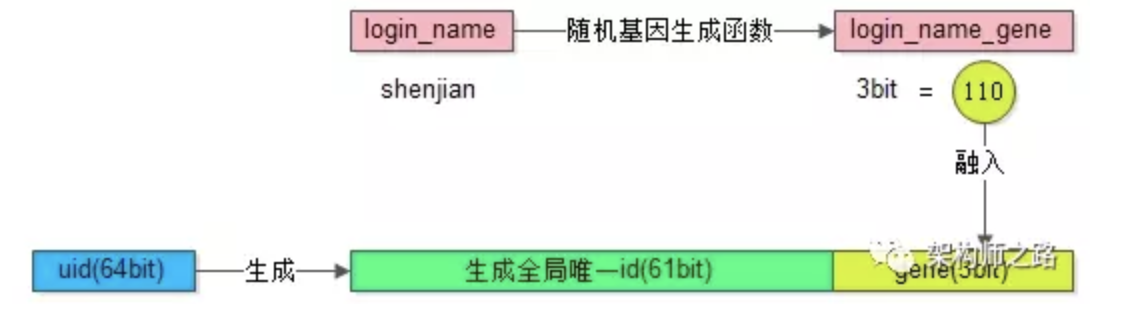
3.2、前台与后台分离
对于用户侧,主要需求是以单行查询为主,需要建立login_name/phone/email到uid的映射关系,可以解决这些字段的查询问题。
而对于运营侧,很多批量分页且条件多样的查询,这类查询计算量大,返回数据量大,对数据库的性能消耗较高。此时,如果和用户侧公用同一批服务或数据库,可能因为后台的少量请求,占用大量数据库资源,而导致用户侧访问性能降低或超时。
这类业务最好采用”前台与后台分离”的方案,运营侧后台业务抽取独立的service和db,解决和前台业务系统的耦合。由于运营侧对可用性、一致性的要求不高,可以不访问实时库,而是通过binlog异步同步数据到运营库进行访问。在数据量很大的情况下,还可以使用ES搜索引擎或Hive来满足后台复杂的查询方式。
五. 支持分库分表中间件
站在巨人的肩膀上能省力很多,目前分库分表已经有一些较为成熟的开源解决方案:
六. 参考
sql语句优化
性能不理想的系统:
- 应用程序的负载确实超过了服务器的实际处理能力外
- 系统存在大量的SQL语句需要优化
优化原则一:SQL语句越简单越好
- 不要有超过5个以上的表连接(JOIN)
- 考虑使用临时表或表变量存放中间结果。
- 少用子查询
- 视图嵌套不要过深,一般视图嵌套不要超过2个为宜。
使用推荐:
-
连接的表越多,其编译的时间和连接的开销也越大,性能越不好控制。
-
最好是把连接拆开成较小的几个部分逐个顺序执行。
-
优先执行那些能够大量减少结果的连接。
-
拆分的好处不仅仅是减少SQL Server优化的时间,更使得SQL语句能够以你可以预测的方式和顺序执行。
如果一定需要连接很多表才能得到数据,那么很可能意味着设计上的缺陷。
outer join 使用的缺点
连接是outer join,非常不好。因为outer join意味着必须对左表或右表查询所有行。如果表很大而没有相应的where语句,那么outer join很容易导致table scan或index scan。 要尽量使用inner join避免scan整个表。
优化建议:
- 使用临时表存放t1表的结果,能大大减少logical reads(或返回行数)的操作要优先执行。
仔细分析语句,你会发现where中的条件全是针对表t1的,所以直接使用上面的where子句查询表t1,然后把结果存放再临时表#t1中:
Select t1….. into #tt1 from t1 where…(和上面的where一样)
- 再把#tt1和其他表进行连接:
Select #t1… Left outer join … Left outer join… - 修改 like 程序,去掉前置百分号。like语句却因为前置百分号而无法使用索引
- 从系统设计的角度修改语句,去掉outer join。
- 考虑组合索引或覆盖索引消除 clustered index scan。
上面1和2点建议立即消除了worktable,性能提高了几倍以上,效果非常明显。
限制结果集
要尽量减少返回的结果行,包括行数和字段列数。
返回的结果越大,意味着相应的SQL语句的logical reads 就越大,对服务器的性能影响就越甚。
一个很不好的设计就是返回表的所有数据:
Select * from tablename
即使表很小也会导致并发问题。更坏的情况是,如果表有上百万行的话,那后果将是灾难性的。
它不但可能带来极重的磁盘IO,更有可能把数据库缓冲区中的其他缓存数据挤出,使得这些数据下次必须再从磁盘读取。
必须设计良好的SQL语句,使得其有where语句或TOP语句来限制结果集大小。
合理的表设计
SQL Server 2005将支持表分区技术。利用表分区技术可以实现数据表的流动窗口功能。
在流动窗口中可以轻易的把历史数据移出,把新的数据加入,从而使表的大小基本保持稳定。
另外,表的设计未必需要非常范式化。有一定的字段冗余可以增加SQL语句的效率,减少JOIN的数目,提高语句的执行速度。
OLAP和OLTP模块要分开
OLAP和OLTP类型的语句是截然不同的。前者往往需要扫描整个表做统计分析,索引对这样的语句几乎没有多少用处。
索引只能够加快那些如sum,group by之类的聚合运算。因为这个原因,几乎很难对OLAP类型的SQL语句进行优化。
而OLTP语句则只需要访问表的很小一部分数据,而且这些数据往往可以从内存缓存中得到。
为了避免OLAP 和OLTP语句相互影响,这两类模块需要分开运行在不同服务器上。
因为OLAP语句几乎都是读取数据,没有更新和写入操作,所以一个好的经验是配置一台standby 服务器,然后OLAP只访问standby服务器。
使用存储过程
可以考虑使用存储过程封装那些复杂的SQL语句或商业逻辑,这样做有几个好处。
一是存储过程的执行计划可以被缓存在内存中较长时间,减少了重新编译的时间。
二是存储过程减少了客户端和服务器的繁复交互。
三是如果程序发布后需要做某些改变你可以直接修改存储过程而不用修改程序,避免需要重新安装部署程序。
索引优化
很多数据库系统性能不理想是因为系统没有经过整体优化,存在大量性能低下的SQL 语句。
这类SQL语句性能不好的首要原因是缺乏高效的索引。
没有索引除了导致语句本身运行速度慢外,更是导致大量的磁盘读写操作,使得整个系统性能都受之影响而变差。
解决这类系统的首要办法是优化这些没有索引或索引不够好的SQL语句。
创建索引的关键
优化SQL语句的关键是尽可能减少语句的logical reads。
这里说的logical reads是指语句执行时需要访问的单位为8K的数据页总数。
logical reads 越少,其需要的内存和CPU时间也就越少,语句执行速度就越快。
不言而喻,索引的最大好处是它可以极大减少SQL语句的logical reads数目,从而极大减少语句的执行时间。
创建索引的关键是索引要能够大大减少语句的logical reads。一个索引好不好,主要看它减少的logical reads多不多。
运行set statistics io命令可以得到SQL语句的logical reads信息。
set statistics io on
select au_id,au_lname ,au_fname
from pubs..authors where au_lname =’Green’
set statistics io on
如果Logical reads很大,而返回的行数很少,也即两者相差较大,那么往往意味者语句需要优化。
Logical reads中包含该语句从内存数据缓冲区中访问的页数和从物理磁盘读取的页数。
而physical reads表示那些没有驻留在内存缓冲区中需要从磁盘读取的数据页。
Read-ahead reads是SQL Server为了提高性能而产生的预读。预读可能会多读取一些数据。
优化的时候我们主要关注Logical Reads就可以了。
注意如果physical Reads或Read-ahead reads很大,那么往往意味着语句的执行时间(duration)里面会有一部分耗费在等待物理磁盘IO上。
二、单字段索引,组合索引和覆盖索引
单字段索引是指只有一个字段的索引,而组合索引指有多个字段构成的索引。
1. 对出现在where子句中的字段加索引
set statistics profile on
set statistics io on
go
select …. from tb where …
go
set statistics profile off
set statistics io off
set statistics profile命令将输出语句的执行计划。
也许你会问,为什么不用SET SHOWPLAN_ALL呢?使用SET SHOWPLAN_ALL也是可以的。
不过set statistics profile输出的是SQL 语句的运行时候真正使用的执行计划,
而SET SHOWPLAN_ALL输出的是预计(Estimate)的执行计划。
使用SET SHOWPLAN_ALL是后面的语句并不会真正运行。
用了Table Scan,也就是对整个表进行了全表扫描。全表扫描的性能通常是很差的,要尽量避免。
如果上面的select语句是数据库系统经常运行的关键语句, 那么应该对它创建相应的索引。
创建索引的技巧之一是对经常出现在where条件中的字段创建索引
Table Scan也变成了Index Seek,性能极大提高
设法避免Table scan或Index scan是优化SQL 语句使用的常用技巧。通常Index Seek需要的logical reads比前两者要少得多。
2.组合索引
如果where语句中有多个字段,那么可以考虑创建组合索引。
组合索引中字段的顺序是非常重要的,越是唯一的字段越是要靠前。
另外,无论是组合索引还是单个列的索引,尽量不要选择那些唯一性很低的字段。
比如说,在只有两个值0和1的字段上建立索引没有多大意义。
所以如果对单字段进行索引,建议使用set statistics profile来验证索引确实被充分使用。logical reads越少的索引越好。
3.覆盖索引
覆盖索引能够使得语句不需要访问表仅仅访问索引就能够得到所有需要的数据。
因为聚集索引叶子节点就是数据所以无所谓覆盖与否,所以覆盖索引主要是针对非聚集索引而言。
执行计划中除了index seek外,还有一个Bookmark Lookup关键字。
Bookmark Lookup表示语句在访问索引后还需要对表进行额外的Bookmark Lookup操作才能得到数据。
也就是说为得到一行数据起码有两次IO,一次访问索引,一次访问基本表。
如果语句返回的行数很多,那么Bookmark Lookup操作的开销是很大的。
覆盖索引能够避免昂贵的Bookmark Lookup操作,减少IO的次数,提高语句的性能。
覆盖索引需要包含select子句和WHERE子句中出现的所有字段。Where语句中的字段在前面,select中的在后面。
logical reads,是大大减少了。Bookmark Lookup操作也消失了。所以创建覆盖索引是减少logical reads提升语句性能的非常有用的优化技巧。
实际上索引的创建原则是比较复杂的。有时候你无法在索引中包含了Where子句中所有的字段。
在考虑索引是否应该包含一个字段时,应考虑该字段在语句中的作用。
比如说如果经常以某个字段作为where条件作精确匹配返回很少的行,那么就绝对值得为这个字段建立索引。
再比如说,对那些非常唯一的字段如主键和外键,经常出现在group by,order by中的字段等等都值得创建索引。
问题1,是否值得在identity字段上建立聚集索引。
答案取决于identity 字段如何在语句中使用。如果你经常根据该字段搜索返回很少的行,那么在其上建立索引是值得的。
反之如果identity字段根本很少在语句中使用,那么就不应该对其建立任何索引。
问题2,一个表应该建立多少索引合适。
如果表的80%以上的语句都是读操作,那么索引可以多些。但是不要太多。
特别是不要对那些更新频繁的表其建立很多的索引。很少表有超过5个以上的索引。
过多的索引不但增加其占用的磁盘空间,也增加了SQL Server 维护索引的开销。
问题4:为什么SQL Server 在执行计划中没有使用你认为应该使用的索引?原因是多样的。
一种原因是该语句返回的结果超过了表的20%数据,使得SQL Server 认为scan比seek更有效。
另一种原因可能是表字段的statistics过期了,不能准确反映数据的分布情况。
你可以使用命令UPDATE STATISTICS tablename with FULLSCAN来更新它。
只有同步的准确的statistics才能保证SQL Server 产生正确的执行计划。
过时的老的statistics常会导致SQL Server生成不够优化的甚至愚蠢的执行计划。
所以如果你的表频繁更新,而你又觉得和之相关的SQL语句运行缓慢,不妨试试UPDATE STATISTIC with FULLSCAN 语句。
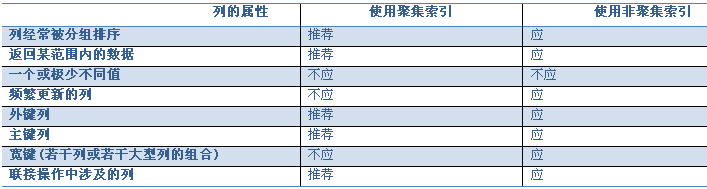
问题5、什么使用聚集索引,什么时候使用非聚集索引
在SQL Server 中索引有聚集索引和非聚集索引两种。它们的主要差别是前者的索引叶子就是数据本身,而后者的叶子节点包含的是指向数据的书签(即数据行号或聚集索引的key)。
对一个表而言聚集索引只能有一个,而非聚集索引可以有多个。
只是聚集索引没有Bookmark Lookup操作。
什么时候应该使用聚集索引? 什么时候使用非聚集索引? 取决于应用程序的访问模式。
我的建议是在那些关键的字段上使用聚集索引。一个表一般都需要建立一个聚集索引。
对于什么时候使用聚集索引,SQL Server 2000联机手册中有如下描述:
在创建聚集索引之前,应先了解您的数据是如何被访问的。可考虑将聚集索引用于:
包含大量非重复值的列。
使用下列运算符返回一个范围值的查询:BETWEEN、>、>=、< 和 <=。
被连续访问的列。
返回大型结果集的查询。
经常被使用联接或 GROUP BY 子句的查询访问的列;一般来说,这些是外键列。
对 ORDER BY 或 GROUP BY 子句中指定的列进行索引,可以使 SQL Server 不必对数据进行排序,因为这些行已经排序。这样可以提高查询性能。
OLTP 类型的应用程序,这些程序要求进行非常快速的单行查找(一般通过主键)。应在主键上创建聚集索引。
聚集索引不适用于:
频繁更改的列
这将导致整行移动(因为 SQL Server 必须按物理顺序保留行中的数据值)。这一点要特别注意,因为在大数据量事务处理系统中数据是易失的。
宽键
来自聚集索引的键值由所有非聚集索引作为查找键使用,因此存储在每个非聚集索引的叶条目内。
总结:
如何使一个性能缓慢的系统运行更快更高效,不但需要整体分析数据库系统,找出系统的性能瓶颈,更需要优化数据库系统发出的SQL 语句。
一旦找出关键的SQL 语句并加与优化,性能问题就会迎刃而解。
《 数据库技术内幕 》
处理百万级以上的数据提高查询速度的方法:
1.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
2.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
3.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num is null 可以在num上设置默认值0,确保表中num列没有null值,然后这样查询: select id from t where num=0 ** **4.应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num=10 or num=20 可以这样查询: select id from t where num=10 union all select id from t where num=20 ** **5.下面的查询也将导致全表扫描:(不能前置百分号) select id from t where name like ‘%abc%’ 若要提高效率,可以考虑全文检索。
6.in 和 not in 也要慎用,否则会导致全表扫描,如: select id from t where num in(1,2,3) 对于连续的数值,能用 between 就不要用 in 了: select id from t where num between 1 and **3
**
select xx,phone FROM send a JOIN ( select ‘13891030091’ phone union select ‘13992085916’ ………… UNION SELECT ‘13619100234’ ) b on a.Phone=b.phone –替代下面 很多数据隔开的时候 in(‘13891030091’,’13992085916’,’13619100234’…………)
7.如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然 而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描: select id from t where num=@num 可以改为强制查询使用索引: select id from t with(index(索引名)) where num=@num
8.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如: select id from t where num/2=100 应改为: select id from t where num=100*2 ** **9.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如: select id from t where substring(name,1,3)=’abc’–name以abc开头的id select id from t where datediff(day,createdate,’2005-11-30′)=0–’2005-11-30′生成的id 应改为: select id from t where name like ‘abc%’ select id from t where createdate>=’2005-11-30′ and createdate<’2005-12-1′
10.不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
11.在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使 用,并且应尽可能的让字段顺序与索引顺序相一致。
12.不要写一些没有意义的查询,如需要生成一个空表结构: select col1,col2 into #t from t where 1=0 这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样: create table #t(…)
13.很多时候用 exists 代替 in 是一个好的选择: select num from a where num in(select num from b) 用下面的语句替换: select num from a where exists(select 1 from b where num=a.num)** ** 14.并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段 sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。
15.索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有 必要。
16.应尽可能的避免更新 clustered 索引数据列,因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新 clustered 索引数据列,那么需要考虑是否应将该索引建为 clustered 索引。
17.尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会 逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
18.尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
19.任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
20.尽量使用表变量来代替临时表。如果表变量包含大量数据,请注意索引非常有限(只有主键索引)。
21.避免频繁创建和删除临时表,以减少系统表资源的消耗。
22.临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使 用导出表。
23.在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。
24.如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
25.尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。
26.使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。
27.与临时表一样,游标并不是不可使用。对小型数据集使用 FAST_FORWARD 游标通常要优于其他逐行处理方法,尤其是在必须引用几个表才能获得所需的数据时。在结果集中包括“合计”的例程通常要比使用游标执行的速度快。如果开发时 间允许,基于游标的方法和基于集的方法都可以尝试一下,看哪一种方法的效果更好。
28.在所有的存储过程和触发器的开始处设置 SET NOCOUNT ON ,在结束时设置 SET NOCOUNT OFF 。无需在执行存储过程和触发器的每个语句后向客户端发送 DONE_IN_PROC 消息。
29.尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
30.尽量避免大事务操作,提高系统并发能力。
查询速度慢的原因:
1、没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷)
2、I/O吞吐量小,形成了瓶颈效应。
3、没有创建计算列导致查询不优化。
4、内存不足
5、网络速度慢
6、查询出的数据量过大(可以采用多次查询,其他的方法降低数据量)
7、锁或者死锁(这也是查询慢最常见的问题,是程序设计的缺陷)
8、sp_lock,sp_who,活动的用户查看,原因是读写竞争资源。
9、返回了不必要的行和列
10、查询语句不好,没有优化
可以通过如下方法来优化查询
1、把数据、日志、索引放到不同的I/O设备上,增加读取速度,以前可以将Tempdb应放在RAID0上,SQL2000不在支持。数据量(尺寸)越大,提高I/O越重要.
2、纵向、横向分割表,减少表的尺寸(sp_spaceuse)
3、升级硬件
4、根据查询条件,建立索引,优化索引、优化访问方式,限制结果集的数据量。注意填充因子要适当(最好是使用默认值0)。索引应该尽量小,使用字节数小的列建索引好(参照索引的创建),不要对有限的几个值的字段建单一索引如性别字段
5、提高网速;
6、扩大服务器的内存,Windows 2000和SQL server 2000能支持4-8G的内存。配置虚拟内存:虚拟内存大小应基于计算机上并发运行的服务进行配置。运行 Microsoft SQL Server? 2000 时,可考虑将虚拟内存大小设置为计算机中安装的物理内存的 1.5 倍。如果另外安装了全文检索功能,并打算运行 Microsoft 搜索服务以便执行全文索引和查询,可考虑:将虚拟内存大小配置为至少是计算机中安装的物理内存的 3 倍。将 SQL Server max server memory 服务器配置选项配置为物理内存的 1.5 倍(虚拟内存大小设置的一半)。
7、增加服务器CPU个数;但是必须明白并行处理串行处理更需要资源例如内存。使用并行还是串行程是MsSQL自动评估选择的。单个任务分解成多个任务,就可以在处理器上运行。例如耽搁查询的排序、连接、扫描和GROUP BY字句同时执行,SQL SERVER根据系统的负载情况决定最优的并行等级,复杂的需要消耗大量的CPU的查询最适合并行处理。但是更新操作UPDATE,INSERT, DELETE还不能并行处理。
8、如果是使用like进行查询的话,简单的使用index是不行的,但是全文索引,耗空间。 like ‘a%’ 使用索引 like ‘%a’ 不使用索引用 like ‘%a%’ 查询时,查询耗时和字段值总长度成正比,所以不能用CHAR类型,而是VARCHAR。对于字段的值很长的建全文索引。
9、DB Server 和APPLication Server 分离;OLTP和OLAP分离
10、分布式分区视图可用于实现数据库服务器联合体。联合体是一组分开管理的服务器,但它们相互协作分担系统的处理负荷。这种通过分区数据形成数据库服务器联合体的机制能够扩大一组服务器,以支持大型的多层 Web 站点的处理需要。有关更多信息,参见设计联合数据库服务器。(参照SQL帮助文件’分区视图’) a、在实现分区视图之前,必须先水平分区表 b、在创建成员表后,在每个成员服务器上定义一个分布式分区视图,并且每个视图具有相同的名称。这样,引用分布式分区视图名的查询可以在任何一个成员服务器上运行。系统操作如同每个成员服务器上都有一个原始表的复本一样,但其实每个服务器上只有一个成员表和一个分布式分区视图。数据的位置对应用程序是透明的。
11、重建索引 DBCC REINDEX ,DBCC INDEXDEFRAG,收缩数据和日志 DBCC SHRINKDB,DBCC SHRINKFILE. 设置自动收缩日志.对于大的数据库不要设置数据库自动增长,它会降低服务器的性能。 在T-sql的写法上有很大的讲究,下面列出常见的要点:首先,DBMS处理查询计划的过程是这样的:
1、 查询语句的词法、语法检查
2、 将语句提交给DBMS的查询优化器
3、 优化器做代数优化和存取路径的优化
4、 由预编译模块生成查询规划
5、 然后在合适的时间提交给系统处理执行
6、 最后将执行结果返回给用户其次,看一下SQL SERVER的数据存放的结构:一个页面的大小为8K(8060)字节,8个页面为一个盘区,按照B树存放。
12、Commit和rollback的区别 Rollback:回滚所有的事物。 Commit:提交当前的事物. 没有必要在动态SQL里写事物,如果要写请写在外面如: begin tran exec(@s) commit trans 或者将动态SQL 写成函数或者存储过程。
13、在查询Select语句中用Where字句限制返回的行数,避免表扫描,如果返回不必要的数据,浪费了服务器的I/O资源,加重了网络的负担降低性能。如果表很大,在表扫描的期间将表锁住,禁止其他的联接访问表,后果严重。
14、SQL的注释申明对执行没有任何影响
15、尽可能不使用游标,它占用大量的资源。如果需要row-by-row地执行,尽量采用非光标技术,如:在客户端循环,用临时表,Table变量,用子查询,用Case语句等等。游标可以按照它所支持的提取选项进行分类: 只进 必须按照从第一行到最后一行的顺序提取行。FETCH NEXT 是唯一允许的提取操作,也是默认方式。可滚动性 可以在游标中任何地方随机提取任意行。游标的技术在SQL2000下变得功能很强大,他的目的是支持循环。 有四个并发选项 READ_ONLY:不允许通过游标定位更新(Update),且在组成结果集的行中没有锁。 OPTIMISTIC WITH valueS:乐观并发控制是事务控制理论的一个标准部分。乐观并发控制用于这样的情形,即在打开游标及更新行的间隔中,只有很小的机会让第二个用户更新某一行。当某个游标以此选项打开时,没有锁控制其中的行,这将有助于最大化其处理能力。如果用户试图修改某一行,则此行的当前值会与最后一次提取此行时获取的值进行比较。如果任何值发生改变,则服务器就会知道其他人已更新了此行,并会返回一个错误。如果值是一样的,服务器就执行修改。 选择这个并发选项OPTIMISTIC WITH ROW VERSIONING:此乐观并发控制选项基于行版本控制。使用行版本控制,其中的表必须具有某种版本标识符,服务器可用它来确定该行在读入游标后是否有所更改。 在 SQL Server 中,这个性能由 timestamp 数据类型提供,它是一个二进制数字,表示数据库中更改的相对顺序。每个数据库都有一个全局当前时间戳值:@@DBTS。每次以任何方式更改带有 timestamp 列的行时,SQL Server 先在时间戳列中存储当前的 @@DBTS 值,然后增加 @@DBTS 的值。如果某 个表具有 timestamp 列,则时间戳会被记到行级。服务器就可以比较某行的当前时间戳值和上次提取时所存储的时间戳值,从而确定该行是否已更新。服务器不必比较所有列的值,只需比较 timestamp 列即可。如果应用程序对没有 timestamp 列的表要求基于行版本控制的乐观并发,则游标默认为基于数值的乐观并发控制。 SCROLL LOCKS 这个选项实现悲观并发控制。在悲观并发控制中,在把数据库的行读入游标结果集时,应用程序将试图锁定数据库行。在使用服务器游标时,将行读入游标时会在其上放置一个更新锁。如果在事务内打开游标,则该事务更新锁将一直保持到事务被提交或回滚;当提取下一行时,将除去游标锁。如果在事务外打开游标,则提取下一行时,锁就被丢弃。因此,每当用户需要完全的悲观并发控制时,游标都应在事务内打开。更新锁将阻止任何其它任务获取更新锁或排它锁,从而阻止其它任务更新该行。 然而,更新锁并不阻止共享锁,所以它不会阻止其它任务读取行,除非第二个任务也在要求带更新锁的读取。滚动锁根据在游标定义的 SELECT 语句中指定的锁提示,这些游标并发选项可以生成滚动锁。滚动锁在提取时在每行上获取,并保持到下次提取或者游标关闭,以先发生者为准。下次提取时,服务器为新提取中的行获取滚动锁,并释放上次提取中行的滚动锁。滚动锁独立于事务锁,并可以保持到一个提交或回滚操作之后。如果提交时关闭游标的选项为关,则 COMMIT 语句并不关闭任何打开的游标,而且滚动锁被保留到提交之后,以维护对所提取数据的隔离。所获取滚动锁的类型取决于游标并发选项和游标 SELECT 语句中的锁提示。 锁提示 只读 乐观数值 乐观行版本控制 锁定无提示 未锁定 未锁定 未锁定 更新 NOLOCK 未锁定 未锁定 未锁定 未锁定 HOLDLOCK 共享 共享 共享 更新 UPDLOCK 错误 更新 更新 更新 TABLOCKX 错误 未锁定 未锁定 更新其它 未锁定 未锁定 未锁定 更新 *指定 NOLOCK 提示将使指定了该提示的表在游标内是只读的。
16、用Profiler来跟踪查询,得到查询所需的时间,找出SQL的问题所在;用索引优化器优化索引
17、注意UNion和UNion all 的区别。UNION all好
18、注意使用DISTINCT,在没有必要时不要用,它同UNION一样会使查询变慢。重复的记录在查询里是没有问题的
19、查询时不要返回不需要的行、列
20、用sp_configure ‘query governor cost limit’或者SET QUERY_GOVERNOR_COST_LIMIT来限制查询消耗的资源。当评估查询消耗的资源超出限制时,服务器自动取消查询,在查询之前就扼杀掉。 SET LOCKTIME设置锁的时间
21、用select top 100 / 10 Percent 来限制用户返回的行数或者SET ROWCOUNT来限制操作的行
22、在SQL2000以前,一般不要用如下的字句 “IS NULL”, “ <> “, “!=”, “!> “, “! <”, “NOT”, “NOT EXISTS”, “NOT IN”, “NOT LIKE”, and “LIKE ‘%500’“,因为他们不走索引全是表扫描。 也不要在WHere字句中的列名加函数,如Convert,substring等,如果必须用函数的时候,创建计算列再创建索引来替代.还可以变通写法:WHERE SUBSTRING(firstname,1,1) = ‘m’改为WHERE firstname like ‘m%’(索引扫描),一定要将函数和列名分开。并且索引不能建得太多和太大。 NOT IN会多次扫描表,使用EXISTS、NOT EXISTS ,IN , LEFT OUTER JOIN 来替代,特别是左连接,而Exists比IN更快,最慢的是NOT操作.如果列的值含有空,以前它的索引不起作用,现在2000的优化器能够处理了。相同的是IS NULL,“NOT”, “NOT EXISTS”, “NOT IN”能优化她,而” <> ”等还是不能优化,用不到索引。
23、使用Query Analyzer,查看SQL语句的查询计划和评估分析是否是优化的SQL。一般的20%的代码占据了80%的资源,我们优化的重点是这些慢的地方。
24、如果使用了IN或者OR等时发现查询没有走索引,使用显示申明指定索引: SELECT * FROM PersonMember (INDEX = IX_Title) WHERE processid IN (‘男’,‘女’)
25、将需要查询的结果预先计算好放在表中,查询的时候再SELECT。这在SQL7.0以前是最重要的手段。例如医院的住院费计算。
26、MIN() 和 MAX()能使用到合适的索引
27、数据库有一个原则是代码离数据越近越好,所以优先选择Default,依次为Rules,Triggers, Constraint(约束如外健主健CheckUNIQUE……,数据类型的最大长度等等都是约束),Procedure.这样不仅维护工作小,编写程序质量高,并且执行的速度快。
28、如果要插入大的二进制值到Image列,使用存储过程,千万不要用内嵌INsert来插入(不知JAVA是否)。因为这样应用程序首先将二进制值转换成字符串(尺寸是它的两倍),服务器受到字符后又将他转换成二进制值.存储过程就没有这些动作: 方法:Create procedure p_insert as insert into table(Fimage) values (@image), 在前台调用这个存储过程传入二进制参数,这样处理速度明显改善。
29、Between在某些时候比IN速度更快,Between能够更快地根据索引找到范围。用查询优化器可见到差别。 select * from chineseresume where title in (‘男’,’女’) Select * from chineseresume where between ‘男’ and ‘女’ 是一样的。由于in会在比较多次,所以有时会慢些。
30、在必要是对全局或者局部临时表创建索引,有时能够提高速度,但不是一定会这样,因为索引也耗费大量的资源。他的创建同是实际表一样。
31、不要建没有作用的事物例如产生报表时,浪费资源。只有在必要使用事物时使用它。
32、用OR的字句可以分解成多个查询,并且通过UNION 连接多个查询。他们的速度只同是否使用索引有关,如果查询需要用到联合索引,用UNION all执行的效率更高.多个OR的字句没有用到索引,改写成UNION的形式再试图与索引匹配。一个关键的问题是否用到索引。
33、尽量少用视图,它的效率低。对视图操作比直接对表操作慢,可以用stored procedure来代替她。特别的是不要用视图嵌套,嵌套视图增加了寻找原始资料的难度。我们看视图的本质:它是存放在服务器上的被优化好了的已经产生了查询规划的SQL。对单个表检索数据时,不要使用指向多个表的视图,直接从表检索或者仅仅包含这个表的视图上读,否则增加了不必要的开销,查询受到干扰.为了加快视图的查询,MsSQL增加了视图索引的功能。
34、没有必要时不要用DISTINCT和ORDER BY,这些动作可以改在客户端执行。它们增加了额外的开销。这同UNION 和UNION ALL一样的道理。 SELECT top 20 ad.companyname,comid,position,ad.referenceid,worklocation, convert(varchar(10),ad.postDate,120) as postDate1,workyear,degreedescription FROM jobcn_query.dbo.COMPANYAD_query ad where referenceID in(‘JCNAD00329667’,’JCNAD132168’,’JCNAD00337748’,’JCNAD00338345’,’JCNAD00333138’,’JCNAD00303570’, ‘JCNAD00303569’,’JCNAD00303568’,’JCNAD00306698’,’JCNAD00231935’,’JCNAD00231933’,’JCNAD00254567’, ‘JCNAD00254585’,’JCNAD00254608’,’JCNAD00254607’,’JCNAD00258524’,’JCNAD00332133’,’JCNAD00268618’, ‘JCNAD00279196’,’JCNAD00268613’) order by postdate desc
35、在IN后面值的列表中,将出现最频繁的值放在最前面,出现得最少的放在最后面,减少判断的次数
36、当用SELECT INTO时,它会锁住系统表(sysobjects,sysindexes等等),阻塞其他的连接的存取。创建临时表时用显示申明语句,而不是 select INTO. drop table t_lxh begin tran select * into t_lxh from chineseresume where name = ‘XYZ’ –commit 在另一个连接中SELECT * from sysobjects可以看到 SELECT INTO 会锁住系统表,Create table 也会锁系统表(不管是临时表还是系统表)。所以千万不要在事物内使用它!!!这样的话如果是经常要用的临时表请使用实表,或者临时表变量。
37、一般在GROUP BY 个HAVING字句之前就能剔除多余的行,所以尽量不要用它们来做剔除行的工作。他们的执行顺序应该如下最优:select 的Where字句选择所有合适的行,Group By用来分组个统计行,Having字句用来剔除多余的分组。这样Group By 个Having的开销小,查询快.对于大的数据行进行分组和Having十分消耗资源。如果Group BY的目的不包括计算,只是分组,那么用Distinct更快
38、一次更新多条记录比分多次更新每次一条快,就是说批处理好
39、少用临时表,尽量用结果集和Table类性的变量来代替它,Table 类型的变量比临时表好
40、在SQL2000下,计算字段是可以索引的,需要满足的条件如下:
a、计算字段的表达是确定的 b、不能用在TEXT,Ntext,Image数据类型 c、必须配制如下选项 ANSI_NULLS = ON, ANSI_PADDINGS = ON, …….
41、尽量将数据的处理工作放在服务器上,减少网络的开销,如使用存储过程。存储过程是编译好、优化过、并且被组织到一个执行规划里、且存储在数据库中的 SQL语句,是控制流语言的集合,速度当然快。反复执行的动态SQL,可以使用临时存储过程,该过程(临时表)被放在Tempdb中。以前由于SQL SERVER对复杂的数学计算不支持,所以不得不将这个工作放在其他的层上而增加网络的开销。SQL2000支持UDFs,现在支持复杂的数学计算,函数的返回值不要太大,这样的开销很大。用户自定义函数象光标一样执行的消耗大量的资源,如果返回大的结果采用存储过程
42、不要在一句话里再三的使用相同的函数,浪费资源,将结果放在变量里再调用更快
43、SELECT COUNT(*)的效率教低,尽量变通他的写法,而EXISTS快.同时请注意区别: select count(Field of null) from Table 和 select count(Field of NOT null) from Table 的返回值是不同的。
44、当服务器的内存够多时,配制线程数量 = 最大连接数+5,这样能发挥最大的效率;否则使用 配制线程数量 <最大连接数启用SQL SERVER的线程池来解决,如果还是数量 = 最大连接数+5,严重的损害服务器的性能。
45、按照一定的次序来访问你的表。如果你先锁住表A,再锁住表B,那么在所有的存储过程中都要按照这个顺序来锁定它们。如果你(不经意的)某个存储过程中先锁定表B,再锁定表A,这可能就会导致一个死锁。如果锁定顺序没有被预先详细的设计好,死锁很难被发现
46、通过SQL Server Performance Monitor监视相应硬件的负载 Memory: Page Faults / sec计数器如果该值偶尔走高,表明当时有线程竞争内存。如果持续很高,则内存可能是瓶颈。 Process:
1、% DPC Time 指在范例间隔期间处理器用在缓延程序调用(DPC)接收和提供服务的百分比。(DPC 正在运行的为比标准间隔优先权低的间隔)。 由于 DPC 是以特权模式执行的,DPC 时间的百分比为特权时间 百分比的一部分。这些时间单独计算并且不属于间隔计算总数的一部 分。这个总数显示了作为实例时间百分比的平均忙时。 2、%Processor Time计数器 如果该参数值持续超过95%,表明瓶颈是CPU。可以考虑增加一个处理器或换一个更快的处理器。 3、% Privileged Time 指非闲置处理器时间用于特权模式的百分比。(特权模式是为操作系统组件和操纵硬件驱动程序而设计的一种处理模式。它允许直接访问硬件和所有内存。另一种模式为用户模式,它是一种为应用程序、环境分系统和整数分系统设计的一种有限处理模式。操作系统将应用程序线程转换成特权模式以访问操作系统服务)。 特权时间的 % 包括为间断和 DPC 提供服务的时间。特权时间比率高可能是由于失败设备产生的大数量的间隔而引起的。这个计数器将平均忙时作为样本时间的一部分显示。 4、% User Time表示耗费CPU的数据库操作,如排序,执行aggregate functions等。如果该值很高,可考虑增加索引,尽量使用简单的表联接,水平分割大表格等方法来降低该值。 Physical Disk: Curretn Disk Queue Length计数器该值应不超过磁盘数的1.5~2倍。要提高性能,可增加磁盘。 SQLServer:Cache Hit Ratio计数器该值越高越好。如果持续低于80%,应考虑增加内存。 注意该参数值是从SQL Server启动后,就一直累加记数,所以运行经过一段时间后,该值将不能反映系统当前值。
47、分析select emp_name form employee where salary > 3000 在此语句中若salary是Float类型的,则优化器对其进行优化为Convert(float,3000),因为3000是个整数,我们应在编程时使用3000.0而不要等运行时让DBMS进行转化。同样字符和整型数据的转换。
--查找所有索引
SELECT 'dbcc showcontig (' + CONVERT(VARCHAR(20), i.id) + ',' + -- table id
CONVERT(VARCHAR(20), i.indid) + ')--' + --index id
OBJECT_NAME(i.id) + '.' + -- table name
i.name--index name
FROM sysobjects o
INNER JOIN sysindexes i ON ( o.id = i.id )
WHERE o.type = 'U'
AND i.indid < 2
AND i.id = OBJECT_ID(o.name)
ORDER BY OBJECT_NAME(i.id), i.indid
--结果
dbcc showcontig (2052202361,1)--AddBusiness.PK_AddBusiness
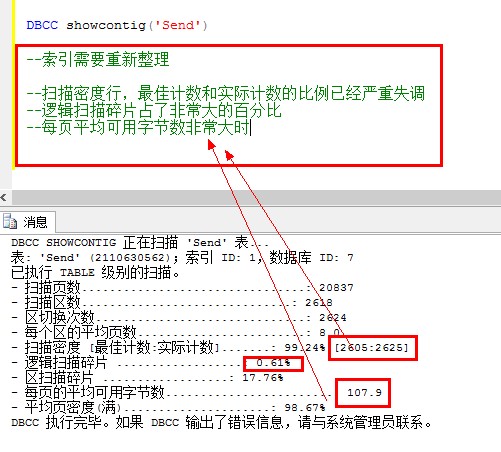
何时需要重建索引:
DBCC showcontig(‘Send’)
mysql视图的作用(详细)
测试表:
测试表:user有id,name,age,sex字段
测试表:goods有id,name,price字段
测试表:ug有id,userid,goodsid字段
视图的作用实在是太强大了,以下是我体验过的好处:
作用一:提高了重用性
提高了重用性,就像一个函数。如果要频繁获取user的name和goods的name。就应该使用以下sql语言。示例:
select a.name as username, b.name as goodsname from user as a, goods as b, ug as c where a.id=c.userid and c.goodsid=b.id;
但有了视图就不一样了,创建视图other。示例
create view other as select a.name as username, b.name as goodsname from user as a, goods as b, ug as c where a.id=c.userid and c.goodsid=b.id;
创建好视图后,就可以这样获取user的name和goods的name。示例:
select * from other;
以上sql语句,就能获取user的name和goods的name了。
作用二: 对数据库重构,却不影响程序的运行。假如因为某种需求,需要将user拆房表usera和表userb,该两张表的结构如下:
测试表:usera有id,name,age字段
测试表:userb有id,name,sex字段
这时如果php端使用sql语句:select * from user;那就会提示该表不存在,这时该如何解决呢。解决方案:创建视图。以下sql语句创建视图:
create view user as select a.name,a.age,b.sex from usera as a, userb as b where a.name=b.name;
以上假设name都是唯一的。此时php端使用sql语句:select * from user;就不会报错什么的。这就__实现了更改数据库结构,不更改脚本程序的功能了__。
作用三:安全性能
提高了安全性能。可以对不同的用户,设定不同的视图。例如:某用户只能获取user表的name和age数据,不能获取sex数据。则可以这样创建视图。示例如下:
create view other as select a.name, a.age from user as a;
这样的话,使用sql语句:select * from other; 最多就只能获取name和age的数据,其他的数据就获取不了了。
作用四:数据更加清晰
让数据更加清晰。想要什么样的数据,就创建什么样的视图。经过以上三条作用的解析,这条作用应该很容易理解了吧
优点及缺点
优点
简单化,数据所见即所得
安全性,用户只能查询或修改他们所能见到得到的数据
逻辑独立性,可以屏蔽真实表结构变化带来的影响
缺点
性能相对较差,简单的查询也会变得稍显复杂
修改不方便,特变是复杂的聚合视图基本无法修改
MySQL索引优化分析
为什么你写的sql查询慢?为什么你建的索引常失效?通过本章内容,你将学会MySQL性能下降的原因,索引的简介,索引创建的原则,explain命令的使用,以及explain输出字段的意义。助你了解索引,分析索引,使用索引,从而写出更高性能的sql语句。还在等啥子?撸起袖子就是干!
案例分析
我们先简单了解一下非关系型数据库和关系型数据库的区别。 MongoDB是NoSQL中的一种。NoSQL的全称是Not only SQL,非关系型数据库。它的特点是性能高,扩张性强,模式灵活,在高并发场景表现得尤为突出。但目前它还只是关系型数据库的补充,它在数据的一致性,数据的安全性,查询的复杂性问题上和关系型数据库还存在一定差距。 MySQL是关系性数据库中的一种,查询功能强,数据一致性高,数据安全性高,支持二级索引。但性能方面稍逊与MongoDB,特别是百万级别以上的数据,很容易出现查询慢的现象。这时候需要分析查询慢的原因,一般情况下是程序员sql写的烂,或者是没有键索引,或者是索引失效等原因导致的。 公司ERP系统数据库主要是MongoDB(最接近关系型数据的NoSQL),其次是Redis,MySQL只占很少的部分。现在又重新使用MySQL,归功于阿里巴巴的奇门系统和聚石塔系统。考虑到订单数量已经是百万级以上,对MySQL的性能分析也就显得格外重要。
我们先通过两个简单的例子来入门。后面会详细介绍各个参数的作用和意义。 说明:需要用到的sql已经放在了github上了,喜欢的同学可以点一下star,哈哈。https://github.com/ITDragonBlog/daydayup/tree/master/MySQL/
场景一:订单导入,通过交易号避免重复导单
业务逻辑:订单导入时,为了避免重复导单,一般会通过交易号去数据库中查询,判断该订单是否已经存在。
最基础的sql语句
mysql> select * from itdragon_order_list where transaction_id = "81X97310V32236260E";
+-------+--------------------+-------+------+----------+--------------+----------+------------------+-------------+-------------+------------+---------------------+
| id | transaction_id | gross | net | stock_id | order_status | descript | finance_descript | create_type | order_level | input_user | input_date |
+-------+--------------------+-------+------+----------+--------------+----------+------------------+-------------+-------------+------------+---------------------+
| 10000 | 81X97310V32236260E | 6.6 | 6.13 | 1 | 10 | ok | ok | auto | 1 | itdragon | 2017-08-18 17:01:49 |
+-------+--------------------+-------+------+----------+--------------+----------+------------------+-------------+-------------+------------+---------------------+
mysql> explain select * from itdragon_order_list where transaction_id = "81X97310V32236260E";
+----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | itdragon_order_list | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 33.33 | Using where |
+----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+-------------+
查询的本身没有任何问题,在线下的测试环境也没有任何问题。可是,功能一旦上线,查询慢的问题就迎面而来。几百上千万的订单,用全表扫描?啊?哼! 怎么知道该sql是全表扫描呢?通过explain命令可以清楚MySQL是如何处理sql语句的。打印的内容分别表示: id : 查询序列号为1。 select_type : 查询类型是简单查询,简单的select语句没有union和子查询。 table : 表是 itdragon_order_list。 partitions : 没有分区。 type : 连接类型,all表示采用全表扫描的方式。 possible_keys : 可能用到索引为null。 key : 实际用到索引是null。 key_len : 索引长度当然也是null。 ref : 没有哪个列或者参数和key一起被使用。 Extra : 使用了where查询。 因为数据库中只有三条数据,所以rows和filtered的信息作用不大。这里需要重点了解的是type为ALL,全表扫描的性能是最差的,假设数据库中有几百万条数据,在没有索引的帮助下会异常卡顿。
初步优化:为transaction_id创建索引
mysql> create unique index idx_order_transaID on itdragon_order_list (transaction_id);
mysql> explain select * from itdragon_order_list where transaction_id = "81X97310V32236260E";
+----+-------------+---------------------+------------+-------+--------------------+--------------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------------------+------------+-------+--------------------+--------------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | itdragon_order_list | NULL | const | idx_order_transaID | idx_order_transaID | 453 | const | 1 | 100 | NULL |
+----+-------------+---------------------+------------+-------+--------------------+--------------------+---------+-------+------+----------+-------+
这里创建的索引是唯一索引,而非普通索引。 唯一索引打印的type值是const。表示通过索引一次就可以找到。即找到值就结束扫描返回查询结果。 普通索引打印的type值是ref。表示非唯一性索引扫描。找到值还要继续扫描,直到将索引文件扫描完为止。(这里没有贴出代码) 显而易见,const的性能要远高于ref。并且根据业务逻辑来判断,创建唯一索引是合情合理的。
再次优化:覆盖索引
mysql> explain select transaction_id from itdragon_order_list where transaction_id = "81X97310V32236260E";
+----+-------------+---------------------+------------+-------+--------------------+--------------------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------------------+------------+-------+--------------------+--------------------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | itdragon_order_list | NULL | const | idx_order_transaID | idx_order_transaID | 453 | const | 1 | 100 | Using index |
+----+-------------+---------------------+------------+-------+--------------------+--------------------+---------+-------+------+----------+-------------+
这里将select * from 改为了 select transaction_id from 后
Extra 显示 Using index,表示该查询使用了覆盖索引,这是一个非常好的消息,说明该sql语句的性能很好。若提示的是Using filesort(使用内部排序)和Using temporary(使用临时表)则表明该sql需要立即优化了。
根据业务逻辑来的,查询结构返回transaction_id 是可以满足业务逻辑要求的。
场景二,订单管理页面,通过订单级别和订单录入时间排序
业务逻辑:优先处理订单级别高,录入时间长的订单。 既然是排序,首先想到的应该是order by, 还有一个可怕的 Using filesort 等着你。
最基础的sql语句
mysql> explain select * from itdragon_order_list order by order_level,input_date;
+----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+----------------+
| 1 | SIMPLE | itdragon_order_list | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 100 | Using filesort |
+----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+----------------+
首先,采用全表扫描就不合理,还使用了文件排序Using filesort,更加拖慢了性能。 MySQL在4.1版本之前文件排序是采用双路排序的算法,由于两次扫描磁盘,I/O耗时太长。后优化成单路排序算法。其本质就是用空间换时间,但如果数据量太大,buffer的空间不足,会导致多次I/O的情况。其效果反而更差。与其找运维同事修改MySQL配置,还不如自己乖乖地建索引。
初步优化:为order_level,input_date 创建复合索引
mysql> create index idx_order_levelDate on itdragon_order_list (order_level,input_date);
mysql> explain select * from itdragon_order_list order by order_level,input_date;
+----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+----------------+
| 1 | SIMPLE | itdragon_order_list | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 100 | Using filesort |
+----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+----------------+
创建复合索引后你会惊奇的发现,和没创建索引一样???都是全表扫描,都用到了文件排序。是索引失效?还是索引创建失败?我们试着看看下面打印情况
mysql> explain select order_level,input_date from itdragon_order_list order by order_level,input_date;
+----+-------------+---------------------+------------+-------+---------------+---------------------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------------------+------------+-------+---------------+---------------------+---------+------+------+----------+-------------+
| 1 | SIMPLE | itdragon_order_list | NULL | index | NULL | idx_order_levelDate | 68 | NULL | 3 | 100 | Using index |
+----+-------------+---------------------+------------+-------+---------------+---------------------+---------+------+------+----------+-------------+
将select * from 换成了 select order_level,input_date from 后。type从all升级为index,表示(full index scan)全索引文件扫描,Extra也显示使用了覆盖索引。可是不对啊!!!!检索虽然快了,但返回的内容只有order_level和input_date 两个字段,让业务同事怎么用?难道把每个字段都建一个复合索引?
MySQL没有这么笨,可以使用force index 强制指定索引。在原来的sql语句上修改 force index(idx_order_levelDate) 即可。
mysql> explain select * from itdragon_order_list force index(idx_order_levelDate) order by order_level,input_date;
+----+-------------+---------------------+------------+-------+---------------+---------------------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------------------+------------+-------+---------------+---------------------+---------+------+------+----------+-------+
| 1 | SIMPLE | itdragon_order_list | NULL | index | NULL | idx_order_levelDate | 68 | NULL | 3 | 100 | NULL |
+----+-------------+---------------------+------------+-------+---------------+---------------------+---------+------+------+----------+-------+
再次优化:订单级别真的要排序么?
其实给订单级别排序意义并不大,给订单级别添加索引意义也不大。因为order_level的值可能只有,低,中,高,加急,这四种。对于这种重复且分布平均的字段,排序和加索引的作用不大。 我们能否先固定 order_level 的值,然后再给 input_date 排序?如果查询效果明显,是可以推荐业务同事使用该查询方式。
mysql> explain select * from itdragon_order_list where order_level=3 order by input_date;
+----+-------------+---------------------+------------+------+---------------------+---------------------+---------+-------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------------------+------------+------+---------------------+---------------------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | itdragon_order_list | NULL | ref | idx_order_levelDate | idx_order_levelDate | 5 | const | 1 | 100 | Using index condition |
+----+-------------+---------------------+------------+------+---------------------+---------------------+---------+-------+------+----------+-----------------------+
和之前的sql比起来,type从index 升级为 ref(非唯一性索引扫描)。索引的长度从68变成了5,说明只用了一个索引。ref也是一个常量。Extra 为Using index condition 表示自动根据临界值,选择索引扫描还是全表扫描。总的来说性能远胜于之前的sql。
上面两个案例只是快速入门,我们需严记一点:优化是基于业务逻辑来的。绝对不能为了优化而擅自修改业务逻辑。如果能修改当然是最好的。
索引简介
官方定义:索引(Index) 是帮助MySQL高效获取数据的数据结构。
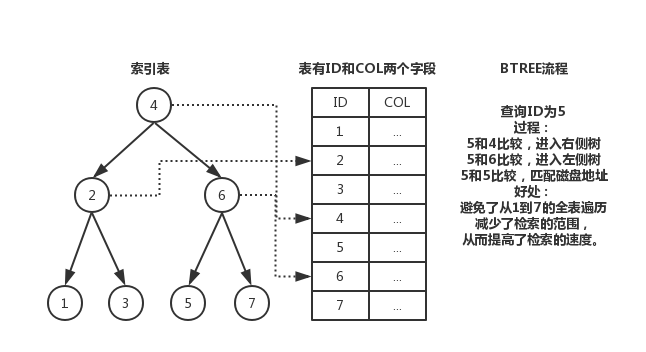
大家一定很好奇,索引为什么是一种数据结构,它又是怎么提高查询的速度?我们拿最常用的二叉树来分析索引的工作原理。看下面的图片:
创建索引的优势 1 提高数据的检索速度,降低数据库IO成本:使用索引的意义就是通过缩小表中需要查询的记录的数目从而加快搜索的速度。 2 降低数据排序的成本,降低CPU消耗:索引之所以查的快,是因为先将数据排好序,若该字段正好需要排序,则真好降低了排序的成本。
创建索引的劣势 1 占用存储空间:索引实际上也是一张表,记录了主键与索引字段,一般以索引文件的形式存储在磁盘上。 2 降低更新表的速度:表的数据发生了变化,对应的索引也需要一起变更,从而减低的更新速度。否则索引指向的物理数据可能不对,这也是索引失效的原因之一。 3 优质索引创建难:索引的创建并非一日之功,也并非一直不变。需要频繁根据用户的行为和具体的业务逻辑去创建最佳的索引。
索引分类
我们常说的索引一般指的是BTree(多路搜索树)结构组织的索引。其中还有聚合索引,次要索引,复合索引,前缀索引,唯一索引,统称索引,当然除了B+树外,还有哈希索引(hash index)等。
单值索引:一个索引只包含单个列,一个表可以有多个单列索引 唯一索引:索引列的值必须唯一,但允许有空值 复合索引:一个索引包含多个列,实际开发中推荐使用 实际开发中推荐使用复合索引,并且单表创建的索引个数建议不要超过五个
基本语法: 创建:
create [unique] index indexName on tableName (columnName...)
alter tableName add [unique] index [indexName] on (columnName...)
删除:
drop index [indexName] on tableName
查看:
show index from tableName
哪些情况需要建索引: 1 主键,唯一索引 2 经常用作查询条件的字段需要创建索引 3 经常需要排序、分组和统计的字段需要建立索引 4 查询中与其他表关联的字段,外键关系建立索引
哪些情况不要建索引: 1 表的记录太少,百万级以下的数据不需要创建索引 2 经常增删改的表不需要创建索引 3 数据重复且分布平均的字段不需要创建索引,如 true,false 之类。 4 频发更新的字段不适合创建索引 5 where条件里用不到的字段不需要创建索引
性能分析
MySQL 自身瓶颈
MySQL自身参见的性能问题有磁盘空间不足,磁盘I/O太大,服务器硬件性能低。 1 CPU:CPU 在饱和的时候一般发生在数据装入内存或从磁盘上读取数据时候 2 IO:磁盘I/O 瓶颈发生在装入数据远大于内存容量的时候 3 服务器硬件的性能瓶颈:top,free,iostat 和 vmstat来查看系统的性能状态
explain 分析sql语句
使用explain关键字可以模拟优化器执行sql查询语句,从而得知MySQL 是如何处理sql语句。
+----+-------------+-------+------------+------+---------------+-----+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+-----+---------+------+------+----------+-------+
id
select 查询的序列号,包含一组可以重复的数字,表示查询中执行sql语句的顺序。一般有三种情况: 第一种:id全部相同,sql的执行顺序是由上至下; 第二种:id全部不同,sql的执行顺序是根据id大的优先执行; 第三种:id既存在相同,又存在不同的。先根据id大的优先执行,再根据相同id从上至下的执行。
select_type
select 查询的类型,主要是用于区别普通查询,联合查询,嵌套的复杂查询 simple:简单的select 查询,查询中不包含子查询或者union primary:查询中若包含任何复杂的子查询,最外层查询则被标记为primary subquery:在select或where 列表中包含了子查询 derived:在from列表中包含的子查询被标记为derived(衍生)MySQL会递归执行这些子查询,把结果放在临时表里。 union:若第二个select出现在union之后,则被标记为union,若union包含在from子句的子查询中,外层select将被标记为:derived union result:从union表获取结果的select
partitions
表所使用的分区,如果要统计十年公司订单的金额,可以把数据分为十个区,每一年代表一个区。这样可以大大的提高查询效率。
type
这是一个非常重要的参数,连接类型,常见的有:all , index , range , ref , eq_ref , const , system , null 八个级别。 性能从最优到最差的排序:system > const > eq_ref > ref > range > index > all 对java程序员来说,若保证查询至少达到range级别或者最好能达到ref则算是一个优秀而又负责的程序员。 all:(full table scan)全表扫描无疑是最差,若是百万千万级数据量,全表扫描会非常慢。 index:(full index scan)全索引文件扫描比all好很多,毕竟从索引树中找数据,比从全表中找数据要快。 range:只检索给定范围的行,使用索引来匹配行。范围缩小了,当然比全表扫描和全索引文件扫描要快。sql语句中一般会有between,in,>,< 等查询。 ref:非唯一性索引扫描,本质上也是一种索引访问,返回所有匹配某个单独值的行。比如查询公司所有属于研发团队的同事,匹配的结果是多个并非唯一值。 eq_ref:唯一性索引扫描,对于每个索引键,表中有一条记录与之匹配。比如查询公司的CEO,匹配的结果只可能是一条记录, const:表示通过索引一次就可以找到,const用于比较primary key 或者unique索引。因为只匹配一行数据,所以很快,若将主键至于where列表中,MySQL就能将该查询转换为一个常量。 system:表只有一条记录(等于系统表),这是const类型的特列,平时不会出现,了解即可
possible_keys
显示查询语句可能用到的索引(一个或多个或为null),不一定被查询实际使用。仅供参考使用。
key
显示查询语句实际使用的索引。若为null,则表示没有使用索引。
key_len
显示索引中使用的字节数,可通过key_len计算查询中使用的索引长度。在不损失精确性的情况下索引长度越短越好。key_len 显示的值为索引字段的最可能长度,并非实际使用长度,即key_len是根据表定义计算而得,并不是通过表内检索出的。
ref
显示索引的哪一列或常量被用于查找索引列上的值。
rows
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数,值越大越不好。
extra
Using filesort: 说明MySQL会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。MySQL中无法利用索引完成的排序操作称为“文件排序” 。出现这个就要立刻优化sql。 Using temporary: 使用了临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于排序 order by 和 分组查询 group by。 出现这个更要立刻优化sql。 Using index: 表示相应的select 操作中使用了覆盖索引(Covering index),避免访问了表的数据行,效果不错!如果同时出现Using where,表明索引被用来执行索引键值的查找。如果没有同时出现Using where,表示索引用来读取数据而非执行查找动作。 覆盖索引(Covering Index) :也叫索引覆盖,就是select 的数据列只用从索引中就能够取得,不必读取数据行,MySQL可以利用索引返回select 列表中的字段,而不必根据索引再次读取数据文件。 Using index condition: 在5.6版本后加入的新特性,优化器会在索引存在的情况下,通过符合RANGE范围的条数 和 总数的比例来选择是使用索引还是进行全表遍历。 Using where: 表明使用了where 过滤 Using join buffer: 表明使用了连接缓存 impossible where: where 语句的值总是false,不可用,不能用来获取任何元素 distinct: 优化distinct操作,在找到第一匹配的元组后即停止找同样值的动作。
filtered
一个百分比的值,和rows 列的值一起使用,可以估计出查询执行计划(QEP)中的前一个表的结果集,从而确定join操作的循环次数。小表驱动大表,减轻连接的次数。
通过explain的参数介绍,我们可以得知: 1 表的读取顺序(id) 2 数据读取操作的操作类型(type) 3 哪些索引被实际使用(key) 4 表之间的引用(ref) 5 每张表有多少行被优化器查询(rows)
性能下降的原因
从程序员的角度 1 查询语句写的不好 2 没建索引,索引建的不合理或索引失效 3 关联查询有太多的join 从服务器的角度 1 服务器磁盘空间不足 2 服务器调优配置参数设置不合理
总结
1 索引是排好序且快速查找的数据结构。其目的是为了提高查询的效率。 2 创建索引后,查询数据变快,但更新数据变慢。 3 性能下降的原因很可能是索引失效导致。 4 索引创建的原则,经常查询的字段适合创建索引,频繁需要更新的数据不适合创建索引。 5 索引字段频繁更新,或者表数据物理删除容易造成索引失效。 6 擅用 explain 分析sql语句 7 除了优化sql语句外,还可以优化表的设计。如尽量做成单表查询,减少表之间的关联。设计归档表等。
到这里,MySQL的索引优化分析就结束了,有什么不对的地方,大家可以提出来。如果觉得不错可以点一下推荐。
为什么Kafka速度那么快
Kafka的消息是保存或缓存在磁盘上的,一般认为在磁盘上读写数据是会降低性能的,因为寻址会比较消耗时间,但是实际上,Kafka的特性之一就是高吞吐率。
即使是普通的服务器,Kafka也可以轻松支持每秒百万级的写入请求,超过了大部分的消息中间件,这种特性也使得Kafka在日志处理等海量数据场景广泛应用。
针对Kafka的基准测试可以参考,Apache Kafka基准测试:每秒写入2百万(在三台廉价机器上)
下面从数据写入和读取两方面分析,为什么为什么Kafka速度这么快。
写入数据
Kafka会把收到的消息都写入到硬盘中,它绝对不会丢失数据。为了优化写入速度Kafka采用了两个技术, 顺序写入 和 MMFile 。
顺序写入
磁盘读写的快慢取决于你怎么使用它,也就是顺序读写或者随机读写。在顺序读写的情况下,某些优化场景磁盘的读写速度可以和内存持平(注:此处有疑问, 不推敲细节,参考 http://searene.me/2017/07/09/Why-is-Kafka-so-fast/ )。 因为硬盘是机械结构,每次读写都会寻址->写入,其中寻址是一个“机械动作”,它是最耗时的。所以硬盘最讨厌随机I/O,最喜欢顺序I/O。为了提高读写硬盘的速度,Kafka就是使用顺序I/O。
而且Linux对于磁盘的读写优化也比较多,包括read-ahead和write-behind,磁盘缓存等。如果在内存做这些操作的时候,一个是JAVA对象的内存开销很大,另一个是随着堆内存数据的增多,JAVA的GC时间会变得很长,使用磁盘操作有以下几个好处:
- 磁盘顺序读写速度超过内存随机读写
- JVM的GC效率低,内存占用大。使用磁盘可以避免这一问题
- 系统冷启动后,磁盘缓存依然可用

上图就展示了Kafka是如何写入数据的, 每一个Partition其实都是一个文件 ,收到消息后Kafka会把数据插入到文件末尾(虚框部分)。
这种方法有一个缺陷—— 没有办法删除数据 ,所以Kafka是不会删除数据的,它会把所有的数据都保留下来,每个消费者(Consumer)对每个Topic都有一个offset用来表示 读取到了第几条数据 。
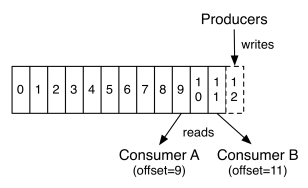
两个消费者,Consumer1有两个offset分别对应Partition0、Partition1(假设每一个Topic一个Partition);Consumer2有一个offset对应Partition2。这个offset是由客户端SDK负责保存的,Kafka的Broker完全无视这个东西的存在;一般情况下SDK会把它保存到zookeeper里面。(所以需要给Consumer提供zookeeper的地址)。
如果不删除硬盘肯定会被撑满,所以Kakfa提供了两种策略来删除数据。一是基于时间,二是基于partition文件大小。具体配置可以参看它的配置文档。
Memory Mapped Files
即便是顺序写入硬盘,硬盘的访问速度还是不可能追上内存。所以Kafka的数据并 不是实时的写入硬盘 ,它充分利用了现代操作系统 分页存储 来利用内存提高I/O效率。
Memory Mapped Files(后面简称mmap)也被翻译成 内存映射文件 ,在64位操作系统中一般可以表示20G的数据文件,它的工作原理是直接利用操作系统的Page来实现文件到物理内存的直接映射。完成映射之后你对物理内存的操作会被同步到硬盘上(操作系统在适当的时候)。
通过mmap,进程像读写硬盘一样读写内存(当然是虚拟机内存),也不必关心内存的大小有虚拟内存为我们兜底。
使用这种方式可以获取很大的I/O提升, 省去了用户空间到内核空间 复制的开销(调用文件的read会把数据先放到内核空间的内存中,然后再复制到用户空间的内存中。)也有一个很明显的缺陷——不可靠, 写到mmap中的数据并没有被真正的写到硬盘,操作系统会在程序主动调用flush的时候才把数据真正的写到硬盘。 Kafka提供了一个参数——producer.type来控制是不是主动flush,如果Kafka写入到mmap之后就立即flush然后再返回Producer叫 同步 (sync);写入mmap之后立即返回Producer不调用flush叫 异步 (async)。
读取数据
Kafka在读取磁盘时做了哪些优化?
基于sendfile实现Zero Copy
传统模式下,当需要对一个文件进行传输的时候,其具体流程细节如下:
- 调用read函数,文件数据被copy到内核缓冲区
- read函数返回,文件数据从内核缓冲区copy到用户缓冲区
- write函数调用,将文件数据从用户缓冲区copy到内核与socket相关的缓冲区。
- 数据从socket缓冲区copy到相关协议引擎。
以上细节是传统read/write方式进行网络文件传输的方式,我们可以看到,在这个过程当中,文件数据实际上是经过了四次copy操作:
硬盘—>内核buf—>用户buf—>socket相关缓冲区—>协议引擎
而sendfile系统调用则提供了一种减少以上多次copy,提升文件传输性能的方法。 在内核版本2.1中,引入了sendfile系统调用,以简化网络上和两个本地文件之间的数据传输。 sendfile的引入不仅减少了数据复制,还减少了上下文切换。
sendfile(socket, file, len);
运行流程如下:
- sendfile系统调用,文件数据被copy至内核缓冲区
- 再从内核缓冲区copy至内核中socket相关的缓冲区
- 最后再socket相关的缓冲区copy到协议引擎
相较传统read/write方式,2.1版本内核引进的sendfile已经减少了内核缓冲区到user缓冲区,再由user缓冲区到socket相关缓冲区的文件copy,而在内核版本2.4之后,文件描述符结果被改变,sendfile实现了更简单的方式,再次减少了一次copy操作。
在apache,nginx,lighttpd等web服务器当中,都有一项sendfile相关的配置,使用sendfile可以大幅提升文件传输性能。
Kafka把所有的消息都存放在一个一个的文件中,当消费者需要数据的时候Kafka直接把文件发送给消费者,配合mmap作为文件读写方式,直接把它传给sendfile。
批量压缩
在很多情况下,系统的瓶颈不是CPU或磁盘,而是网络IO,对于需要在广域网上的数据中心之间发送消息的数据流水线尤其如此。进行数据压缩会消耗少量的CPU资源,不过对于kafka而言,网络IO更应该需要考虑。
- 如果每个消息都压缩,但是压缩率相对很低,所以Kafka使用了批量压缩,即将多个消息一起压缩而不是单个消息压缩
- Kafka允许使用递归的消息集合,批量的消息可以通过压缩的形式传输并且在日志中也可以保持压缩格式,直到被消费者解压缩
- Kafka支持多种压缩协议,包括Gzip和Snappy压缩协议
总结
Kafka速度的秘诀在于,它把所有的消息都变成一个批量的文件,并且进行合理的批量压缩,减少网络IO损耗,通过mmap提高I/O速度,写入数据的时候由于单个Partion是末尾添加所以速度最优;读取数据的时候配合sendfile直接暴力输出。
系统运行缓慢,CPU 100%,以及Full GC次数过多问题的排查思路
前言
处理过线上问题的同学基本上都会遇到系统突然运行缓慢,CPU 100%,以及Full GC次数过多的问题。当然,这些问题的最终导致的直观现象就是系统运行缓慢,并且有大量的报警。
本文主要针对系统运行缓慢这一问题,提供该问题的排查思路,从而定位出问题的代码点,进而提供解决该问题的思路。
对于线上系统突然产生的运行缓慢问题,如果该问题导致线上系统不可用,那么首先需要做的就是,导出jstack和内存信息,然后重启系统,尽快保证系统的可用性。这种情况可能的原因主要有两种:
- 代码中某个位置读取数据量较大,导致系统内存耗尽,从而导致Full GC次数过多,系统缓慢;
- 代码中有比较耗CPU的操作,导致CPU过高,系统运行缓慢;
相对来说,这是出现频率最高的两种线上问题,而且它们会直接导致系统不可用。另外有几种情况也会导致某个功能运行缓慢,但是不至于导致系统不可用:
- 代码某个位置有阻塞性的操作,导致该功能调用整体比较耗时,但出现是比较随机的;
- 某个线程由于某种原因而进入WAITING状态,此时该功能整体不可用,但是无法复现;
- 由于锁使用不当,导致多个线程进入死锁状态,从而导致系统整体比较缓慢。
对于这三种情况,通过查看CPU和系统内存情况是无法查看出具体问题的,因为它们相对来说都是具有一定阻塞性操作,CPU和系统内存使用情况都不高,但是功能却很慢。下面我们就通过查看系统日志来一步一步甄别上述几种问题。
Full GC次数过多
相对来说,这种情况是最容易出现的,尤其是新功能上线时。对于Full GC较多的情况,其主要有如下两个特征:
- 线上多个线程的CPU都超过了100%,通过jstack命令可以看到这些线程主要是垃圾回收线程
- 通过jstat命令监控GC情况,可以看到Full GC次数非常多,并且次数在不断增加。
首先我们可以使用top命令查看系统CPU的占用情况,如下是系统CPU较高的一个示例:
top - 08:31:10 up 30 min, 0 users, load average: 0.73, 0.58, 0.34
KiB Mem: 2046460 total, 1923864 used, 122596 free, 14388 buffers
KiB Swap: 1048572 total, 0 used, 1048572 free. 1192352 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9 root 20 0 2557160 288976 15812 S 98.0 14.1 0:42.60 java
可以看到,有一个Java程序此时CPU占用量达到了98.8%,此时我们可以复制该进程id9,并且使用如下命令查看呢该进程的各个线程运行情况:
top -Hp 9
该进程下的各个线程运行情况如下:
top - 08:31:16 up 30 min, 0 users, load average: 0.75, 0.59, 0.35
Threads: 11 total, 1 running, 10 sleeping, 0 stopped, 0 zombie
%Cpu(s): 3.5 us, 0.6 sy, 0.0 ni, 95.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem: 2046460 total, 1924856 used, 121604 free, 14396 buffers
KiB Swap: 1048572 total, 0 used, 1048572 free. 1192532 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10 root 20 0 2557160 289824 15872 R 79.3 14.2 0:41.49 java
11 root 20 0 2557160 289824 15872 S 13.2 14.2 0:06.78 java
可以看到,在进程为9的Java程序中各个线程的CPU占用情况,接下来我们可以通过jstack命令查看线程id为10的线程为什么耗费CPU最高。需要注意的是,在jsatck命令展示的结果中,线程id都转换成了十六进制形式。可以用如下命令查看转换结果,也可以找一个科学计算器进行转换:
root@a39de7e7934b:/# printf "%x\n" 10
a
这里打印结果说明该线程在jstack中的展现形式为0xa,通过jstack命令我们可以看到如下信息:
"main" #1 prio=5 os_prio=0 tid=0x00007f8718009800 nid=0xb runnable [0x00007f871fe41000]
java.lang.Thread.State: RUNNABLE
at com.aibaobei.chapter2.eg2.UserDemo.main(UserDemo.java:9)
"VM Thread" os_prio=0 tid=0x00007f871806e000 nid=0xa runnable
这里的VM Thread一行的最后显示nid=0xa,这里nid的意思就是操作系统线程id的意思。而VM Thread指的就是垃圾回收的线程。这里我们基本上可以确定,当前系统缓慢的原因主要是垃圾回收过于频繁,导致GC停顿时间较长。我们通过如下命令可以查看GC的情况:
root@8d36124607a0:/# jstat -gcutil 9 1000 10
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 0.00 0.00 75.07 59.09 59.60 3259 0.919 6517 7.715 8.635
0.00 0.00 0.00 0.08 59.09 59.60 3306 0.930 6611 7.822 8.752
0.00 0.00 0.00 0.08 59.09 59.60 3351 0.943 6701 7.924 8.867
0.00 0.00 0.00 0.08 59.09 59.60 3397 0.955 6793 8.029 8.984
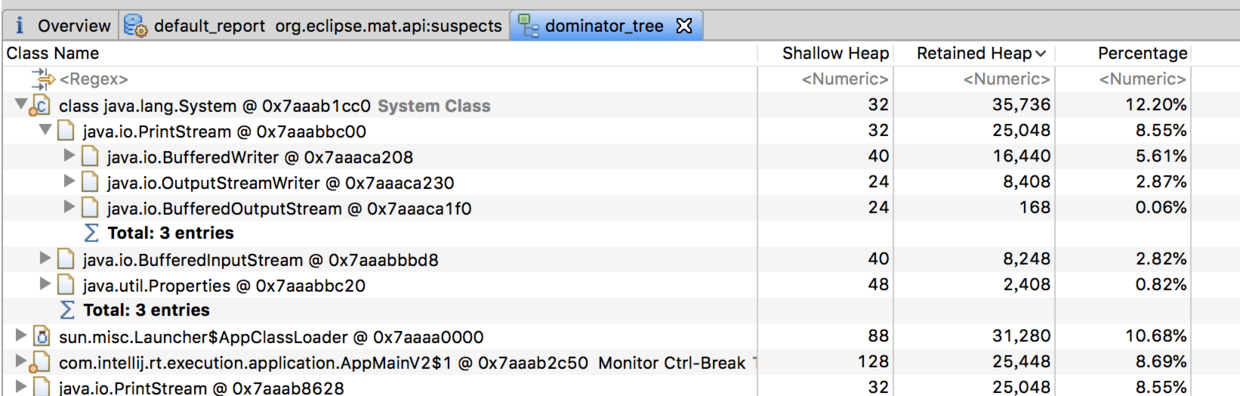
可以看到,这里FGC指的是Full GC数量,这里高达6793,而且还在不断增长。从而进一步证实了是由于内存溢出导致的系统缓慢。那么这里确认了内存溢出,但是如何查看你是哪些对象导致的内存溢出呢,这个可以dump出内存日志,然后通过eclipse的mat工具进行查看,如下是其展示的一个对象树结构:
经过mat工具分析之后,我们基本上就能确定内存中主要是哪个对象比较消耗内存,然后找到该对象的创建位置,进行处理即可。这里的主要是PrintStream最多,但是我们也可以看到,其内存消耗量只有12.2%。也就是说,其还不足以导致大量的Full GC,此时我们需要考虑另外一种情况,就是代码或者第三方依赖的包中有显示的System.gc()调用。这种情况我们查看dump内存得到的文件即可判断,因为其会打印GC原因:
[Full GC (System.gc()) [Tenured: 262546K->262546K(349568K), 0.0014879 secs] 262546K->262546K(506816K), [Metaspace: 3109K->3109K(1056768K)], 0.0015151 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
[GC (Allocation Failure) [DefNew: 2795K->0K(157248K), 0.0001504 secs][Tenured: 262546K->402K(349568K), 0.0012949 secs] 265342K->402K(506816K), [Metaspace: 3109K->3109K(1056768K)], 0.0014699 secs] [Times: user=0.00
比如这里第一次GC是由于System.gc()的显示调用导致的,而第二次GC则是JVM主动发起的。总结来说,对于Full GC次数过多,主要有以下两种原因:
- 代码中一次获取了大量的对象,导致内存溢出,此时可以通过eclipse的mat工具查看内存中有哪些对象比较多;
- 内存占用不高,但是Full GC次数还是比较多,此时可能是显示的
System.gc()调用导致GC次数过多,这可以通过添加-XX:+DisableExplicitGC来禁用JVM对显示GC的响应。
CPU过高
在前面第一点中,我们讲到,CPU过高可能是系统频繁的进行Full GC,导致系统缓慢。而我们平常也肯能遇到比较耗时的计算,导致CPU过高的情况,此时查看方式其实与上面的非常类似。首先我们通过top命令查看当前CPU消耗过高的进程是哪个,从而得到进程id;然后通过top -Hp 来查看该进程中有哪些线程CPU过高,一般超过80%就是比较高的,80%左右是合理情况。这样我们就能得到CPU消耗比较高的线程id。接着通过该线程id的十六进制表示在jstack日志中查看当前线程具体的堆栈信息。
在这里我们就可以区分导致CPU过高的原因具体是Full GC次数过多还是代码中有比较耗时的计算了。如果是Full GC次数过多,那么通过jstack得到的线程信息会是类似于VM Thread之类的线程,而如果是代码中有比较耗时的计算,那么我们得到的就是一个线程的具体堆栈信息。如下是一个代码中有比较耗时的计算,导致CPU过高的线程信息:

这里可以看到,在请求UserController的时候,由于该Controller进行了一个比较耗时的调用,导致该线程的CPU一直处于100%。我们可以根据堆栈信息,直接定位到UserController的34行,查看代码中具体是什么原因导致计算量如此之高。
不定期出现的接口耗时现象
对于这种情况,比较典型的例子就是,我们某个接口访问经常需要2~3s才能返回。这是比较麻烦的一种情况,因为一般来说,其消耗的CPU不多,而且占用的内存也不高,也就是说,我们通过上述两种方式进行排查是无法解决这种问题的。而且由于这样的接口耗时比较大的问题是不定时出现的,这就导致了我们在通过jstack命令即使得到了线程访问的堆栈信息,我们也没法判断具体哪个线程是正在执行比较耗时操作的线程。
对于不定时出现的接口耗时比较严重的问题,我们的定位思路基本如下:首先找到该接口,通过压测工具不断加大访问力度,如果说该接口中有某个位置是比较耗时的,由于我们的访问的频率非常高,那么大多数的线程最终都将阻塞于该阻塞点,这样通过多个线程具有相同的堆栈日志,我们基本上就可以定位到该接口中比较耗时的代码的位置。如下是一个代码中有比较耗时的阻塞操作通过压测工具得到的线程堆栈日志:
"http-nio-8080-exec-2" #29 daemon prio=5 os_prio=31 tid=0x00007fd08cb26000 nid=0x9603 waiting on condition [0x00007000031d5000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at java.lang.Thread.sleep(Thread.java:340)
at java.util.concurrent.TimeUnit.sleep(TimeUnit.java:386)
at com.aibaobei.user.controller.UserController.detail(UserController.java:18)
"http-nio-8080-exec-3" #30 daemon prio=5 os_prio=31 tid=0x00007fd08cb27000 nid=0x6203 waiting on condition [0x00007000032d8000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at java.lang.Thread.sleep(Thread.java:340)
at java.util.concurrent.TimeUnit.sleep(TimeUnit.java:386)
at com.aibaobei.user.controller.UserController.detail(UserController.java:18)
"http-nio-8080-exec-4" #31 daemon prio=5 os_prio=31 tid=0x00007fd08d0fa000 nid=0x6403 waiting on condition [0x00007000033db000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at java.lang.Thread.sleep(Thread.java:340)
at java.util.concurrent.TimeUnit.sleep(TimeUnit.java:386)
at com.aibaobei.user.controller.UserController.detail(UserController.java:18)
从上面的日志可以看你出,这里有多个线程都阻塞在了UserController的第18行,说明这是一个阻塞点,也就是导致该接口比较缓慢的原因。
某个线程进入WAITING状态
对于这种情况,这是比较罕见的一种情况,但是也是有可能出现的,而且由于其具有一定的“不可复现性”,因而我们在排查的时候是非常难以发现的。笔者曾经就遇到过类似的这种情况,具体的场景是,在使用CountDownLatch时,由于需要每一个并行的任务都执行完成之后才会唤醒主线程往下执行。而当时我们是通过CountDownLatch控制多个线程连接并导出用户的gmail邮箱数据,这其中有一个线程连接上了用户邮箱,但是连接被服务器挂起了,导致该线程一直在等待服务器的响应。最终导致我们的主线程和其余几个线程都处于WAITING状态。
对于这样的问题,查看过jstack日志的读者应该都知道,正常情况下,线上大多数线程都是处于TIMED_WAITING状态,而我们这里出问题的线程所处的状态与其是一模一样的,这就非常容易混淆我们的判断。解决这个问题的思路主要如下:
- 通过grep在jstack日志中找出所有的处于TIMED_WAITING状态的线程,将其导出到某个文件中,如a1.log,如下是一个导出的日志文件示例:
"Attach Listener" #13 daemon prio=9 os_prio=31 tid=0x00007fe690064000 nid=0xd07 waiting on condition [0x0000000000000000]
"DestroyJavaVM" #12 prio=5 os_prio=31 tid=0x00007fe690066000 nid=0x2603 waiting on condition [0x0000000000000000]
"Thread-0" #11 prio=5 os_prio=31 tid=0x00007fe690065000 nid=0x5a03 waiting on condition [0x0000700003ad4000]
"C1 CompilerThread3" #9 daemon prio=9 os_prio=31 tid=0x00007fe68c00a000 nid=0xa903 waiting on condition [0x0000000000000000]
- 等待一段时间之后,比如10s,再次对jstack日志进行grep,将其导出到另一个文件,如a2.log,结果如下所示:
"DestroyJavaVM" #12 prio=5 os_prio=31 tid=0x00007fe690066000 nid=0x2603 waiting on condition [0x0000000000000000]
"Thread-0" #11 prio=5 os_prio=31 tid=0x00007fe690065000 nid=0x5a03 waiting on condition [0x0000700003ad4000]
"VM Periodic Task Thread" os_prio=31 tid=0x00007fe68d114000 nid=0xa803 waiting on condition
- 重复步骤2,待导出3~4个文件之后,我们对导出的文件进行对比,找出其中在这几个文件中一直都存在的用户线程,这个线程基本上就可以确认是包含了处于等待状态有问题的线程。因为正常的请求线程是不会在20~30s之后还是处于等待状态的。
- 经过排查得到这些线程之后,我们可以继续对其堆栈信息进行排查,如果该线程本身就应该处于等待状态,比如用户创建的线程池中处于空闲状态的线程,那么这种线程的堆栈信息中是不会包含用户自定义的类的。这些都可以排除掉,而剩下的线程基本上就可以确认是我们要找的有问题的线程。通过其堆栈信息,我们就可以得出具体是在哪个位置的代码导致该线程处于等待状态了。
这里需要说明的是,我们在判断是否为用户线程时,可以通过线程最前面的线程名来判断,因为一般的框架的线程命名都是非常规范的,我们通过线程名就可以直接判断得出该线程是某些框架中的线程,这种线程基本上可以排除掉。而剩余的,比如上面的Thread-0,以及我们可以辨别的自定义线程名,这些都是我们需要排查的对象。
经过上面的方式进行排查之后,我们基本上就可以得出这里的Thread-0就是我们要找的线程,通过查看其堆栈信息,我们就可以得到具体是在哪个位置导致其处于等待状态了。如下示例中则是在SyncTask的第8行导致该线程进入等待了。
"Thread-0" #11 prio=5 os_prio=31 tid=0x00007f9de08c7000 nid=0x5603 waiting on condition [0x0000700001f89000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:304)
at com.aibaobei.chapter2.eg4.SyncTask.lambda$main$0(SyncTask.java:8)
at com.aibaobei.chapter2.eg4.SyncTask$$Lambda$1/1791741888.run(Unknown Source)
at java.lang.Thread.run(Thread.java:748)
死锁
对于死锁,这种情况基本上很容易发现,因为jstack可以帮助我们检查死锁,并且在日志中打印具体的死锁线程信息。如下是一个产生死锁的一个jstack日志示例:

可以看到,在jstack日志的底部,其直接帮我们分析了日志中存在哪些死锁,以及每个死锁的线程堆栈信息。这里我们有两个用户线程分别在等待对方释放锁,而被阻塞的位置都是在ConnectTask的第5行,此时我们就可以直接定位到该位置,并且进行代码分析,从而找到产生死锁的原因。
小结
本文主要讲解了线上可能出现的五种导致系统缓慢的情况,详细分析了每种情况产生时的现象,已经根据现象我们可以通过哪些方式定位得到是这种原因导致的系统缓慢。简要的说,我们进行线上日志分析时,主要可以分为如下步骤:
- 通过top命令查看CPU情况,如果CPU比较高,则通过top -Hp 命令查看当前进程的各个线程运行情况,找出CPU过高的线程之后,将其线程id转换为十六进制的表现形式,然后在jstack日志中查看该线程主要在进行的工作。这里又分为两种情况:
- 如果是正常的用户线程,则通过该线程的堆栈信息查看其具体是在哪处用户代码处运行比较消耗CPU;
- 如果该线程是VM Thread,则通过
jstat -gcutil <pid> <period> <times>命令监控当前系统的GC状况,然后通过jmap dump:format=b,file=<filepath> <pid>导出系统当前的内存数据。导出之后将内存情况放到eclipse的mat工具中进行分析即可得出内存中主要是什么对象比较消耗内存,进而可以处理相关代码;
- 如果通过top命令看到CPU并不高,并且系统内存占用率也比较低。此时就可以考虑是否是由于另外三种情况导致的问题。具体的可以根据具体情况分析:
- 如果是接口调用比较耗时,并且是不定时出现,则可以通过压测的方式加大阻塞点出现的频率,从而通过jstack查看堆栈信息,找到阻塞点;
- 如果是某个功能突然出现停滞的状况,这种情况也无法复现,此时可以通过多次导出jstack日志的方式对比哪些用户线程是一直都处于等待状态,这些线程就是可能存在问题的线程;
- 如果通过jstack可以查看到死锁状态,则可以检查产生死锁的两个线程的具体阻塞点,从而处理相应的问题。
本文主要是提出了五种常见的导致线上功能缓慢的问题,以及排查思路。当然,线上的问题出现的形式是多种多样的,也不一定局限于这几种情况,如果我们能够仔细分析这些问题出现的场景,就可以根据具体情况具体分析,从而解决相应的问题。
339 post articles, 43 pages.