Java集合之LinkedHashMap
一、初识LinkedHashMap
上篇文章讲了HashMap。HashMap是一种非常常见、非常有用的集合,但在多线程情况下使用不当会有线程安全问题。
大多数情况下,只要不涉及线程安全问题,Map基本都可以使用HashMap,不过HashMap有一个问题,就是迭代HashMap的顺序并不是HashMap放置的顺序,也就是无序。HashMap的这一缺点往往会带来困扰,因为有些场景,我们期待一个有序的Map。
这个时候,LinkedHashMap就闪亮登场了,它虽然增加了时间和空间上的开销,但是通过维护一个运行于所有条目的双向链表,LinkedHashMap保证了元素迭代的顺序。该迭代顺序可以是插入顺序或者是访问顺序。
二、四个关注点在LinkedHashMap上的答案
| 关 注 点 | 结 论 |
|---|---|
| LinkedHashMap是否允许空 | Key和Value都允许空 |
| LinkedHashMap是否允许重复数据 | Key重复会覆盖、Value允许重复 |
| LinkedHashMap是否有序 | 有序 |
| LinkedHashMap是否线程安全 | 非线程安全 |
三、LinkedHashMap基本结构
关于LinkedHashMap,先提两点:
1、LinkedHashMap可以认为是HashMap+LinkedList,即它既使用HashMap操作数据结构,又使用LinkedList维护插入元素的先后顺序。
2、LinkedHashMap的基本实现思想就是—-多态。可以说,理解多态,再去理解LinkedHashMap原理会事半功倍;反之也是,对于LinkedHashMap原理的学习,也可以促进和加深对于多态的理解。
为什么可以这么说,首先看一下,LinkedHashMap的定义:
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
{
...
}
看到,LinkedHashMap是HashMap的子类,自然LinkedHashMap也就继承了HashMap中所有非private的方法。再看一下LinkedHashMap中本身的方法:
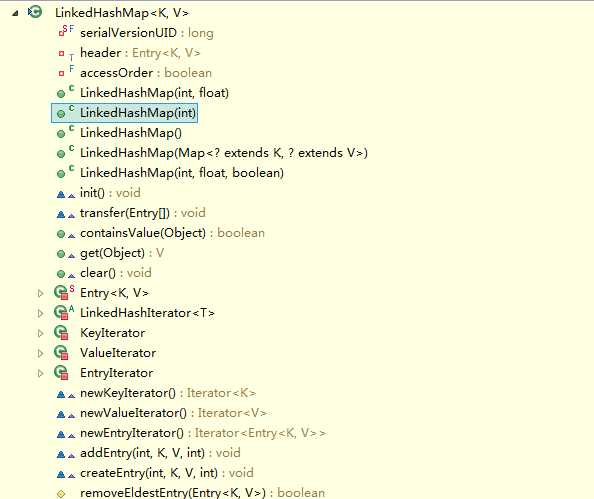
看到LinkedHashMap中并没有什么操作数据结构的方法,也就是说LinkedHashMap操作数据结构(比如put一个数据),和HashMap操作数据的方法完全一样,无非就是细节上有一些的不同罢了。
LinkedHashMap只定义了两个属性:
/**
* The head of the doubly linked list.
* 双向链表的头节点
*/
private transient Entry<K,V> header;
/**
* The iteration ordering method for this linked hash map: true
* for access-order, false for insertion-order.
* true表示最近最少使用次序,false表示插入顺序
*/
private final boolean accessOrder;
LinkedHashMap一共提供了五个构造方法:
// 构造方法1,构造一个指定初始容量和负载因子的、按照插入顺序的LinkedList
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
// 构造方法2,构造一个指定初始容量的LinkedHashMap,取得键值对的顺序是插入顺序
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
// 构造方法3,用默认的初始化容量和负载因子创建一个LinkedHashMap,取得键值对的顺序是插入顺序
public LinkedHashMap() {
super();
accessOrder = false;
}
// 构造方法4,通过传入的map创建一个LinkedHashMap,容量为默认容量(16)和(map.zise()/DEFAULT_LOAD_FACTORY)+1的较大者,装载因子为默认值
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super(m);
accessOrder = false;
}
// 构造方法5,根据指定容量、装载因子和键值对保持顺序创建一个LinkedHashMap
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
从构造方法中可以看出,默认都采用插入顺序来维持取出键值对的次序。所有构造方法都是通过调用父类的构造方法来创建对象的。
LinkedHashMap和HashMap的区别在于它们的基本数据结构上,看一下LinkedHashMap的基本数据结构,也就是Entry:
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
...
}
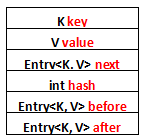
列一下Entry里面有的一些属性吧:
1、K key
2、V value
3、Entry<K, V> next
4、int hash
5、Entry<K, V> before
6、Entry<K, V> after
其中前面四个,也就是红色部分是从HashMap.Entry中继承过来的;后面两个,也就是蓝色部分是LinkedHashMap独有的。不要搞错了next和before、After,next是用于维护HashMap指定table位置上连接的Entry的顺序的,before、After是用于维护Entry插入的先后顺序的。
还是用图表示一下,列一下属性而已:
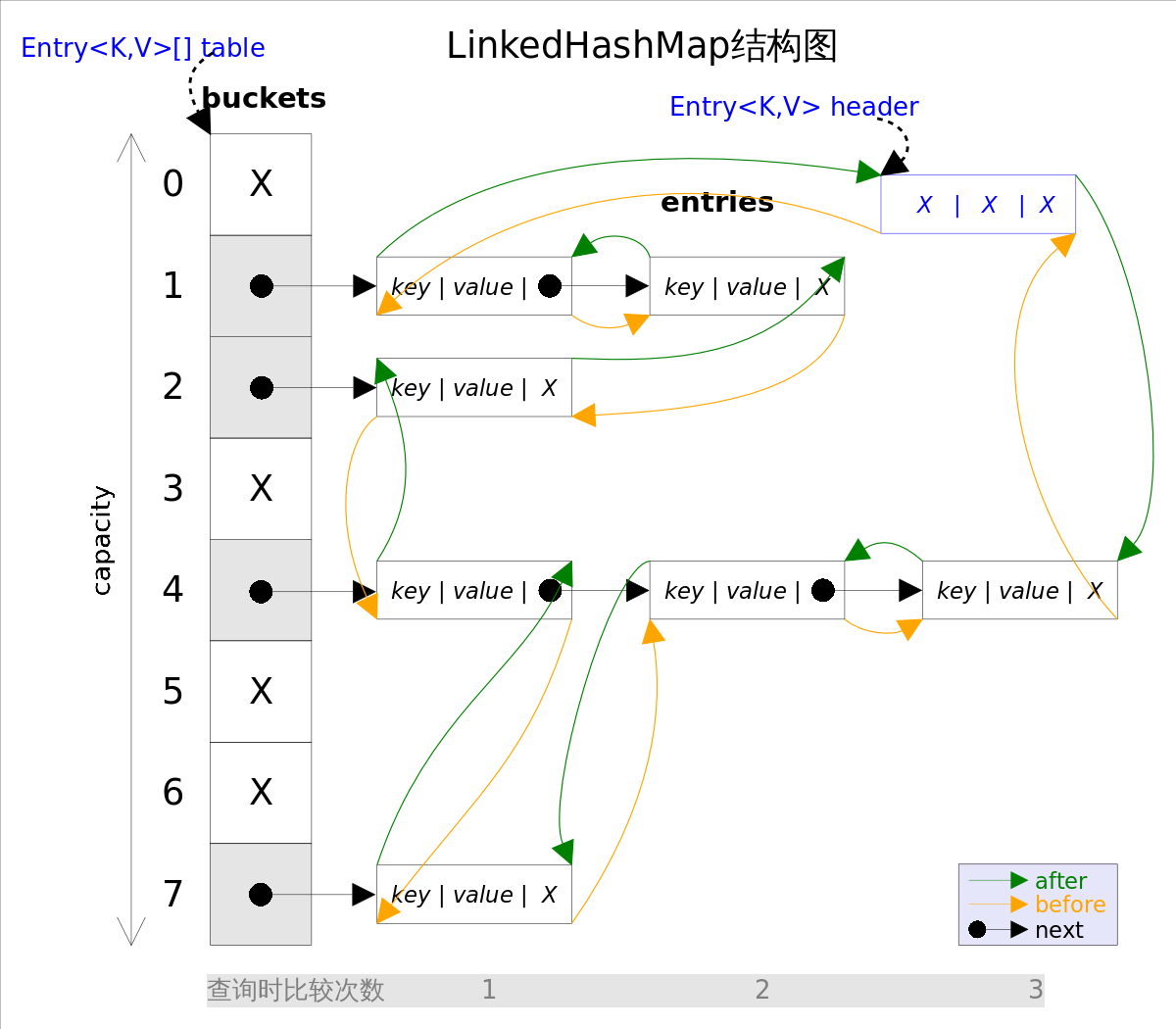

第一张图为LinkedHashMap整体结构图,第二张图专门把循环双向链表抽取出来,直观一点,注意该循环双向链表的头部存放的是最久访问的节点或最先插入的节点,尾部为最近访问的或最近插入的节点,迭代器遍历方向是从链表的头部开始到链表尾部结束,在链表尾部有一个空的header节点,该节点不存放key-value内容,为LinkedHashMap类的成员属性,循环双向链表的入口。
四、初始化LinkedHashMap
假如有这么一段代码:
public static void main(String[] args)
{
LinkedHashMap<String, String> linkedHashMap =
new LinkedHashMap<String, String>();
linkedHashMap.put("111", "111");
linkedHashMap.put("222", "222");
}
首先是第3行~第4行,new一个LinkedHashMap出来,看一下做了什么:
通过源代码可以看出,在LinkedHashMap的构造方法中,实际调用了父类HashMap的相关构造方法来构造一个底层存放的table数组。
public LinkedHashMap() {
super();
accessOrder = false;
}
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
}
我们已经知道LinkedHashMap的Entry元素继承HashMap的Entry,提供了双向链表的功能。在上述HashMap的构造器中,最后会调用init()方法,进行相关的初始化,这个方法在HashMap的实现中并无意义,只是提供给子类实现相关的初始化调用。 LinkedHashMap重写了init()方法,在调用父类的构造方法完成构造后,进一步实现了对其元素Entry的初始化操作。
void init() {
header = new Entry<K,V>(-1, null, null, null);
header.before = header.after = header;
}
这里出现了第一个多态:init()方法。尽管init()方法定义在HashMap中,但是由于:
1、LinkedHashMap重写了init方法
2、实例化出来的是LinkedHashMap
因此实际调用的init方法是LinkedHashMap重写的init方法。假设header的地址是0x00000000,那么初始化完毕,实际上是这样的:

注意这个header,hash值为-1,其他都为null,也就是说这个header不放在数组中,就是用来指示开始元素和标志结束元素的。
header的目的是为了记录第一个插入的元素是谁,在遍历的时候能够找到第一个元素。
五、LinkedHashMap存储元素
LinkedHashMap并未重写父类HashMap的put方法,而是重写了父类HashMap的put方法调用的子方法void recordAccess(HashMap m) ,void addEntry(int hash, K key, V value, int bucketIndex) 和void createEntry(int hash, K key, V value, int bucketIndex),提供了自己特有的双向链接列表的实现。
继续看LinkedHashMap存储元素,也就是put(“111”,”111”)做了什么,首先当然是调用HashMap的put方法:
//这个方法应该挺熟悉的,如果看了HashMap的解析的话
public V put(K key, V value) {
//key为null的情况
if (key == null)
return putForNullKey(value);
//通过key算hash,进而算出在数组中的位置,也就是在第几个桶中
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//查看桶中是否有相同的key值,如果有就直接用新值替换旧值,而不用再创建新的entry了
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//上面度是熟悉的东西,最重要的地方来了,就是这个方法,LinkedHashMap执行到这里,addEntry()方法不会执行HashMap中的方法,
//而是执行自己类中的addEntry方法,
addEntry(hash, key, value, i);
return null;
}
第23行又是一个多态,因为LinkedHashMap重写了addEntry方法,因此addEntry调用的是LinkedHashMap重写了的方法:
void addEntry(int hash, K key, V value, int bucketIndex) {
//调用create方法,将新元素以双向链表的的形式加入到映射中
createEntry(hash, key, value, bucketIndex);
// Remove eldest entry if instructed, else grow capacity if appropriate
// 删除最近最少使用元素的策略定义
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
} else {
if (size >= threshold)
resize(2 * table.length);
}
}
因为LinkedHashMap由于其本身维护了插入的先后顺序,因此LinkedHashMap可以用来做缓存,第7行~第9行是用来支持FIFO算法的,这里暂时不用去关心它。看一下createEntry方法:
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<K,V>(hash, key, value, old);
table[bucketIndex] = e;
//将该节点插入到链表尾部
e.addBefore(header);
size++;
}
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
createEntry(int hash,K key,V value,int bucketIndex)方法覆盖了父类HashMap中的方法。这个方法不会拓展table数组的大小。该方法首先保留table中bucketIndex处的节点,然后调用Entry的构造方法(将调用到父类HashMap.Entry的构造方法)添加一个节点,即将当前节点的next引用指向table[bucketIndex] 的节点,之后调用的e.addBefore(header)是修改链表,将e节点添加到header节点之前。
第2行~第4行的代码和HashMap没有什么不同,新添加的元素放在table[i]上,差别在于LinkedHashMap还做了addBefore操作,这四行代码的意思就是让新的Entry和原链表生成一个双向链表。假设字符串111放在位置table[1]上,生成的Entry地址为0x00000001,那么用图表示是这样的:

如果熟悉LinkedList的源码应该不难理解,还是解释一下,注意下existingEntry表示的是header:
1、after=existingEntry,即新增的Entry的after=header地址,即after=0x00000000
2、before=existingEntry.before,即新增的Entry的before是header的before的地址,header的before此时是0x00000000,因此新增的Entry的before=0x00000000
3、before.after=this,新增的Entry的before此时为0x00000000即header,header的after=this,即header的after=0x00000001
4、after.before=this,新增的Entry的after此时为0x00000000即header,header的before=this,即header的before=0x00000001
这样,header与新增的Entry的一个双向链表就形成了。再看,新增了字符串222之后是什么样的,假设新增的Entry的地址为0x00000002,生成到table[2]上,用图表示是这样的:
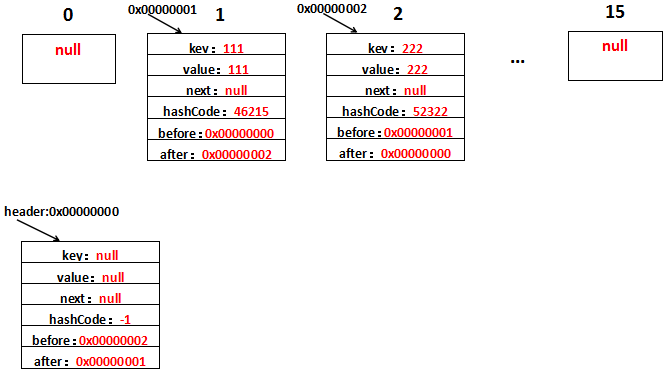
就不细解释了,只要before、after清除地知道代表的是哪个Entry的就不会有什么问题。
注意,这里的插入有两重含义:
1.从table的角度看,新的entry需要插入到对应的bucket里,当有哈希冲突时,采用头插法将新的entry插入到冲突链表的头部。 2.从header的角度看,新的entry需要插入到双向链表的尾部。
总得来看,再说明一遍,LinkedHashMap的实现就是HashMap+LinkedList的实现方式,以HashMap维护数据结构,以LinkList的方式维护数据插入顺序。
六、LinkedHashMap读取元素
LinkedHashMap重写了父类HashMap的get方法,实际在调用父类getEntry()方法取得查找的元素后,再判断当排序模式accessOrder为true时(即按访问顺序排序),先将当前节点从链表中移除,然后再将当前节点插入到链表尾部。由于的链表的增加、删除操作是常量级的,故并不会带来性能的损失。
/**
* 通过key获取value,与HashMap的区别是:当LinkedHashMap按访问顺序排序的时候,会将访问的当前节点移到链表尾部(头结点的前一个节点)
*/
public V get(Object key) {
// 调用父类HashMap的getEntry()方法,取得要查找的元素。
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
// 记录访问顺序。
e.recordAccess(this);
return e.value;
}
/**
* 在HashMap的put和get方法中,会调用该方法,在HashMap中该方法为空
* 在LinkedHashMap中,当按访问顺序排序时,该方法会将当前节点插入到链表尾部(头结点的前一个节点),否则不做任何事
*/
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//当LinkedHashMap按访问排序时
if (lm.accessOrder) {
lm.modCount++;
//移除当前节点
remove();
//将当前节点插入到头结点前面
addBefore(lm.header);
}
}
/**
* 移除节点,并修改前后引用
*/
private void remove() {
before.after = after;
after.before = before;
}
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
七、利用LinkedHashMap实现LRU算法缓存
前面讲了LinkedHashMap添加元素,删除、修改元素就不说了,比较简单,和HashMap+LinkedList的删除、修改元素大同小异,下面讲一个新的内容。
LinkedHashMap可以用来作缓存,比方说LRUCache,看一下这个类的代码,很简单,就十几行而已:
public class LRUCache extends LinkedHashMap
{
public LRUCache(int maxSize)
{
super(maxSize, 0.75F, true);
maxElements = maxSize;
}
protected boolean removeEldestEntry(java.util.Map.Entry eldest)
{
return size() > maxElements;
}
private static final long serialVersionUID = 1L;
protected int maxElements;
}
顾名思义,LRUCache就是基于LRU算法的Cache(缓存),这个类继承自LinkedHashMap,而类中看到没有什么特别的方法,这说明LRUCache实现缓存LRU功能都是源自LinkedHashMap的。LinkedHashMap可以实现LRU算法的缓存基于两点:
1、LinkedList首先它是一个Map,Map是基于K-V的,和缓存一致
2、LinkedList提供了一个boolean值可以让用户指定是否实现LRU
那么,首先我们了解一下什么是LRU:LRU即Least Recently Used,最近最少使用,也就是说,当缓存满了,会优先淘汰那些最近最不常访问的数据。比方说数据a,1天前访问了;数据b,2天前访问了,缓存满了,优先会淘汰数据b。
我们看一下LinkedList带boolean型参数的构造方法:
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
就是这个accessOrder,它表示:
(1)false,所有的Entry按照插入的顺序排列
(2)true,所有的Entry按照访问的顺序排列
第二点的意思就是,如果有1 2 3这3个Entry,那么访问了1,就把1移到尾部去,即2 3 1。每次访问都把访问的那个数据移到双向队列的尾部去,那么每次要淘汰数据的时候,双向队列最头的那个数据不就是最不常访问的那个数据了吗?换句话说,双向链表最头的那个数据就是要淘汰的数据。
“访问”,这个词有两层意思:
1、根据Key拿到Value,也就是get方法
2、修改Key对应的Value,也就是put方法
首先看一下get方法,它在LinkedHashMap中被重写:
public V get(Object key) {
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
e.recordAccess(this);
return e.value;
}
然后是put方法,沿用父类HashMap的:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
修改数据也就是第6行~第14行的代码。看到两端代码都有一个共同点:都调用了recordAccess方法,且这个方法是Entry中的方法,也就是说每次的recordAccess操作的都是某一个固定的Entry。
recordAccess,顾名思义,记录访问,也就是说你这次访问了双向链表,我就把你记录下来,怎么记录?把你访问的Entry移到尾部去。这个方法在HashMap中是一个空方法,就是用来给子类记录访问用的,看一下LinkedHashMap中的实现:
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}
private void remove() {
before.after = after;
after.before = before;
}
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
看到每次recordAccess的时候做了两件事情:
1、把待移动的Entry的前后Entry相连
2、把待移动的Entry移动到尾部
当然,这一切都是基于accessOrder=true的情况下。最后用一张图表示一下整个recordAccess的过程吧:

void recordAccess(HashMap<K,V> m) 这个方法就是我们一开始说的,accessOrder为true时,就是使用的访问顺序,访问次数最少到访问次数最多,此时要做特殊处理。处理机制就是访问了一次,就将自己往后移一位,这里就是先将自己删除了,然后在把自己添加,这样,近期访问的少的就在链表的开始,最近访问的元素就会在链表的末尾。如果为false。那么默认就是插入顺序,直接通过链表的特点就能依次找到插入元素,不用做特殊处理。
八、代码演示LinkedHashMap按照访问顺序排序的效果
最后代码演示一下LinkedList按照访问顺序排序的效果,验证一下上一部分LinkedHashMap的LRU功能:
public static void main(String[] args)
{
LinkedHashMap<String, String> linkedHashMap =
new LinkedHashMap<String, String>(16, 0.75f, true);
linkedHashMap.put("111", "111");
linkedHashMap.put("222", "222");
linkedHashMap.put("333", "333");
linkedHashMap.put("444", "444");
loopLinkedHashMap(linkedHashMap);
linkedHashMap.get("111");
loopLinkedHashMap(linkedHashMap);
linkedHashMap.put("222", "2222");
loopLinkedHashMap(linkedHashMap);
}
public static void loopLinkedHashMap(LinkedHashMap<String, String> linkedHashMap)
{
Set<Map.Entry<String, String>> set = inkedHashMap.entrySet();
Iterator<Map.Entry<String, String>> iterator = set.iterator();
while (iterator.hasNext())
{
System.out.print(iterator.next() + "\t");
}
System.out.println();
}
注意这里的构造方法要用三个参数那个且最后的要传入true,这样才表示按照访问顺序排序。看一下代码运行结果:
111=111 222=222 333=333 444=444
222=222 333=333 444=444 111=111
333=333 444=444 111=111 222=2222
代码运行结果证明了两点:
1、LinkedList是有序的
2、每次访问一个元素(get或put),被访问的元素都被提到最后面去了
Java 枚举(enum) 详解五种常见的用法
一、枚举型常量
package com.yang;
//首先枚举是一个特殊的class
//这个class相当于final static修饰,不能被继承
//他的构造方法强制被私有化,下面有一个默认的构造方法private ColorEnum();
//所有的枚举都继承自java.lang.Enum类。由于Java 不支持多继承,所以枚举对象不能再继承其他类
public enum ColorEnum {
//每个枚举变量都是枚举类ColorEnum的实例,相当于RED=new ColorEnum(1),按序号来。
//每个成员变量都是final static修饰
RED, GREEN, BLANK, YELLOW;
}
测试类:
@org.junit.Test
public void ColorTest() {
//ordinal返回枚举变量的序号
for(ColorEnum color:ColorEnum.values()) {
System.out.println(color+",ordinal:"+color.ordinal()+",name:"+color.name());
}
}
二、带一个参数的枚举
package com.yang;
public enum TypeEnum {
FIREWALL("firewall"),
SECRET("secretMac"),
BALANCE("f5");
private String typeName;
TypeEnum(String typeName) {
this.typeName = typeName;
}
/**
* 根据类型的名称,返回类型的枚举实例。
*
* @param typeName 类型名称
*/
public static TypeEnum fromTypeName(String typeName) {
for (TypeEnum type : TypeEnum.values()) {
if (type.getTypeName().equals(typeName)) {
return type;
}
}
return null;
}
public String getTypeName() {
return this.typeName;
}
}
测试类:
@org.junit.Test
public void TypeTest() {
String typeName = "f5";
TypeEnum type = TypeEnum.fromTypeName(typeName);
//type:是TypeEnum类实例化对象 typeName:实例化对象type的值
// ordinal:实例化对象type的序号(int) 排序值(默认自带的属性 ordinal 的值)
//name:实化对象的名字(String) 枚举名称(即默认自带的属性 name 的值)
System.out.println(type+",typeName:"+type.getTypeName()+",ordinal:"+type.ordinal()+",name:"+type.name());
}
三、向枚举中添加新方法
package com.yang;
public enum SeasonEunm {
//每一个枚举变量都是枚举类SeasonEunm的实例化
//SeasonEunm.SPRING获得的对象相当于new SeasonEunm("春","春困");获得的对象
SPRING("春","春困"),SUMMER("夏","夏睡"),AUTUMN("秋","秋乏"),WINTER("冬","冬眠");
//强制私有化的构造方法,因为枚举类默认继承Eunm类,被final static修饰,不能被继承
//由于被强制private,所以不能使用new去生成枚举对象
//在SeasonEunm.SPRING获得对象,隐式调用了下面的构造方法
// 构造方法 ,赋值给成员变量
private SeasonEunm(String name, String value) {
this.name = name;
this.value = value;
}
//添加成员变量的原因是,方便够着方法赋值,使用SeasonEunm.SPRING.getName就能获取对应的值
private String name;
private String value;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
}
测试类:
@org.junit.Test
public void SessionTest() {
//ordinal返回枚举变量的序号
for(SeasonEunm seasion:SeasonEunm.values()) {
System.out.println(seasion+",ordinal:"+seasion.ordinal()+",name:"+seasion.name());
System.out.println("枚举变量值:"+seasion.getName()+",枚举变量值:"+seasion.getValue());
}
}
四、覆盖枚举的方法
package com.yang;
public enum RGBEnum {
RED("红色", 1), GREEN("绿色", 2), BLANK("白色", 3), YELLO("黄色", 4);
// 成员变量
private String name;
private int index;
// 构造方法 ,赋值给成员变量
private RGBEnum(String name, int index) {
this.name = name;
this.index = index;
}
//覆盖方法 :只能使用toString方法来输出枚举变量值
@Override
public String toString() {
return this.index+"_"+this.name;
}
}
测试方法:
@org.junit.Test
public void RGBEnumTest() {
for(RGBEnum rgb:RGBEnum.values()) {
System.out.println(rgb.toString());
}
}
tcp nio epoll等基本技术知识
TCP
应用层–>传输层–>网络层–>链路层–物理层
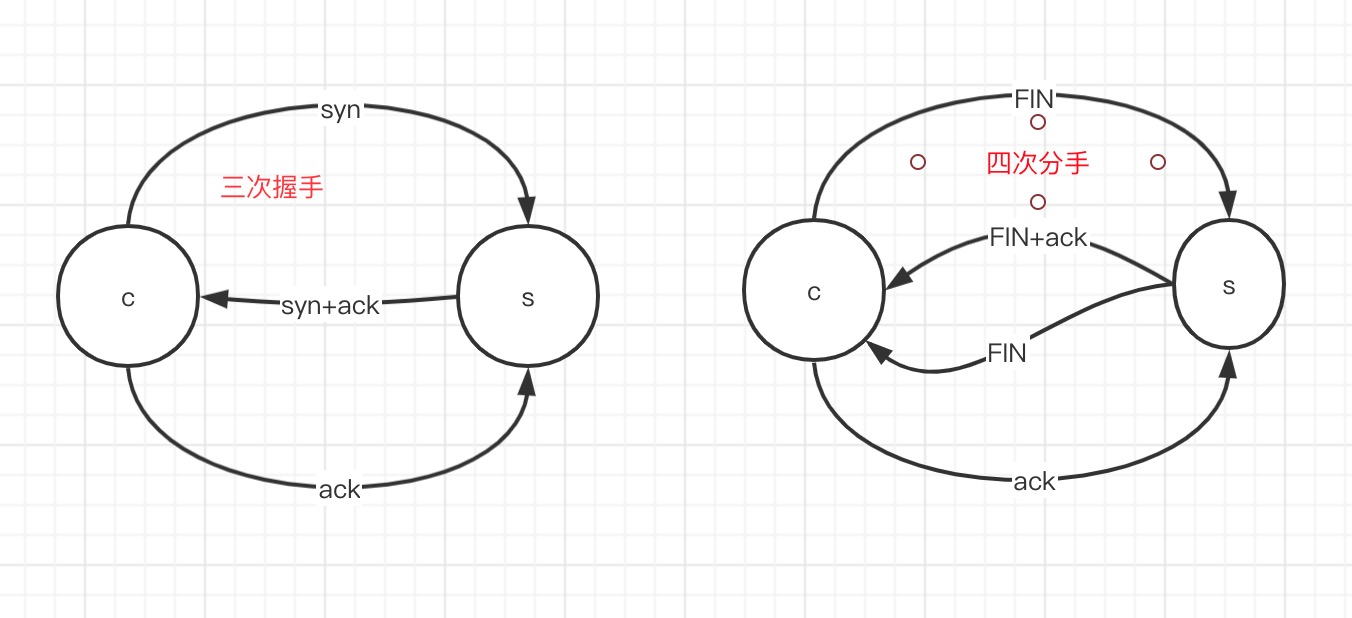
三次握手
四次分手
IO消耗
- 程序调用
- 用户态调用切换到系统调用
BIO
每个线程对应每个连接
优势:可接收很多的连接
问题:
- 线程内存浪费
- cpu调度消耗
根本原因:
BLOCKING 阻塞: accept recv
演变的解决方法 –>NONBLOCKING 非阻塞
NIO
New IO
NONBLOCKING
优势:避免多线程问题
弊端:假设有1w个连接,只有一个发来数据,每循环一次
其实都需要向内核发生1w次reav系统调用,这里有9999是无意义的
消耗时间和资源(用户空间向内核空间的循环遍历,复杂度在系统调用上)
package com.mashibing.io.nio;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.Iterator;
import java.util.Set;
public class Server {
public static void main(String[] args) throws IOException {
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.socket().bind(new InetSocketAddress("127.0.0.1", 8888));
ssc.configureBlocking(false);
System.out.println("server started, listening on :" + ssc.getLocalAddress());
Selector selector = Selector.open();
ssc.register(selector, SelectionKey.OP_ACCEPT);
while(true) {
selector.select();
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> it = keys.iterator();
while(it.hasNext()) {
SelectionKey key = it.next();
it.remove();
handle(key);
}
}
}
private static void handle(SelectionKey key) {
if(key.isAcceptable()) {
try {
ServerSocketChannel ssc = (ServerSocketChannel) key.channel();
SocketChannel sc = ssc.accept();
sc.configureBlocking(false);
//new Client
//
//String hostIP = ((InetSocketAddress)sc.getRemoteAddress()).getHostString();
/*
log.info("client " + hostIP + " trying to connect");
for(int i=0; i<clients.size(); i++) {
String clientHostIP = clients.get(i).clientAddress.getHostString();
if(hostIP.equals(clientHostIP)) {
log.info("this client has already connected! is he alvie " + clients.get(i).live);
sc.close();
return;
}
}*/
sc.register(key.selector(), SelectionKey.OP_READ );
} catch (IOException e) {
e.printStackTrace();
} finally {
}
} else if (key.isReadable()) { //flip
SocketChannel sc = null;
try {
sc = (SocketChannel)key.channel();
ByteBuffer buffer = ByteBuffer.allocate(512);
buffer.clear();
int len = sc.read(buffer);
if(len != -1) {
System.out.println(new String(buffer.array(), 0, len));
}
ByteBuffer bufferToWrite = ByteBuffer.wrap("HelloClient".getBytes());
sc.write(bufferToWrite);
} catch (IOException e) {
e.printStackTrace();
} finally {
if(sc != null) {
try {
sc.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
}
多路复用
-
同步IO模型: 如果成自己读取IO,那么这个IO模型,无论是BIO,NIO,多路复用器,都叫做 同步IO模型
- 多路复用器:还是得自己来读取数据
- select,poll,epoll 都是同步的
select 和poll的优劣
优势:通过一次系统调用,把fds,传递给内核,内核进行遍历,想多NIO的遍历,多路复用减少了系统调用次数
弊端:1. 因为在where循环中,所有会出现重复传递数据到系统调用
- 解决方法:内核开辟内存空间保留fd
2. 每次select,poll 都都用重复遍历全量的fd
-
多路复用器解释:解决的是IO状态的问题
用更少的系统调用解决所有的IO状态,而不是每一次IO都发送系统调用,减少了用户态到内核态切换的过程
epoll
在内核态中开辟一个空间,
shell命令 工具
- strace 追踪io 可打印出系统调用日志
SpringCloud面试题
- 什么是微服务?
- 微服务之间如何独立通讯的?
- SpringCloud 和 Dubbo 有哪些区别?
- SpringBoot 和 SpringCloud 之间关系?
- 什么是熔断?什么是服务降级?
- 微服务的优缺点是什么?说下你在项目中碰到的坑。
- eureka和zookeeper都可以提供服务注册与发现的功能,请说说两个的区别?
- 你所知道微服务的技术栈有哪些?列举一二。
- 什么是微服务架构?
栈溢出(stackoverflow)的原因及解决办法
栈溢出(stackoverflow) 的原因及解决办法:程序功能大概有网络通信、数据库、绘图等。测试的时候程序一运行到某个函数就出现此错误,查了很多地方,试了很多解决办法,终于把问题解决了。 大家都知道,Windows程序的内存机制大概是这样的: 全局变量(局部的静态变量本质也属于此范围)存储于堆内存,该段内存较大,一般不会溢出; 函数地址、函数参数、局部变量等信息存储于栈内存; 程序中栈内存默认大小为1M,对于当前日益扩大的程序规模而言,稍有不慎就可能出问题。(动态申请的内存即new出来的内存不在栈中)即如果函数这样写
voidtest_stack_overflow(){
char\*chdata=new[2\*1024\*1024];
delete[]chdata;
}
是不会出现这个错误的,而这样写则不行:
voidtest_stack_overflow(){
charchdata[2\*1024\*1024];
}
大多数情况下都会出现内存溢出的错误。出现__栈内存溢出的常见原因有2个__:
- 函数调用层次过深,每调用一次,函数的参数、局部变量等信息就压一次栈。
- 局部静态变量体积太大
第一种情况不太常见,因为很多情况下我们都用其他方法来代替递归调用(反正我是这么做的),所以只要不出现无限制的调用都应该是没有问题的,起码深度几十层我想是没问题的,这个我没试过但我想没有谁会把调用深度作那么多。
检查是否是此原因的方法为,在引起溢出的那个函数处设一个断点,然后执行程序使其停在断点处,然后按下快捷键Alt+7调出callstack窗口,在窗口中可以看到函数调用的层次关系。
第二种情况比较常见了,我就是犯了这个错误,我在函数里定义了一个局部变量,是一个类对象,该类中有一个大数组,大概是1.5M。
解决办法大致说来也有两种:
- 增加栈内存的数目
- 使用堆内存增加栈内存方法如下,在程序中依次选择Project->Setting->Link,在Category中选择output,在Reserve中输入16进制的栈内存大小如:0x10000000,然后点ok就可以了。
其他编译器也有类似的设置,个人认为这不是一个好办法,有一个致命原因,不知道有没有人遇到过,我把栈内存改大后,与数据库建立不了连接了(ADO方式,Acess数据库),把栈内存还原,问题立刻消失。不知道究竟是什么原因,有知道的可以告诉我。
第二种解决办法是比较可行的,具体实现由很多种方法可以直接把数组定义改成指针,然后动态申请内存;也可以把局部变量变成全局变量,一个偷懒的办法是直接在定义前边加个static,呵呵,直接变成静态变量(实质就是全局变量)。即可以把上例中的函数这么写:
voidtest_stack_overflow(){
staticcharchdata[2\*1024\*1024];
}
当然,除非万不得已,尽量不要使用这么大的数组,出现这种情况多半说明程序结构有问题。
分布式锁用 Redis 还是 Zookeeper
为什么用分布式锁?
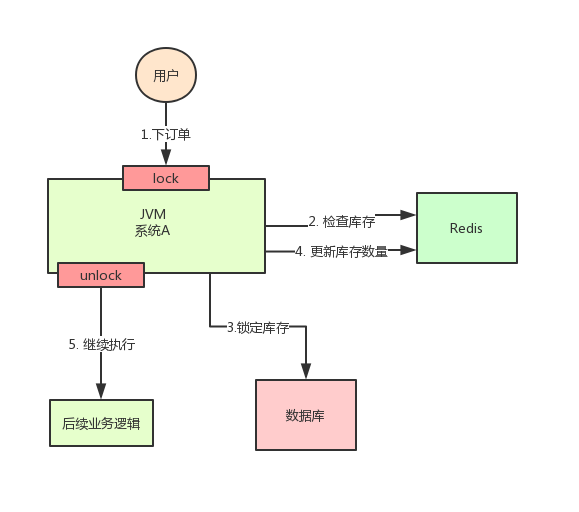
在讨论这个问题之前,我们先来看一个业务场景:系统A是一个电商系统,目前是一台机器部署,系统中有一个用户下订单的接口,但是用户下订单之前一定要去检查一下库存,确保库存足够了才会给用户下单。由于系统有一定的并发,所以会预先将商品的库存保存在redis中,用户下单的时候会更新redis的库存。此时系统架构如下:

但是这样一来会产生一个问题:假如某个时刻,redis里面的某个商品库存为1,此时两个请求同时到来,其中一个请求执行到上图的第3步,更新数据库的库存为0,但是第4步还没有执行。而另外一个请求执行到了第2步,发现库存还是1,就继续执行第3步。这样的结果,是导致卖出了2个商品,然而其实库存只有1个。很明显不对啊!这就是典型的库存超卖问题此时,我们很容易想到解决方案:用锁把2、3、4步锁住,让他们执行完之后,另一个线程才能进来执行第2步。
按照上面的图,在执行第2步时,使用Java提供的synchronized或者ReentrantLock来锁住,然后在第4步执行完之后才释放锁。这样一来,2、3、4 这3个步骤就被“锁”住了,多个线程之间只能串行化执行。关注公众号互联网架构师,回复关键字2T,获取最新架构视频但是好景不长,整个系统的并发飙升,一台机器扛不住了。现在要增加一台机器,如下图:
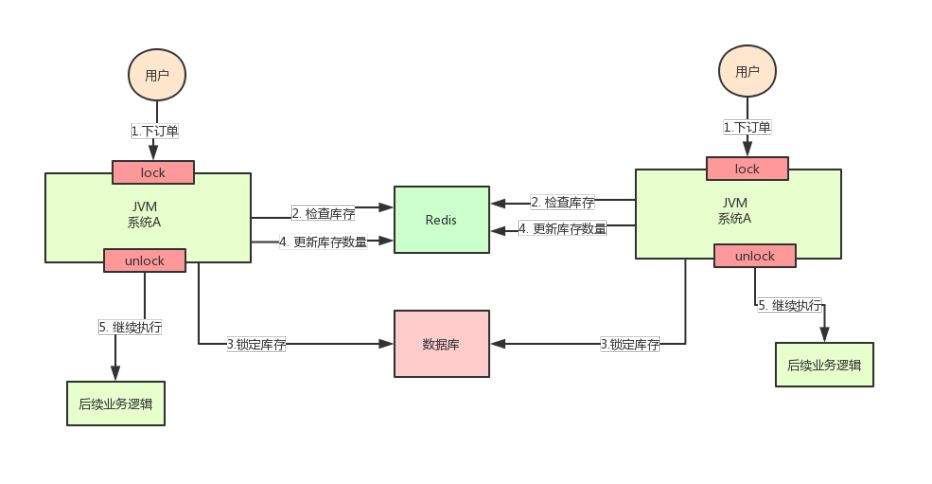
增加机器之后,系统变成上图所示,我的天!假设此时两个用户的请求同时到来,但是落在了不同的机器上,那么这两个请求是可以同时执行了,还是会出现库存超卖的问题。为什么呢?因为上图中的两个A系统,运行在两个不同的JVM里面,他们加的锁只对属于自己JVM里面的线程有效,对于其他JVM的线程是无效的。因此,这里的问题是:Java提供的原生锁机制在多机部署场景下失效了这是因为两台机器加的锁不是同一个锁(两个锁在不同的JVM里面)。那么,我们只要保证两台机器加的锁是同一个锁,问题不就解决了吗?此时,就该分布式锁隆重登场了,分布式锁的思路是:在整个系统提供一个全局、唯一的获取锁的“东西”,然后每个系统在需要加锁时,都去问这个“东西”拿到一把锁,这样不同的系统拿到的就可以认为是同一把锁。至于这个“东西”,可以是Redis、Zookeeper,也可以是数据库。文字描述不太直观,我们来看下图:

通过上面的分析,我们知道了库存超卖场景在分布式部署系统的情况下使用Java原生的锁机制无法保证线程安全,所以我们需要用到分布式锁的方案。那么,如何实现分布式锁呢?接着往下看!
基于Redis实现分布式锁
上面分析为啥要使用分布式锁了,这里我们来具体看看分布式锁落地的时候应该怎么样处理。扩展:Redisson是如何实现分布式锁的?
最常见的一种方案就是使用Redis做分布式锁使用Redis做分布式锁的思路大概是这样的:在redis中设置一个值表示加了锁,然后释放锁的时候就把这个key删除。具体代码是这样的:
// 获取锁
// NX是指如果key不存在就成功,key存在返回false,PX可以指定过期时间
SET anyLock unique_value NX PX 30000
// 释放锁:通过执行一段lua脚本
// 释放锁涉及到两条指令,这两条指令不是原子性的
// 需要用到redis的lua脚本支持特性,redis执行lua脚本是原子性的
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
这种方式有几大要点:
- 一定要用SET key value NX PX milliseconds 命令 如果不用,先设置了值,再设置过期时间,这个不是原子性操作,有可能在设置过期时间之前宕机,会造成死锁(key永久存在)
- value要具有唯一性 这个是为了在解锁的时候,需要验证value是和加锁的一致才删除key。 这是避免了一种情况:假设A获取了锁,过期时间30s,此时35s之后,锁已经自动释放了,A去释放锁,但是此时可能B获取了锁。A客户端就不能删除B的锁了。
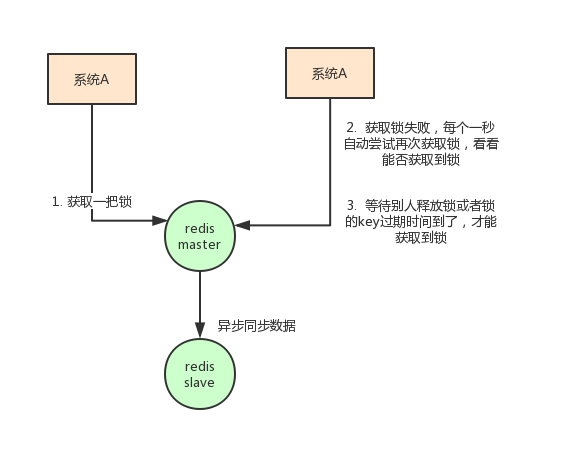
除了要考虑客户端要怎么实现分布式锁之外,还需要考虑redis的部署问题。redis有3种部署方式:
- 单机模式
- master-slave + sentinel选举模式
- redis cluster模式
使用redis做分布式锁的缺点在于:如果采用单机部署模式,会存在单点问题,只要redis故障了。加锁就不行了。采用master-slave模式,加锁的时候只对一个节点加锁,即便通过sentinel做了高可用,但是如果master节点故障了,发生主从切换,此时就会有可能出现锁丢失的问题。基于以上的考虑,其实redis的作者也考虑到这个问题,他提出了一个RedLock的算法,这个算法的意思大概是这样的:假设redis的部署模式是redis cluster,总共有5个master节点,通过以下步骤获取一把锁:
- 获取当前时间戳,单位是毫秒
- 轮流尝试在每个master节点上创建锁,过期时间设置较短,一般就几十毫秒
- 尝试在大多数节点上建立一个锁,比如5个节点就要求是3个节点(n / 2 +1)
- 客户端计算建立好锁的时间,如果建立锁的时间小于超时时间,就算建立成功了
- 要是锁建立失败了,那么就依次删除这个锁
- 只要别人建立了一把分布式锁,你就得不断轮询去尝试获取锁
- 但是这样的这种算法还是颇具争议的,可能还会存在不少的问题,无法保证加锁的过程一定正确。

另一种方式:Redisson
此外,实现Redis的分布式锁,除了自己基于redis client原生api来实现之外,还可以使用开源框架:RedissionRedisson是一个企业级的开源Redis Client,也提供了分布式锁的支持。我也非常推荐大家使用,为什么呢?回想一下上面说的,如果自己写代码来通过redis设置一个值,是通过下面这个命令设置的。
- SET anyLock unique_value NX PX 30000
这里设置的超时时间是30s,假如我超过30s都还没有完成业务逻辑的情况下,key会过期,其他线程有可能会获取到锁。这样一来的话,第一个线程还没执行完业务逻辑,第二个线程进来了也会出现线程安全问题。所以我们还需要额外的去维护这个过期时间,太麻烦了~我们来看看redisson是怎么实现的?先感受一下使用redission的爽:
Config config = new Config();
config.useClusterServers()
.addNodeAddress("redis://192.168.31.101:7001")
.addNodeAddress("redis://192.168.31.101:7002")
.addNodeAddress("redis://192.168.31.101:7003")
.addNodeAddress("redis://192.168.31.102:7001")
.addNodeAddress("redis://192.168.31.102:7002")
.addNodeAddress("redis://192.168.31.102:7003");
RedissonClient redisson = Redisson.create(config);
RLock lock = redisson.getLock("anyLock");
lock.lock();
lock.unlock();
就是这么简单,我们只需要通过它的api中的lock和unlock即可完成分布式锁,他帮我们考虑了很多细节:
-
redisson所有指令都通过lua脚本执行,redis支持lua脚本原子性执行
-
redisson设置一个key的默认过期时间为30s,如果某个客户端持有一个锁超过了30s怎么办?
redisson中有一个watchdog的概念,翻译过来就是看门狗,它会在你获取锁之后,每隔10秒帮你把key的超时时间设为30s 这样的话,就算一直持有锁也不会出现key过期了,其他线程获取到锁的问题了。
-
redisson的“看门狗”逻辑保证了没有死锁发生。 (如果机器宕机了,看门狗也就没了。此时就不会延长key的过期时间,到了30s之后就会自动过期了,其他线程可以获取到锁)
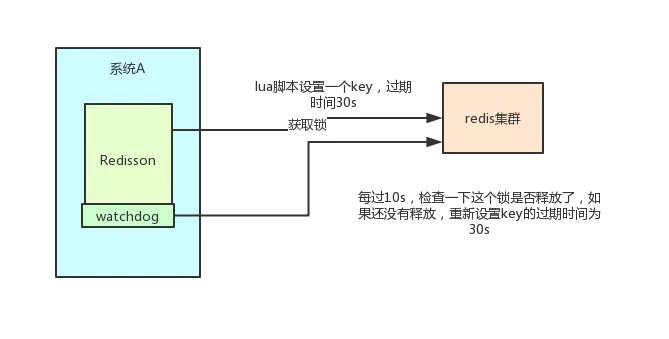
这里稍微贴出来其实现代码:
// 加锁逻辑
private <T> RFuture<Long> tryAcquireAsync(long leaseTime, TimeUnit unit, final long threadId) {
if (leaseTime != -1) {
return tryLockInnerAsync(leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
}
// 调用一段lua脚本,设置一些key、过期时间
RFuture<Long> ttlRemainingFuture = tryLockInnerAsync(commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout(), TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);
ttlRemainingFuture.addListener(new FutureListener<Long>() {
@Override
public void operationComplete(Future<Long> future) throws Exception {
if (!future.isSuccess()) {
return;
}
Long ttlRemaining = future.getNow();
// lock acquired
if (ttlRemaining == null) {
// 看门狗逻辑
scheduleExpirationRenewal(threadId);
}
}
});
return ttlRemainingFuture;
}
<T> RFuture<T> tryLockInnerAsync(long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
internalLockLeaseTime = unit.toMillis(leaseTime);
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);",
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
}
// 看门狗最终会调用了这里
private void scheduleExpirationRenewal(final long threadId) {
if (expirationRenewalMap.containsKey(getEntryName())) {
return;
}
// 这个任务会延迟10s执行
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
// 这个操作会将key的过期时间重新设置为30s
RFuture<Boolean> future = renewExpirationAsync(threadId);
future.addListener(new FutureListener<Boolean>() {
@Override
public void operationComplete(Future<Boolean> future) throws Exception {
expirationRenewalMap.remove(getEntryName());
if (!future.isSuccess()) {
log.error("Can't update lock " + getName() + " expiration", future.cause());
return;
}
if (future.getNow()) {
// reschedule itself
// 通过递归调用本方法,无限循环延长过期时间
scheduleExpirationRenewal(threadId);
}
}
});
}
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
if (expirationRenewalMap.putIfAbsent(getEntryName(), new ExpirationEntry(threadId, task)) != null) {
task.cancel();
}
}
另外,redisson还提供了对redlock算法的支持,它的用法也很简单:
RedissonClient redisson = Redisson.create(config);
RLock lock1 = redisson.getFairLock("lock1");
RLock lock2 = redisson.getFairLock("lock2");
RLock lock3 = redisson.getFairLock("lock3");
RedissonRedLock multiLock = new RedissonRedLock(lock1, lock2, lock3);
multiLock.lock();
multiLock.unlock();
小结:
本节分析了使用redis作为分布式锁的具体落地方案以及其一些局限性然后介绍了一个redis的客户端框架redisson,这也是我推荐大家使用的,比自己写代码实现会少care很多细节。
基于zookeeper实现分布式锁
常见的分布式锁实现方案里面,除了使用redis来实现之外,使用zookeeper也可以实现分布式锁。在介绍zookeeper(下文用zk代替)实现分布式锁的机制之前,先粗略介绍一下zk是什么东西:Zookeeper是一种提供配置管理、分布式协同以及命名的中心化服务。zk的模型是这样的:zk包含一系列的节点,叫做znode,就好像文件系统一样每个znode表示一个目录,然后znode有一些特性:
-
有序节点:假如当前有一个父节点为/lock,我们可以在这个父节点下面创建子节点; zookeeper提供了一个可选的有序特性,例如我们可以创建子节点“/lock/node-”并且指明有序,那么zookeeper在生成子节点时会根据当前的子节点数量自动添加整数序号 也就是说,如果是第一个创建的子节点,那么生成的子节点为/lock/node-0000000000,下一个节点则为/lock/node-0000000001,依次类推。
-
__临时节点:__客户端可以建立一个临时节点,在会话结束或者会话超时后,zookeeper会自动删除该节点。
-
__事件监听:__在读取数据时,我们可以同时对节点设置事件监听,当节点数据或结构变化时,zookeeper会通知客户端。当前
-
zookeeper有如下四种事件:
- 节点创建
- 节点删除
- 节点数据修改
- 子节点变更
基于以上的一些zk的特性,我们很容易得出使用zk实现分布式锁的落地方案:
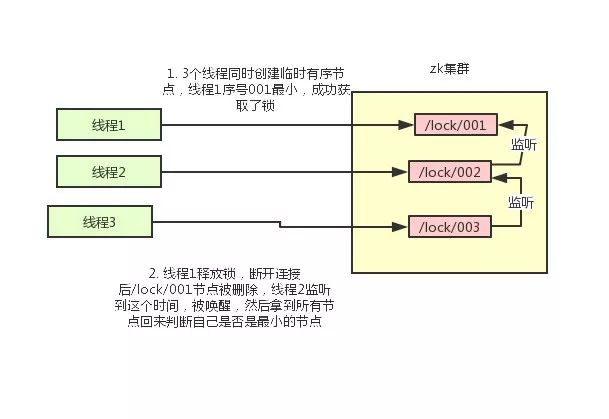
- 使用zk的临时节点和有序节点,每个线程获取锁就是在zk创建一个临时有序的节点,比如在/lock/目录下。
- 创建节点成功后,获取/lock目录下的所有临时节点,再判断当前线程创建的节点是否是所有的节点的序号最小的节点
- 如果当前线程创建的节点是所有节点序号最小的节点,则认为获取锁成功。
- 如果当前线程创建的节点不是所有节点序号最小的节点,则对节点序号的前一个节点添加一个事件监听。 比如当前线程获取到的节点序号为/lock/003,然后所有的节点列表为[/lock/001,/lock/002,/lock/003],则对/lock/002这个节点添加一个事件监听器。 如果锁释放了,会唤醒下一个序号的节点,然后重新执行第3步,判断是否自己的节点序号是最小。比如/lock/001释放了,/lock/002监听到时间,此时节点集合为[/lock/002,/lock/003],则/lock/002为最小序号节点,获取到锁。
整个过程如下:
具体的实现思路就是这样,至于代码怎么写,这里比较复杂就不贴出来了。
Curator介绍
Curator是一个zookeeper的开源客户端,也提供了分布式锁的实现。他的使用方式也比较简单:
InterProcessMutex interProcessMutex = new InterProcessMutex(client,"/anyLock");
interProcessMutex.acquire();
interProcessMutex.release();
其实现分布式锁的核心源码如下:
private boolean internalLockLoop(long startMillis, Long millisToWait, String ourPath) throws Exception
{
boolean haveTheLock = false;
boolean doDelete = false;
try {
if ( revocable.get() != null ) {
client.getData().usingWatcher(revocableWatcher).forPath(ourPath);
}
while ( (client.getState() == CuratorFrameworkState.STARTED) && !haveTheLock ) {
// 获取当前所有节点排序后的集合
List<String> children = getSortedChildren();
// 获取当前节点的名称
String sequenceNodeName = ourPath.substring(basePath.length() + 1); // +1 to include the slash
// 判断当前节点是否是最小的节点
PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases);
if ( predicateResults.getsTheLock() ) {
// 获取到锁
haveTheLock = true;
} else {
// 没获取到锁,对当前节点的上一个节点注册一个监听器
String previousSequencePath = basePath + "/" + predicateResults.getPathToWatch();
synchronized(this){
Stat stat = client.checkExists().usingWatcher(watcher).forPath(previousSequencePath);
if ( stat != null ){
if ( millisToWait != null ){
millisToWait -= (System.currentTimeMillis() - startMillis);
startMillis = System.currentTimeMillis();
if ( millisToWait <= 0 ){
doDelete = true; // timed out - delete our node
break;
}
wait(millisToWait);
}else{
wait();
}
}
}
// else it may have been deleted (i.e. lock released). Try to acquire again
}
}
}
catch ( Exception e ) {
doDelete = true;
throw e;
} finally{
if ( doDelete ){
deleteOurPath(ourPath);
}
}
return haveTheLock;
}
其实curator实现分布式锁的底层原理和上面分析的是差不多的。这里我们用一张图详细描述其原理:
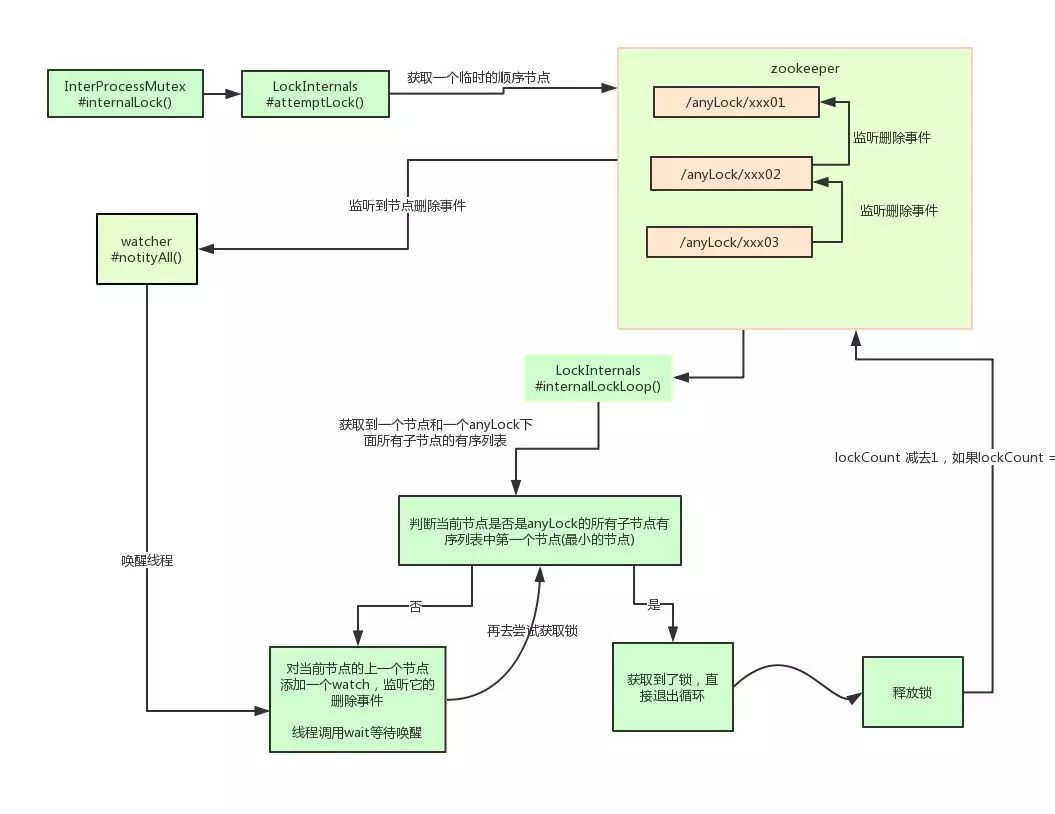
小结:本节介绍了zookeeperr实现分布式锁的方案以及zk的开源客户端的基本使用,简要的介绍了其实现原理。
两种方案的优缺点比较
学完了两种分布式锁的实现方案之后,本节需要讨论的是redis和zk的实现方案中各自的优缺点。对于redis的分布式锁而言,它有以下缺点:
- 它获取锁的方式简单粗暴,获取不到锁直接不断尝试获取锁,比较消耗性能。
- 另外来说的话,redis的设计定位决定了它的数据并不是强一致性的,在某些极端情况下,可能会出现问题。锁的模型不够健壮
- 即便使用redlock算法来实现,在某些复杂场景下,也无法保证其实现100%没有问题,关于redlock的讨论可以看How to do distributed locking
- redis分布式锁,其实需要自己不断去尝试获取锁,比较消耗性能。
但是另一方面使用redis实现分布式锁在很多企业中非常常见,而且大部分情况下都不会遇到所谓的“极端复杂场景”所以使用redis作为分布式锁也不失为一种好的方案,最重要的一点是redis的性能很高,可以支撑高并发的获取、释放锁操作。
对于zk分布式锁而言:
- zookeeper天生设计定位就是分布式协调,强一致性。锁的模型健壮、简单易用、适合做分布式锁。
- 如果获取不到锁,只需要添加一个监听器就可以了,不用一直轮询,性能消耗较小。
但是zk也有其缺点:如果有较多的客户端频繁的申请加锁、释放锁,对于zk集群的压力会比较大。
小结:
综上所述,redis和zookeeper都有其优缺点。我们在做技术选型的时候可以根据这些问题作为参考因素。
建议
通过前面的分析,实现分布式锁的两种常见方案:redis和zookeeper,他们各有千秋。应该如何选型呢?
就个人而言的话,我 比较推崇zk实现的锁:
因为redis是有可能存在隐患的,可能会导致数据不对的情况。但是,怎么选用要看具体在公司的场景了。
如果公司里面有zk集群条件,优先选用zk实现,但是如果说公司里面只有redis集群,没有条件搭建zk集群。
那么其实用redis来实现也可以,另外还可能是系统设计者考虑到了系统已经有redis,但是又不希望再次引入一些外部依赖的情况下,可以选用redis。
java内存泄漏与内存溢出
内存溢出 out of memory,是指程序在申请内存时,没有足够的内存空间供其使用,出现out of memory;
内存泄露 memory leak,是指程序在申请内存后,无法释放已申请的内存空间,一次内存泄露危害可以忽略,但内存泄露堆积后果很严重,无论多少内存,迟早会被占光。
memory leak会最终会导致out of memory!
以发生的方式来分类,内存泄漏可以分为4类:
- 常发性内存泄漏。发生内存泄漏的代码会被多次执行到,每次被执行的时候都会导致一块内存泄漏。
- 偶发性内存泄漏。发生内存泄漏的代码只有在某些特定环境或操作过程下才会发生。常发性和偶发性是相对的。对于特定的环境,偶发性的也许就变成了常发性的。所以测试环境和测试方法对检测内存泄漏至关重要。
- 一次性内存泄漏。发生内存泄漏的代码只会被执行一次,或者由于算法上的缺陷,导致总会有一块仅且一块内存发生泄漏。比如,在类的构造函数中分配内存,在析构函数中却没有释放该内存,所以内存泄漏只会发生一次。
- 隐式内存泄漏。程序在运行过程中不停的分配内存,但是直到结束的时候才释放内存。严格的说这里并没有发生内存泄漏,因为最终程序释放了所有申请的内存。但是对于一个服务器程序,需要运行几天,几周甚至几个月,不及时释放内存也可能导致最终耗尽系统的所有内存。所以,我们称这类内存泄漏为隐式内存泄漏。
从用户使用程序的角度来看,内存泄漏本身不会产生什么危害,作为一般的用户,根本感觉不到内存泄漏的存在。真正有危害的是内存泄漏的堆积,这会最终消耗尽系统所有的内存。从这个角度来说,一次性内存泄漏并没有什么危害,因为它不会堆积,而隐式内存泄漏危害性则非常大,因为较之于常发性和偶发性内存泄漏它更难被检测到
一、Java内存回收机制
不论哪种语言的内存分配方式,都需要返回所分配内存的真实地址,也就是返回一个指针到内存块的首地址。Java中对象是采用new或者反射的方法创建的,这些对象的创建都是在堆(Heap)中分配的,所有对象的回收都是由Java虚拟机通过垃圾回收机制完成的。GC为了能够正确释放对象,会监控每个对象的运行状况,对他们的申请、引用、被引用、赋值等状况进行监控,Java会使用有向图的方法进行管理内存,实时监控对象是否可以达到,如果不可到达,则就将其回收,
二、Java内存泄露引起原因
内存泄露是指无用对象(不再使用的对象)持续占有内存或无用对象的内存得不到及时释放,从而造成的内存空间的浪费称为内存泄露。内存泄露有时不严重且不易察觉,这样开发者就不知道存在内存泄露,但有时也会很严重,会提示你Out of memory。
那么,Java内存泄露根本原因是什么呢?长生命周期的对象持有短生命周期对象的引用就很可能发生内存泄露,尽管短生命周期对象已经不再需要,但是因为长生命周期对象持有它的引用而导致不能被回收,这就是java中内存泄露的发生场景。具体主要有如下几大类:
1、静态集合类引起内存泄露:
像HashMap、Vector等的使用最容易出现内存泄露,这些静态变量的生命周期和应用程序一致,他们所引用的所有的对象Object也不能被释放,因为他们也将一直被Vector等引用着。
Static Vector v = new Vector(10);
for (int i = 1; i<100; i++)
{
Object o = new Object();
v.add(o);
o = null;
}//
在这个例子中,循环申请Object 对象,并将所申请的对象放入一个Vector 中,如果仅仅释放引用本身(o=null),那么Vector 仍然引用该对象,所以这个对象对GC 来说是不可回收的。因此,如果对象加入到Vector 后,还必须从Vector 中删除,最简单的方法就是将Vector对象设置为null。
2、当集合里面的对象属性被修改后,再调用remove()方法时不起作用。
public static void main(String[] args)
{
Set<Person> set = new HashSet<Person>();
Person p1 = new Person("唐僧","pwd1",25);
Person p2 = new Person("孙悟空","pwd2",26);
Person p3 = new Person("猪八戒","pwd3",27);
set.add(p1);
set.add(p2);
set.add(p3);
System.out.println("总共有:"+set.size()+" 个元素!"); //结果:总共有:3 个元素!
p3.setAge(2); //修改p3的年龄,此时p3元素对应的hashcode值发生改变
set.remove(p3); //此时remove不掉,造成内存泄漏
set.add(p3); //重新添加,居然添加成功
System.out.println("总共有:"+set.size()+" 个元素!"); //结果:总共有:4 个元素!
for (Person person : set)
{
System.out.println(person);
}
}
3、监听器
在java 编程中,我们都需要和监听器打交道,通常一个应用当中会用到很多监听器,我们会调用一个控件的诸如addXXXListener()等方法来增加监听器,但往往在释放对象的时候却没有记住去删除这些监听器,从而增加了内存泄漏的机会。
4、各种连接
比如数据库连接(dataSourse.getConnection()),网络连接(socket)和io连接,除非其显式的调用了其close()方法将其连接关闭,否则是不会自动被GC 回收的。对于Resultset 和Statement 对象可以不进行显式回收,但Connection 一定要显式回收,因为Connection 在任何时候都无法自动回收,而Connection一旦回收,Resultset 和Statement 对象就会立即为NULL。但是如果使用连接池,情况就不一样了,除了要显式地关闭连接,还必须显式地关闭Resultset Statement 对象(关闭其中一个,另外一个也会关闭),否则就会造成大量的Statement 对象无法释放,从而引起内存泄漏。这种情况下一般都会在try里面去的连接,在finally里面释放连接。
5、单例模式
如果单例对象持有外部对象的引用,那么这个外部对象将不能被jvm正常回收,导致内存泄露。
如果单例对象持有外部对象的引用,那么这个外部对象将不能被jvm正常回收,导致内存泄露
不正确使用单例模式是引起内存泄露的一个常见问题,单例对象在被初始化后将在JVM的整个生命周期中存在(以静态变量的方式),如果单例对象持有外部对象的引用,那么这个外部对象将不能被jvm正常回收,导致内存泄露,考虑下面的例子:
class A{
public A(){
B.getInstance().setA(this);
}
....
}
//B类采用单例模式
class B{
private A a;
private static B instance=new B();
public B(){}
public static B getInstance(){
return instance;
}
public void setA(A a){
this.a=a;
}
//getter...
}
显然B采用singleton模式,它持有一个A对象的引用,而这个A类的对象将不能被回收。想象下如果A是个比较复杂的对象或者集合类型会发生什么情况
阻塞式编程和非阻塞式编程
- 阻塞IO的含义
- 阻塞(blocking)IO:资源不可用时,IO请求一直阻塞,知道反馈结果(有数据或者超时)。
- 非阻塞(non-blocking)IO:资源不可用时,IO请求离开返回,返回数据标识资源不可用。
- 同步(synchronous)IO:应用组社发送或接受说句状态,知道数据成功传输或返回失败。
- 异步(asynchronous)IO:应用发送或接受数据后立刻返回,实际处理是异步执行的。
阻塞和非阻塞是获取资源的方式。同步/异步是程序如何处理资源的逻辑设计。
代码中使用的API:ServerSocket#accept、InputStream#read都是阻塞的API。操作系统底层API中,默认操作都是Blocking型。sent./rec等接口都是阻塞的。
带来的问题:阻塞导致处理网络I/O时,一个线程只能处理一个网络连接。
339 post articles, 43 pages.