Spring-Aop
AOP的作用
作用:在不修改源代码的情况下,可以实现功能的增强
传统的纵向体系代码复用:

横向抽取机制(AOP思想):

AOP 思想: 基于代理思想,对原来目标对象,创建代理对象,在不修改原对象代码情况下,通过代理对象,调用增强功能的代码,从而对原有业务方法进行增强 !
AOP应用场景
场景一: 记录日志
场景二: 监控方法运行时间 (监控性能)
场景三: 权限控制
场景四: 缓存优化 (第一次调用查询数据库,将查询结果放入内存对象, 第二次调用, 直接从内存对象返回,不需要查询数据库 )
场景五: 事务管理 (调用方法前开启事务, 调用方法后提交关闭事务 )
AOP的实现原理
那Spring中AOP是怎么实现的呢?Spring中AOP的有两种实现方式:
- JDK动态代理
- Cglib动态代理
JDK动态代理
- 引入依赖,有spring,单元测,日志管理
<!-- https://mvnrepository.com/artifact/org.springframework/spring-context --> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-context</artifactId> <version>5.2.7.RELEASE</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> <!-- <scope>test</scope>--> </dependency> <!-- 日志 --> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.30</version> </dependency> <dependency> <groupId>cglib</groupId> <artifactId>cglib</artifactId> <version>3.3.0</version> </dependency> - UserDao接口
public interface UserDao {
public void saveUser();
}
- UserDao实现类
public class UserDaoImpl implements UserDao {
@Override
public void saveUser() {
System.out.println("持久层:用户保存");
}
}
- 动态代理
@Test
public void test1() {
final UserDao userDao = new UserDaoImpl();
// newProxyInstance的三个参数解释:
// 参数1:代理类的类加载器,同目标类的类加载器
// 参数2:代理类要实现的接口列表,同目标类实现的接口列表
// 参数3:回调,是一个InvocationHandler接口的实现对象,当调用代理对象的方法时,执行的是回调中的invoke方法
//proxy为代理对象
UserDao proxy = (UserDao) Proxy.newProxyInstance(userDao.getClass().getClassLoader(),
userDao.getClass().getInterfaces(), new InvocationHandler() {
@Override
// 参数proxy:被代理的对象
// 参数method:执行的方法,代理对象执行哪个方法,method就是哪个方法
// 参数args:执行方法的参数
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("记录日志");
Object result = method.invoke(userDao, args);
return result;
}
});
//代理对象执行方法
proxy.saveUser();
}
- 结果
在没有修改原有类的代码的情况下,对原有类的功能进行了增强
记录日志
持久曾:用户保护
Cglib动态代理
在实际开发中,可能需要对 没有实现接口的类增强,用JDK动态代理的方式就没法实现 。采用Cglib动态代理可以对没有实现接口的类产生代理,实际上是生成了目标类的子类来增强。
- 首先,需要导入Cglib所需的jar包。提示:spring已经集成了cglib,我们已经导入了spring包,所以不需要再导入其它包了。
- 目标类(一个公开方法,另外一个用final修饰):
public class Dog{
final public void run(String name) {
System.out.println("狗"+name+"----run");
}
public void eat() {
System.out.println("狗----eat");
}
}
- 方法拦截器:
import java.lang.reflect.Method;
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
public class MyMethodInterceptor implements MethodInterceptor{
@Override
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
long start = System.currentTimeMillis();
System.out.println("方法:"+method.getName()+"开始执行");
//注意这里的方法调用,不是用反射哦!!!
Object object = methodProxy.invokeSuper(obj, args);
long end = System.currentTimeMillis();
System.out.println("用时:"+ (end-start) + " ms");
}
}
- 测试类
import net.sf.cglib.core.DebuggingClassWriter;
import net.sf.cglib.proxy.Enhancer;
public class CgLibProxy {
public static void main(String[] args) {
//在指定目录下生成动态代理类,我们可以反编译看一下里面到底是一些什么东西
// System.setProperty(DebuggingClassWriter.DEBUG_LOCATION_PROPERTY, "D:\\java\\java_workapace");
//创建Enhancer对象,类似于JDK动态代理的Proxy类,下一步就是设置几个参数
Enhancer enhancer = new Enhancer();
//设置目标类的字节码文件
enhancer.setSuperclass(Dog.class);
//设置回调函数
enhancer.setCallback(new MyMethodInterceptor());
//这里的creat方法就是正式创建代理类
Dog proxyDog = (Dog)enhancer.create();
//调用代理类的eat方法
proxyDog.eat();
}
}
- 结果
这里是对目标类进行增强
狗----eat
参考网站
java中VO的使用(VO视图对象)
概念 VO(View Object)
场景1
当前端展示页面展示的更多关于用户的消息,如用户的角色Role,而User实体类中的信息不全
现在我们有一张用户列表t_user,对应的实体类如下:
import io.swagger.annotations.ApiModelProperty;
public class User {
@ApiModelProperty(value = "用户id")
private String userId;
@ApiModelProperty(value = "用户名称")
private String accountname;
/**
* 状态参考 UserStatus
*/
@ApiModelProperty(value = "用户状态 1已认证,2 认证中,3未通过认证,7未提交认证")
private Integer status;
@ApiModelProperty(value = "头像地址")
private String headPicFileName;
@ApiModelProperty(value = "手机号")
private String telephone;
/**
* 用户级别 0到期 1游客 2临时用户 3认证用户 参考health com.dachen.health.commons.vo.User
*/
private Integer userLevel;
@ApiModelProperty(value = "医生信息")
private Doctor doctor;
}
我们通过创建一个类通过 UserVO extends User 的方式获取更多
public class CircleUserVO extends User{
@ApiModelProperty(value = "在该圈子的角色1:管理员 2:圈主(负责人)3:顾问 逗号拼接 多个角色 可同时为管理员,圈主,顾问")
private String role;
@ApiModelProperty(value = "0否 1是 永久免费")
private Integer permanentFree;
@ApiModelProperty(value = "1正常 2欠费")
private Integer arrearageStatus;
。。。。
}
场景二
当前端提交给后台的数据很有限或者很少时,如注册页面提供的信息一般在4个字段左右,而通常的User实体类会有大量的字段需要填充
public class CircleUserVO {
@ApiModelProperty(value = "手机号")
private String telephone;
@ApiModelProperty(value = "用户名称")
private String accountname;
@ApiModelProperty(value = "用户密码")
private String password;
}
1
SpringBoot注解大全
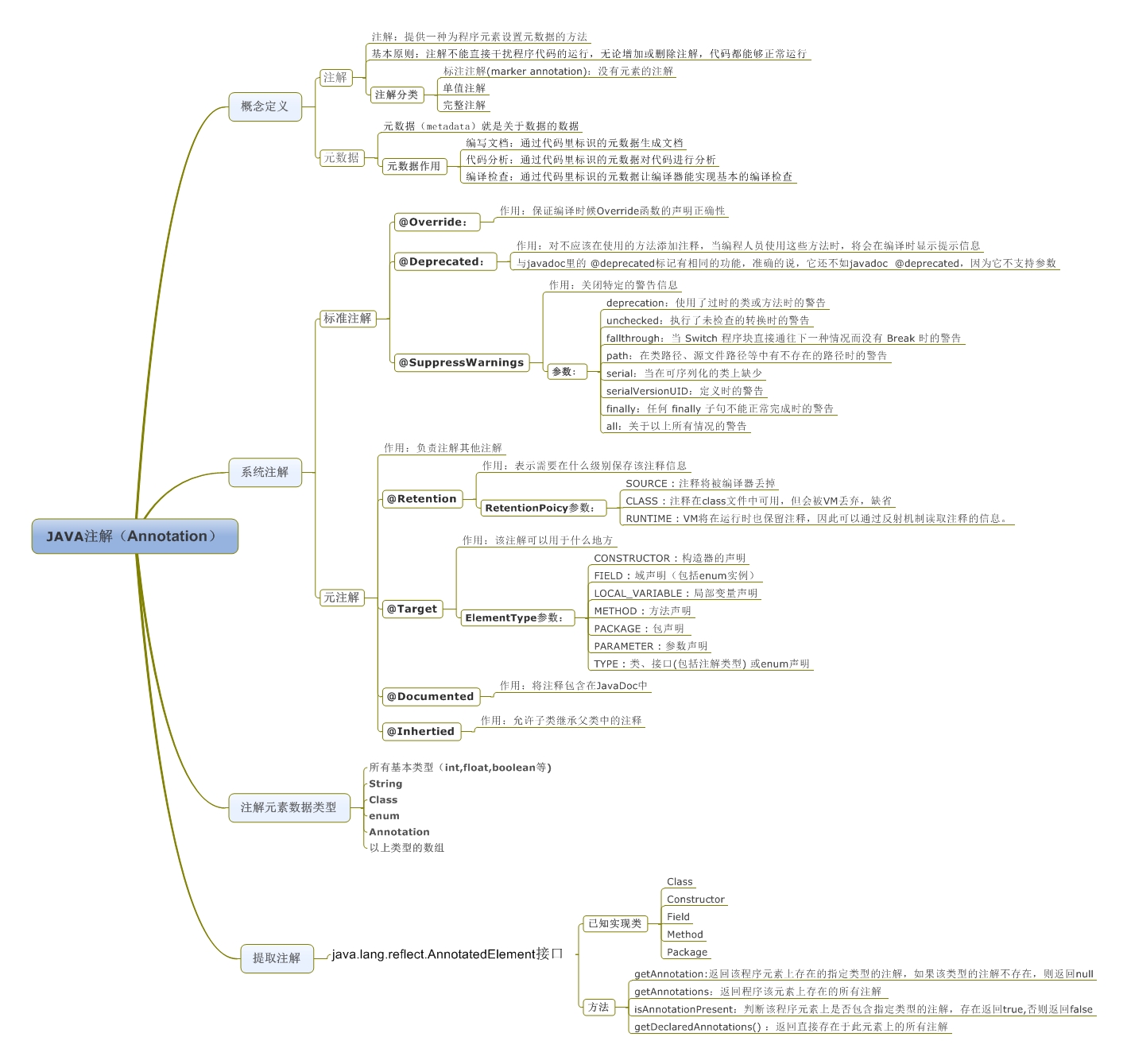
一、注解(annotations)列表
@SpringBootApplication:包含了@ComponentScan、@Configuration和@EnableAutoConfiguration注解。其中@ComponentScan让spring Boot扫描到Configuration类并把它加入到程序上下文。
@Configuration 等同于spring的XML配置文件;使用Java代码可以检查类型安全。
@EnableAutoConfiguration 自动配置。
@ComponentScan 组件扫描,可自动发现和装配一些Bean。
@Component可配合CommandLineRunner使用,在程序启动后执行一些基础任务。
@RestController注解是@Controller和@ResponseBody的合集,表示这是个控制器bean,并且是将函数的返回值直 接填入HTTP响应体中,是REST风格的控制器。
@Autowired自动导入。
@PathVariable获取参数。
@JsonBackReference解决嵌套外链问题。
@RepositoryRestResourcepublic配合spring-boot-starter-data-rest使用。
@ApiModelProperty()用于方法,字段; 表示对model属性的说明或者数据操作更改
二、注解(annotations)详解
@SpringBootApplication:申明让spring boot自动给程序进行必要的配置,这个配置等同于:@Configuration ,@EnableAutoConfiguration 和 @ComponentScan 三个配置。
package com.example.myproject;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication // same as @Configuration @EnableAutoConfiguration @ComponentScan
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
@ResponseBody:表示该方法的返回结果直接写入HTTP response body中,一般在异步获取数据时使用,用于构建RESTful的api。在使用@RequestMapping后,返回值通常解析为跳转路径,加上@esponsebody后返回结果不会被解析为跳转路径,而是直接写入HTTP response body中。比如异步获取json数据,加上@Responsebody后,会直接返回json数据。该注解一般会配合@RequestMapping一起使用。示例代码:
@RequestMapping(“/test”)
@ResponseBody
public String test(){
return”ok”;
}
@Controller:用于定义控制器类,在spring项目中由控制器负责将用户发来的URL请求转发到对应的服务接口(service层),一般这个注解在类中,通常方法需要配合注解@RequestMapping。示例代码:
@Controller
@RequestMapping(“/demoInfo”)
public class DemoController {
@Autowired
private DemoInfoService demoInfoService;
@RequestMapping("/hello")
public String hello(Map<String,Object> map){
System.out.println("DemoController.hello()");
map.put("hello","from TemplateController.helloHtml");
//会使用hello.html或者hello.ftl模板进行渲染显示.
return"/hello";
}
}
@RestController:用于标注控制层组件(如struts中的action),@ResponseBody和@Controller的合集。示例代码:
package com.kfit.demo.web;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping(“/demoInfo2”)
publicclass DemoController2 {
@RequestMapping("/test")
public String test(){
return "ok";
}
}
@RequestMapping:提供路由信息,负责URL到Controller中的具体函数的映射。
@EnableAutoConfiguration:SpringBoot自动配置(auto-configuration):尝试根据你添加的jar依赖自动配置你的Spring应用。例如,如果你的classpath下存在HSQLDB,并且你没有手动配置任何数据库连接beans,那么我们将自动配置一个内存型(in-memory)数据库”。你可以将@EnableAutoConfiguration或者@SpringBootApplication注解添加到一个@Configuration类上来选择自动配置。如果发现应用了你不想要的特定自动配置类,你可以使用@EnableAutoConfiguration注解的排除属性来禁用它们。
@ComponentScan:其实很简单,@ComponentScan主要就是定义扫描的路径从中找出标识了需要装配的类自动装配到spring的bean容器中,你一定都有用过@Controller,@Service,@Repository注解,查看其源码你会发现,他们中有一个共同的注解@Component,没错@ComponentScan注解默认就会装配标识了@Controller,@Service,@Repository,@Component注解的类到spring容器中。当然,这个的前提就是你需要在所扫描包下的类上引入注解。
@Configuration:相当于传统的xml配置文件,如果有些第三方库需要用到xml文件,建议仍然通过@Configuration类作为项目的配置主类——可以使用@ImportResource注解加载xml配置文件。
@Import:用来导入其他配置类。
@ImportResource:用来加载xml配置文件。
@Autowired:自动导入依赖的bean
@Service:一般用于修饰service层的组件
@Repository:使用@Repository注解可以确保DAO或者repositories提供异常转译,这个注解修饰的DAO或者repositories类会被ComponetScan发现并配置,同时也不需要为它们提供XML配置项。
@Bean:用@Bean标注方法等价于XML中配置的bean。
@Value:注入Spring boot application.properties配置的属性的值。示例代码:
@Value(value = “#{message}”)
private String message;
@Inject:等价于默认的@Autowired,只是没有required属性;
@Component:泛指组件,当组件不好归类的时候,我们可以使用这个注解进行标注。
@Bean:相当于XML中的,放在方法的上面,而不是类,意思是产生一个bean,并交给spring管理。
@AutoWired:自动导入依赖的bean。byType方式。把配置好的Bean拿来用,完成属性、方法的组装,它可以对类成员变量、方法及构造函数进行标注,完成自动装配的工作。当加上(required=false)时,就算找不到bean也不报错。
@Qualifier:当有多个同一类型的Bean时,可以用@Qualifier(“name”)来指定。与@Autowired配合使用。@Qualifier限定描述符除了能根据名字进行注入,但能进行更细粒度的控制如何选择候选者,具体使用方式如下:
@Autowired
@Qualifier(value = “demoInfoService”)
private DemoInfoService demoInfoService;
@Resource(name=”name”,type=”type”):没有括号内内容的话,默认byName。与@Autowired干类似的事。
三、JPA注解
@Entity:@Table(name=”“):表明这是一个实体类。一般用于jpa这两个注解一般一块使用,但是如果表名和实体类名相同的话,@Table可以省略
@MappedSuperClass:用在确定是父类的entity上。父类的属性子类可以继承。
@NoRepositoryBean:一般用作父类的repository,有这个注解,spring不会去实例化该repository。
@Column:如果字段名与列名相同,则可以省略。
@Id:表示该属性为主键。
@GeneratedValue(strategy = GenerationType.SEQUENCE,generator = “repair_seq”):表示主键生成策略是sequence(可以为Auto、IDENTITY、native等,Auto表示可在多个数据库间切换),指定sequence的名字是repair_seq。
@SequenceGeneretor(name = “repair_seq”, sequenceName = “seq_repair”, allocationSize = 1):name为sequence的名称,以便使用,sequenceName为数据库的sequence名称,两个名称可以一致。
@Transient:表示该属性并非一个到数据库表的字段的映射,ORM框架将忽略该属性。如果一个属性并非数据库表的字段映射,就务必将其标示为@Transient,否则,ORM框架默认其注解为@Basic。@Basic(fetch=FetchType.LAZY):标记可以指定实体属性的加载方式
@JsonIgnore:作用是json序列化时将Java bean中的一些属性忽略掉,序列化和反序列化都受影响。
@JoinColumn(name=”loginId”):一对一:本表中指向另一个表的外键。一对多:另一个表指向本表的外键。
@OneToOne、@OneToMany、@ManyToOne:对应hibernate配置文件中的一对一,一对多,多对一。
四、springMVC相关注解
@RequestMapping:@RequestMapping(“/path”)表示该控制器处理所有“/path”的UR L请求。RequestMapping是一个用来处理请求地址映射的注解,可用于类或方法上。 用于类上,表示类中的所有响应请求的方法都是以该地址作为父路径。该注解有六个属性:
- params:指定request中必须包含某些参数值是,才让该方法处理。
- headers:指定request中必须包含某些指定的header值,才能让该方法处理请求。
- value:指定请求的实际地址,指定的地址可以是URI Template 模式
- method:指定请求的method类型, GET、POST、PUT、DELETE等
- consumes:指定处理请求的提交内容类型(Content-Type),如application/json,text/html;
- produces:指定返回的内容类型,仅当request请求头中的(Accept)类型中包含该指定类型才返回
@RequestParam:用在方法的参数前面。 @RequestParam String a =request.getParameter(“a”)。
@PathVariable:路径变量。如
RequestMapping(“user/get/mac/{macAddress}”)
public String getByMacAddress(@PathVariable String macAddress){
//do something;
}
参数与大括号里的名字一样要相同。
五、全局异常处理
@ControllerAdvice:包含@Component。可以被扫描到。统一处理异常。
@ExceptionHandler(Exception.class):用在方法上面表示遇到这个异常就执行以下方法。
六、项目中具体配置解析和使用环境
@MappedSuperclass:
1.@MappedSuperclass 注解使用在父类上面,是用来标识父类的
2.@MappedSuperclass 标识的类表示其不能映射到数据库表,因为其不是一个完整的实体类,但是它所拥有的属性能够映射在其子类对用的数据库表中
3.@MappedSuperclass 标识的类不能再有@Entity或@Table注解
@Column:
1.当实体的属性与其映射的数据库表的列不同名时需要使用@Column标注说明,该属性通常置于实体的属性声明语句之前,还可与 @Id 标注一起使用。
2.@Column 标注的常用属性是name,用于设置映射数据库表的列名。此外,该标注还包含其它多个属性,如:unique、nullable、length、precision等。具体如下:
name属性:name属性定义了被标注字段在数据库表中所对应字段的名称
unique属性:unique属性表示该字段是否为唯一标识,默认为false,如果表中有一个字段需要唯一标识,则既可以使用该标记,也可以使用@Table注解中的@UniqueConstraint
nullable属性:nullable属性表示该字段是否可以为null值,默认为true
insertable属性:insertable属性表示在使用”INSERT”语句插入数据时,是否需要插入该字段的值
updateable属性:updateable属性表示在使用”UPDATE”语句插入数据时,是否需要更新该字段的值
insertable和updateable属性:一般多用于只读的属性,例如主键和外键等,这些字段通常是自动生成的
columnDefinition属性:columnDefinition属性表示创建表时,该字段创建的SQL语句,一般用于通过Entity生成表定义时使用,如果数据库中表已经建好,该属性没有必要使用
table属性:table属性定义了包含当前字段的表名
length属性:length属性表示字段的长度,当字段的类型为varchar时,该属性才有效,默认为255个字符
precision属性和scale属性:precision属性和scale属性一起表示精度,当字段类型为double时,precision表示数值的总长度,scale表示小数点所占的位数
具体如下:
1.double类型将在数据库中映射为double类型,precision和scale属性无效
2.double类型若在columnDefinition属性中指定数字类型为decimal并指定精度,则最终以columnDefinition为准
3.BigDecimal类型在数据库中映射为decimal类型,precision和scale属性有效
4.precision和scale属性只在BigDecimal类型中有效
3.@Column 标注的columnDefinition属性: 表示该字段在数据库中的实际类型.通常 ORM 框架可以根据属性类型自动判断数据库中字段的类型,但是对于Date类型仍无法确定数据库中字段类型究竟是DATE,TIME还是TIMESTAMP.此外,String的默认映射类型为VARCHAR,如果要将 String 类型映射到特定数据库的 BLOB 或TEXT字段类型.
4.@Column标注也可置于属性的getter方法之前
@Getter和@Setter(Lombok)
@Setter:注解在属性上;为属性提供 setting 方法 @Getter:注解在属性上;为属性提供 getting 方法 扩展:
@Data:注解在类上;提供类所有属性的 getting 和 setting 方法,此外还提供了equals、canEqual、hashCode、toString 方法
@Setter:注解在属性上;为属性提供 setting 方法
@Getter:注解在属性上;为属性提供 getting 方法
@Log4j2 :注解在类上;为类提供一个 属性名为log 的 log4j 日志对象,和@Log4j注解类似
@NoArgsConstructor:注解在类上;为类提供一个无参的构造方法
@AllArgsConstructor:注解在类上;为类提供一个全参的构造方法
@EqualsAndHashCode:默认情况下,会使用所有非瞬态(non-transient)和非静态(non-static)字段来生成equals和hascode方法,也可以指定具体使用哪些属性。
@toString:生成toString方法,默认情况下,会输出类名、所有属性,属性会按照顺序输出,以逗号分割。
@NoArgsConstructor, @RequiredArgsConstructor and @AllArgsConstructor
无参构造器、部分参数构造器、全参构造器,当我们需要重载多个构造器的时候,只能自己手写了
@NonNull:注解在属性上,如果注解了,就必须不能为Null
@val:注解在属性上,如果注解了,就是设置为final类型,可查看源码的注释知道
@PreUpdate和@PrePersist
@PreUpdate
1.用于为相应的生命周期事件指定回调方法。
2.该注释可以应用于实体类,映射超类或回调监听器类的方法。
3.用于setter 如果要每次更新实体时更新实体的属性,可以使用@PreUpdate注释。
4.使用该注释,您不必在每次更新用户实体时显式更新相应的属性。
5.preUpdate不允许您更改您的实体。 您只能使用传递给事件的计算的更改集来修改原始字段值。
@Prepersist
1.查看@PrePersist注释,帮助您在持久化之前自动填充实体属性。
2.可以用来在使用jpa的时记录一些业务无关的字段,比如最后更新时间等等。生命周期方法注解(delete没有生命周期事件)
3.@PrePersist save之前被调用,它可以返回一个DBObject代替一个空的 @PostPersist save到datastore之后被调用
4.@PostLoad 在Entity被映射之后被调用 @EntityListeners 指定外部生命周期事件实现类
实体Bean生命周期的回调事件
方法的标注: @PrePersist @PostPersist @PreRemove @PostRemove @PreUpdate @PostUpdate @PostLoad 。
它们标注在某个方法之前,没有任何参数。这些标注下的方法在实体的状态改变前后时进行调用,相当于拦截器;
pre 表示在状态切换前触发,post 则表示在切换后触发。
@PostLoad 事件在下列情况触发:
1. 执行 EntityManager.find()或 getreference()方法载入一个实体后;
2. 执行 JPA QL 查询过后;
3. EntityManager.refresh( )方法被调用后。
@PrePersist 和 @PostPersist事件在实体对象插入到数据库的过程中发生;
@PrePersist 事件在调用 EntityManager.persist()方法后立刻发生,级联保存也会发生此事件,此时的数据还没有真实插入进数据库。
@PostPersist 事件在数据已经插入进数据库后发生。
@PreUpdate 和 @PostUpdate 事件的触发由更新实体引起, @PreUpdate 事件在实体的状态同步到数据库之前触发,此时的数据还没有真实更新到数据库。
@PostUpdate 事件在实体的状态同步到数据库后触发,同步在事务提交时发生。
@PreRemove 和 @PostRemove 事件的触发由删除实体引起,@ PreRemove 事件在实体从数据库删除之前触发,即调用了 EntityManager.remove()方法或者级联删除
当你在执行各种持久化方法的时候,实体的状态会随之改变,状态的改变会引发不同的生命周期事件。这些事件可以使用不同的注释符来指示发生时的回调函数。
@javax.persistence.PostLoad:加载后。
@javax.persistence.PrePersist:持久化前。
@javax.persistence.PostPersist:持久化后。
@javax.persistence.PreUpdate:更新前。
@javax.persistence.PostUpdate:更新后。
@javax.persistence.PreRemove:删除前。
@javax.persistence.PostRemove:删除后。
1)数据库查询
@PostLoad事件在下列情况下触发:
执行EntityManager.find()或getreference()方法载入一个实体后。
执行JPQL查询后。
EntityManager.refresh()方法被调用后。
2)数据库插入
@PrePersist和@PostPersist事件在实体对象插入到数据库的过程中发生:
@PrePersist事件在调用persist()方法后立刻发生,此时的数据还没有真正插入进数据库。
@PostPersist事件在数据已经插入进数据库后发生。
3)数据库更新
@PreUpdate和@PostUpdate事件的触发由更新实体引起:
@PreUpdate事件在实体的状态同步到数据库之前触发,此时的数据还没有真正更新到数据库。
@PostUpdate事件在实体的状态同步到数据库之后触发,同步在事务提交时发生。
4)数据库删除
@PreRemove和@PostRemove事件的触发由删除实体引起:
@PreRemove事件在实体从数据库删除之前触发,即在调用remove()方法删除时发生,此时的数据还没有真正从数据库中删除。
@PostRemove事件在实体从数据库中删除后触发。
@NoArgsConstructor & @AllArgsConstructor(lombok)
@NoArgsConstructor,提供一个无参的构造方法。
@AllArgsConstructor,提供一个全参的构造方法。
@Configuration & @bean1.@Configuration标注在类上,相当于把该类作为spring的xml配置文件中的
package com.test.spring.support.configuration;
@Configuration
public class TestConfiguration {
public TestConfiguration(){
System.out.println("spring容器启动初始化。。。");
}
}
相当于:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context" xmlns:jdbc="http://www.springframework.org/schema/jdbc"
xmlns:jee="http://www.springframework.org/schema/jee" xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:util="http://www.springframework.org/schema/util" xmlns:task="http://www.springframework.org/schema/task" xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.0.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.0.xsd
http://www.springframework.org/schema/jdbc http://www.springframework.org/schema/jdbc/spring-jdbc-4.0.xsd
http://www.springframework.org/schema/jee http://www.springframework.org/schema/jee/spring-jee-4.0.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-4.0.xsd
http://www.springframework.org/schema/util http://www.springframework.org/schema/util/spring-util-4.0.xsd
http://www.springframework.org/schema/task http://www.springframework.org/schema/task/spring-task-4.0.xsd" default-lazy-init="false">
</beans>
主方法进行测试:
package com.test.spring.support.configuration;
public class TestMain {
public static void main(String[] args) {
//@Configuration注解的spring容器加载方式,用AnnotationConfigApplicationContext替换ClassPathXmlApplicationContext
ApplicationContext context = new AnnotationConfigApplicationContext(TestConfiguration.class);
//如果加载spring-context.xml文件:
//ApplicationContext context = new ClassPathXmlApplicationContext("spring-context.xml");
}
}
从运行主方法结果可以看出,spring容器已经启动了:
1 八月 11, 2016 12:04:11 下午 org.springframework.context.annotation.AnnotationConfigApplicationContext prepareRefresh
2 信息: Refreshing org.springframework.context.annotation.AnnotationConfigApplicationContext@203e25d3: startup date [Thu Aug 11 12:04:11 CST 2016]; root of context hierarchy
3 spring容器启动初始化。。。
2.@Bean标注在方法上(返回某个实例的方法),等价于spring的xml配置文件中的
bean类:
package com.test.spring.support.configuration;
public class TestBean {
public void sayHello(){
System.out.println("TestBean sayHello...");
}
public String toString(){
return "username:"+this.username+",url:"+this.url+",password:"+this.password;
}
public void start(){
System.out.println("TestBean 初始化。。。");
}
public void cleanUp(){
System.out.println("TestBean 销毁。。。");
}
}
配置类:
package com.test.spring.support.configuration;
@Configuration
public class TestConfiguration {
public TestConfiguration(){
System.out.println("spring容器启动初始化。。。");
}
//@Bean注解注册bean,同时可以指定初始化和销毁方法
//@Bean(name="testNean",initMethod="start",destroyMethod="cleanUp")
@Bean
@Scope("prototype")
public TestBean testBean() {
return new TestBean();
}
}
主方法测试类:
package com.test.spring.support.configuration;
public class TestMain {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(TestConfiguration.class);
//获取bean
TestBean tb = context.getBean("testBean");
tb.sayHello();
}
}
注:
(1)、@Bean注解在返回实例的方法上,如果未通过@Bean指定bean的名称,则默认与标注的方法名相同;
(2)、@Bean注解默认作用域为单例singleton作用域,可通过@Scope(“prototype”)设置为原型作用域;
(3)、既然@Bean的作用是注册bean对象,那么完全可以使用@Component、@Controller、@Service、@Ripository等注解注册bean,当然需要配置@ComponentScan注解进行自动扫描。
bean类:
package com.test.spring.support.configuration;
//添加注册bean的注解
@Component
public class TestBean {
public void sayHello(){
System.out.println("TestBean sayHello...");
}
public String toString(){
return "username:"+this.username+",url:"+this.url+",password:"+this.password;
}
}
配置类:
//开启注解配置
@Configuration
//添加自动扫描注解,basePackages为TestBean包路径
@ComponentScan(basePackages = "com.test.spring.support.configuration")
public class TestConfiguration {
public TestConfiguration(){
System.out.println("spring容器启动初始化。。。");
}
//取消@Bean注解注册bean的方式
//@Bean
//@Scope("prototype")
//public TestBean testBean() {
// return new TestBean();
//}
}
主方法测试获取bean对象:
public class TestMain {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(TestConfiguration.class);
//获取bean
TestBean tb = context.getBean("testBean");
tb.sayHello();
}
}
sayHello()方法都被正常调用。
使用@Configuration注解来代替Spring的bean配置
下面是一个典型的Spring配置文件(application-config.xml):
<beans>
<bean id="orderService" class="com.acme.OrderService"/>
<constructor-arg ref="orderRepository"/>
</bean>
<bean id="orderRepository" class="com.acme.OrderRepository"/>
<constructor-arg ref="dataSource"/>
</bean>
</beans>
然后你就可以像这样来使用是bean了:
1 ApplicationContext ctx = new ClassPathXmlApplicationContext(“application-config.xml”); 2 OrderService orderService = (OrderService) ctx.getBean(“orderService”); 现在Spring Java Configuration这个项目提供了一种通过java代码来装配bean的方案:
@Configuration
public class ApplicationConfig {
public @Bean OrderService orderService() {
return new OrderService(orderRepository());
}
public @Bean OrderRepository orderRepository() {
return new OrderRepository(dataSource());
}
public @Bean DataSource dataSource() {
// instantiate and return an new DataSource …
}
}
然后你就可以像这样来使用是bean了:
JavaConfigApplicationContext ctx = new JavaConfigApplicationContext(ApplicationConfig.class);
OrderService orderService = ctx.getBean(OrderService.class);
这么做有什么好处呢?
- 1.使用纯java代码,不在需要xml
- 2.在配置中也可享受OO带来的好处(面向对象)
- 3.类型安全对重构也能提供良好的支持
- 4.减少复杂配置文件的同时依旧能享受到所有springIoC容器提供的功能
容器互联
如果你之前有 Docker 使用经验,你可能已经习惯了使用 –link 参数来使容器互联。
随着 Docker 网络的完善,强烈建议大家将容器加入自定义的 Docker 网络来连接多个容器,而不是使用 –link 参数。
新建网络
下面先创建一个新的 Docker 网络。
$ docker network create -d bridge my-net
-d 参数指定 Docker 网络类型,有 bridge overlay。其中 overlay 网络类型用于 Swarm mode,在本小节中你可以忽略它。
连接容器
运行一个容器并连接到新建的 my-net 网络
$ docker run -it --rm --name busybox1 --network my-net busybox sh
打开新的终端,再运行一个容器并加入到 my-net 网络
$ docker run -it --rm --name busybox2 --network my-net busybox sh
再打开一个新的终端查看容器信息
$ docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b47060aca56b busybox "sh" 11 minutes ago Up 11 minutes busybox2
8720575823ec busybox "sh" 16 minutes ago Up 16 minutes busybox1
- 下面通过 ping 来证明 busybox1 容器和 busybox2 容器建立了互联关系。
- 在 busybox1 容器输入以下命令
/ # ping busybox2 PING busybox2 (172.19.0.3): 56 data bytes 64 bytes from 172.19.0.3: seq=0 ttl=64 time=0.072 ms 64 bytes from 172.19.0.3: seq=1 ttl=64 time=0.118 ms
- 在 busybox1 容器输入以下命令
-
用 ping 来测试连接 busybox2 容器,它会解析成 172.19.0.3。
- 同理在 busybox2 容器执行 ping busybox1,也会成功连接到。
/ # ping busybox1 PING busybox1 (172.19.0.2): 56 data bytes 64 bytes from 172.19.0.2: seq=0 ttl=64 time=0.064 ms 64 bytes from 172.19.0.2: seq=1 ttl=64 time=0.143 ms这样,busybox1 容器和 busybox2 容器建立了互联关系。
Docker Compose
如果你有多个容器之间需要互相连接,推荐使用 Docker Compose。
Dockerfile 最佳实践
本附录是笔者对 Docker 官方文档中 Intro Guide to Dockerfile Best Practices 的理解与翻译。
一般性的指南和建议
容器应该是短暂的
通过 Dockerfile 构建的镜像所启动的容器应该尽可能短暂(生命周期短)。「短暂」意味着可以停止和销毁容器,并且创建一个新容器并部署好所需的设置和配置工作量应该是极小的。
使用 .dockerignore 文件
使用 Dockerfile 构建镜像时最好是将 Dockerfile 放置在一个新建的空目录下。然后将构建镜像所需要的文件添加到该目录中。为了提高构建镜像的效率,你可以在目录下新建一个 .dockerignore 文件来指定要忽略的文件和目录。.dockerignore 文件的排除模式语法和 Git 的 .gitignore 文件相似。
使用多阶段构建
在 Docker 17.05 以上版本中,你可以使用 多阶段构建 来减少所构建镜像的大小。
避免安装不必要的包
为了降低复杂性、减少依赖、减小文件大小、节约构建时间,你应该避免安装任何不必要的包。例如,不要在数据库镜像中包含一个文本编辑器。
一个容器只运行一个进程
应该保证在一个容器中只运行一个进程。将多个应用解耦到不同容器中,保证了容器的横向扩展和复用。例如 web 应用应该包含三个容器:web应用、数据库、缓存。
如果容器互相依赖,你可以使用 Docker 自定义网络 来把这些容器连接起来。
镜像层数尽可能少
你需要在 Dockerfile 可读性(也包括长期的可维护性)和减少层数之间做一个平衡。
将多行参数排序
将多行参数按字母顺序排序(比如要安装多个包时)。这可以帮助你避免重复包含同一个包,更新包列表时也更容易。也便于 PRs 阅读和审查。建议在反斜杠符号 \ 之前添加一个空格,以增加可读性。
下面是来自 buildpack-deps 镜像的例子:
RUN apt-get update && apt-get install -y \
bzr \
cvs \
git \
mercurial \
subversion
构建缓存
在镜像的构建过程中,Docker 会遍历 Dockerfile 文件中的指令,然后按顺序执行。在执行每条指令之前,Docker 都会在缓存中查找是否已经存在可重用的镜像,如果有就使用现存的镜像,不再重复创建。如果你不想在构建过程中使用缓存,你可以在 docker build 命令中使用 –no-cache=true 选项。
但是,如果你想在构建的过程中使用缓存,你得明白什么时候会,什么时候不会找到匹配的镜像,遵循的基本规则如下:
- 从一个基础镜像开始(FROM 指令指定),下一条指令将和该基础镜像的所有子镜像进行匹配,检查这些子镜像被创建时使用的指令是否和被检查的指令完全一样。如果不是,则缓存失效。
- 在大多数情况下,只需要简单地对比 Dockerfile 中的指令和子镜像。然而,有些指令需要更多的检查和解释。
- 对于 ADD 和 COPY 指令,镜像中对应文件的内容也会被检查,每个文件都会计算出一个校验和。文件的最后修改时间和最后访问时间不会纳入校验。在缓存的查找过程中,会将这些校验和和已存在镜像中的文件校验和进行对比。如果文件有任何改变,比如内容和元数据,则缓存失效。
- 除了 ADD 和 COPY 指令,缓存匹配过程不会查看临时容器中的文件来决定缓存是否匹配。例如,当执行完 RUN apt-get -y update 指令后,容器中一些文件被更新,但 Docker 不会检查这些文件。这种情况下,只有指令字符串本身被用来匹配缓存。 一旦缓存失效,所有后续的 Dockerfile 指令都将产生新的镜像,缓存不会被使用。
Dockerfile 指令
下面针对 Dockerfile 中各种指令的最佳编写方式给出建议。
FROM
尽可能使用当前官方仓库作为你构建镜像的基础。推荐使用 Alpine 镜像,因为它被严格控制并保持最小尺寸(目前小于 5 MB),但它仍然是一个完整的发行版。
LABEL
你可以给镜像添加标签来帮助组织镜像、记录许可信息、辅助自动化构建等。每个标签一行,由 LABEL 开头加上一个或多个标签对。下面的示例展示了各种不同的可能格式。# 开头的行是注释内容。
注意:如果你的字符串中包含空格,必须将字符串放入引号中或者对空格使用转义。如果字符串内容本身就包含引号,必须对引号使用转义。
# Set one or more individual labels
LABEL com.example.version="0.0.1-beta"
LABEL vendor="ACME Incorporated"
LABEL com.example.release-date="2015-02-12"
LABEL com.example.version.is-production=""
一个镜像可以包含多个标签,但建议将多个标签放入到一个 LABEL 指令中。
# Set multiple labels at once, using line-continuation characters to break long lines
LABEL vendor=ACME\ Incorporated \
com.example.is-beta= \
com.example.is-production="" \
com.example.version="0.0.1-beta" \
com.example.release-date="2015-02-12"
关于标签可以接受的键值对,参考 Understanding object labels。关于查询标签信息,参考 Managing labels on objects。
RUN
为了保持 Dockerfile 文件的可读性,可理解性,以及可维护性,建议将长的或复杂的 RUN 指令用反斜杠 \ 分割成多行。
apt-get
RUN 指令最常见的用法是安装包用的 apt-get。因为 RUN apt-get 指令会安装包,所以有几个问题需要注意。
不要使用 RUN apt-get upgrade 或 dist-upgrade,因为许多基础镜像中的「必须」包不会在一个非特权容器中升级。如果基础镜像中的某个包过时了,你应该联系它的维护者。如果你确定某个特定的包,比如 foo,需要升级,使用 apt-get install -y foo 就行,该指令会自动升级 foo 包。
永远将 RUN apt-get update 和 apt-get install 组合成一条 RUN 声明,例如:
RUN apt-get update && apt-get install -y \
package-bar \
package-baz \
package-foo
将 apt-get update 放在一条单独的 RUN 声明中会导致缓存问题以及后续的 apt-get install 失败。比如,假设你有一个 Dockerfile 文件:
FROM ubuntu:18.04
RUN apt-get update
RUN apt-get install -y curl
构建镜像后,所有的层都在 Docker 的缓存中。假设你后来又修改了其中的 apt-get install 添加了一个包:
FROM ubuntu:18.04
RUN apt-get update
RUN apt-get install -y curl nginx
Docker 发现修改后的 RUN apt-get update 指令和之前的完全一样。所以,apt-get update 不会执行,而是使用之前的缓存镜像。因为 apt-get update 没有运行,后面的 apt-get install 可能安装的是过时的 curl 和 nginx 版本。
使用 RUN apt-get update && apt-get install -y 可以确保你的 Dockerfiles 每次安装的都是包的最新的版本,而且这个过程不需要进一步的编码或额外干预。这项技术叫作 cache busting。你也可以显示指定一个包的版本号来达到 cache-busting,这就是所谓的固定版本,例如:
RUN apt-get update && apt-get install -y \
package-bar \
package-baz \
package-foo=1.3.*
固定版本会迫使构建过程检索特定的版本,而不管缓存中有什么。这项技术也可以减少因所需包中未预料到的变化而导致的失败。
下面是一个 RUN 指令的示例模板,展示了所有关于 apt-get 的建议。
RUN apt-get update && apt-get install -y \
aufs-tools \
automake \
build-essential \
curl \
dpkg-sig \
libcap-dev \
libsqlite3-dev \
mercurial \
reprepro \
ruby1.9.1 \
ruby1.9.1-dev \
s3cmd=1.1.* \
&& rm -rf /var/lib/apt/lists/*
其中 s3cmd 指令指定了一个版本号 1.1.* 。如果之前的镜像使用的是更旧的版本,指定新的版本会导致 apt-get udpate 缓存失效并确保安装的是新版本。
另外,清理掉 apt 缓存 var/lib/apt/lists 可以减小镜像大小。因为 RUN 指令的开头为 apt-get udpate,包缓存总是会在 apt-get install 之前刷新。
注意:官方的 Debian 和 Ubuntu 镜像会自动运行 apt-get clean,所以不需要显式的调用 apt-get clean。
CMD
CMD 指令用于执行目标镜像中包含的软件,可以包含参数。CMD 大多数情况下都应该以 CMD [“executable”, “param1”, “param2”…] 的形式使用。因此,如果创建镜像的目的是为了部署某个服务(比如 Apache),你可能会执行类似于 CMD [“apache2”, “-DFOREGROUND”] 形式的命令。我们建议任何服务镜像都使用这种形式的命令。
多数情况下,CMD 都需要一个交互式的 shell (bash, Python, perl 等),例如 CMD [“perl”, “-de0”],或者 CMD [“PHP”, “-a”]。使用这种形式意味着,当你执行类似 docker run -it python 时,你会进入一个准备好的 shell 中。CMD 应该在极少的情况下才能以 CMD [“param”, “param”] 的形式与 ENTRYPOINT 协同使用,除非你和你的镜像使用者都对 ENTRYPOINT 的工作方式十分熟悉。
EXPOSE
EXPOSE 指令用于指定容器将要监听的端口。因此,你应该为你的应用程序使用常见的端口。例如,提供 Apache web 服务的镜像应该使用 EXPOSE 80,而提供 MongoDB 服务的镜像使用 EXPOSE 27017。
对于外部访问,用户可以在执行 docker run 时使用一个标志来指示如何将指定的端口映射到所选择的端口。
ENV
为了方便新程序运行,你可以使用 ENV 来为容器中安装的程序更新 PATH 环境变量。例如使用 ENV PATH /usr/local/nginx/bin:$PATH 来确保 CMD [“nginx”] 能正确运行。
ENV 指令也可用于为你想要容器化的服务提供必要的环境变量,比如 Postgres 需要的 PGDATA。
最后,ENV 也能用于设置常见的版本号,比如下面的示例:
ENV PG_MAJOR 9.3
ENV PG_VERSION 9.3.4
RUN curl -SL http://example.com/postgres-$PG_VERSION.tar.xz | tar -xJC /usr/src/postgress && …
ENV PATH /usr/local/postgres-$PG_MAJOR/bin:$PATH
类似于程序中的常量,这种方法可以让你只需改变 ENV 指令来自动的改变容器中的软件版本。
ADD 和 COPY
虽然 ADD 和 COPY 功能类似,但一般优先使用 COPY。因为它比 ADD 更透明。COPY 只支持简单将本地文件拷贝到容器中,而 ADD 有一些并不明显的功能(比如本地 tar 提取和远程 URL 支持)。因此,ADD 的最佳用例是将本地 tar 文件自动提取到镜像中,例如 ADD rootfs.tar.xz。
如果你的 Dockerfile 有多个步骤需要使用上下文中不同的文件。单独 COPY 每个文件,而不是一次性的 COPY 所有文件,这将保证每个步骤的构建缓存只在特定的文件变化时失效。例如:
COPY requirements.txt /tmp/
RUN pip install --requirement /tmp/requirements.txt
COPY . /tmp/
如果将 COPY . /tmp/ 放置在 RUN 指令之前,只要 . 目录中任何一个文件变化,都会导致后续指令的缓存失效。
为了让镜像尽量小,最好不要使用 ADD 指令从远程 URL 获取包,而是使用 curl 和 wget。这样你可以在文件提取完之后删掉不再需要的文件来避免在镜像中额外添加一层。比如尽量避免下面的用法:
ADD http://example.com/big.tar.xz /usr/src/things/
RUN tar -xJf /usr/src/things/big.tar.xz -C /usr/src/things
RUN make -C /usr/src/things all
而是应该使用下面这种方法:
RUN mkdir -p /usr/src/things \
&& curl -SL http://example.com/big.tar.xz \
| tar -xJC /usr/src/things \
&& make -C /usr/src/things all
上面使用的管道操作,所以没有中间文件需要删除。
对于其他不需要 ADD 的自动提取功能的文件或目录,你应该使用 COPY。
ENTRYPOINT
ENTRYPOINT 的最佳用处是设置镜像的主命令,允许将镜像当成命令本身来运行(用 CMD 提供默认选项)。
例如,下面的示例镜像提供了命令行工具 s3cmd:
ENTRYPOINT ["s3cmd"]
CMD ["--help"]
现在直接运行该镜像创建的容器会显示命令帮助:
$ docker run s3cmd
或者提供正确的参数来执行某个命令:
$ docker run s3cmd ls s3://mybucket
这样镜像名可以当成命令行的参考。
ENTRYPOINT 指令也可以结合一个辅助脚本使用,和前面命令行风格类似,即使启动工具需要不止一个步骤。
例如,Postgres 官方镜像使用下面的脚本作为 ENTRYPOINT:
#!/bin/bash
set -e
if [ "$1" = 'postgres' ]; then
chown -R postgres "$PGDATA"
if [ -z "$(ls -A "$PGDATA")" ]; then
gosu postgres initdb
fi
exec gosu postgres "$@"
fi
exec "$@"
注意:该脚本使用了 Bash 的内置命令 exec,所以最后运行的进程就是容器的 PID 为 1 的进程。这样,进程就可以接收到任何发送给容器的 Unix 信号了。
该辅助脚本被拷贝到容器,并在容器启动时通过 ENTRYPOINT 执行:
COPY ./docker-entrypoint.sh /
ENTRYPOINT ["/docker-entrypoint.sh"]
该脚本可以让用户用几种不同的方式和 Postgres 交互。
你可以很简单地启动 Postgres:
$ docker run postgres
也可以执行 Postgres 并传递参数:
$ docker run postgres postgres --help
最后,你还可以启动另外一个完全不同的工具,比如 Bash:
$ docker run --rm -it postgres bash
VOLUME
VOLUME 指令用于暴露任何数据库存储文件,配置文件,或容器创建的文件和目录。强烈建议使用 VOLUME 来管理镜像中的可变部分和用户可以改变的部分。
USER
如果某个服务不需要特权执行,建议使用 USER 指令切换到非 root 用户。先在 Dockerfile 中使用类似 RUN groupadd -r postgres && useradd -r -g postgres postgres 的指令创建用户和用户组。
注意:在镜像中,用户和用户组每次被分配的 UID/GID 都是不确定的,下次重新构建镜像时被分配到的 UID/GID 可能会不一样。如果要依赖确定的 UID/GID,你应该显示的指定一个 UID/GID。
你应该避免使用 sudo,因为它不可预期的 TTY 和信号转发行为可能造成的问题比它能解决的问题还多。如果你真的需要和 sudo 类似的功能(例如,以 root 权限初始化某个守护进程,以非 root 权限执行它),你可以使用 gosu。
最后,为了减少层数和复杂度,避免频繁地使用 USER 来回切换用户。
WORKDIR
为了清晰性和可靠性,你应该总是在 WORKDIR 中使用绝对路径。另外,你应该使用 WORKDIR 来替代类似于 RUN cd … && do-something 的指令,后者难以阅读、排错和维护。
Dockerfile 指令详解
339 post articles, 43 pages.