BeanFactory和ApplicationContext的区别(Bean工厂和应用上下文)
BeanFactory和ApplicationContext 接口及其子类图

BeanFactory
BeanFactory是spring的原始接口,针对原始结构的实现类功能比较单一,BeanFactory接口实现的容器,特点是在每次获取对象时才会创建对象。
ApplicationContext
继承了BeanFactory接口,拥有BeanFactory的全部功能,并且扩展了很多高级特性,每次容器启动时就会创建所有的对象。
创建ApplicationContext的方法:
- 丛类路径下加载配置文件:ClassPathXmlApplicationContext (“applicationContext.xml”);
- 从硬盘绝对路径下加载配置文件: FileSystemXmlApplicationContext(“d:/xxx/yyy/xxx”);
结论
早期的电脑性能低,内存小,所以spring容器的容量不足,不能讲所以的对象全部创建好放入容器,所以使用的是BeanFactory,需要某个对象时,再进行创建,随着电脑硬件的发展,内存越来越大,所以spring框架引入了ApplicationContext,将所有的对象都创建好,放入容器,使用哪个对象,从容器中取得即可。
所以,web开发中,使用applicationContext. 在资源匮乏的环境可以使用BeanFactory.
BeanFactory 和ApplicationContext (详细说明)
- Bean 工厂(com.springframework.beans.factory.BeanFactory)是Spring 框架最核心的接口,它提供了高级IoC 的配置机制。
- 应用上下文(com.springframework.context.ApplicationContext)建立在BeanFactory 基础之上。
几乎所有的应用场合我们都直接使用ApplicationContext 而非底层的BeanFactory。
1.1 BeanFactory 的类体系结构
BeanFactory: 接口位于类结构树的顶端, 它最主要的方法就是getBean(StringbeanName),该方法从容器中返回特定名称的Bean,BeanFactory 的功能通过其他的接口得到不断扩展。
ListableBeanFactory:该接口定义了访问容器中Bean 基本信息的若干方法,如查看Bean 的个数、获取某一类型Bean 的配置名、查看容器中是否包括某一Bean 等方法;
HierarchicalBeanFactory:父子级联IoC 容器的接口,子容器可以通过接口方法访问父容器;
ConfigurableBeanFactory:是一个重要的接口,增强了IoC 容器的可定制性,它定义了设置类装载器、属性编辑器、容器初始化后置处理器等方法;
AutowireCapableBeanFactory:定义了将容器中的Bean 按某种规则(如按名字匹配、按类型匹配等)进行自动装配的方法;
SingletonBeanRegistry:定义了允许在运行期间向容器注册单实例Bean 的方法;
BeanDefinitionRegistry:Spring 配置文件中每一个
1.2 ApplicationContext 的类体系结构
ApplicationContext 由BeanFactory 派生而来,提供了更多面向实际应用的功能。在BeanFactory 中,很多功能需要以编程的方式实现,而在ApplicationContext 中则可以通过配置的方式实现。 ApplicationContext 的主要实现类是ClassPathXmlApplicationContext 和FileSystemXmlApplicationContext,前者默认从类路径加载配置文件,后者默认从文件系统中装载配置文件。
核心接口包括: ApplicationEventPublisher:让容器拥有发布应用上下文事件的功能,包括容器启动事件、关闭事件等。实现了ApplicationListener 事件监听接口的Bean 可以接收到容器事件, 并对事件进行响应处理。在ApplicationContext 抽象实现类AbstractApplicationContext 中,我们可以发现存在一个ApplicationEventMulticaster,它负责保存所有监听器,以便在容器产生上下文事件时通知这些事件监听 者。 MessageSource:为应用提供i18n 国际化消息访问的功能; ResourcePatternResolver : 所有ApplicationContext 实现类都实现了类似于PathMatchingResourcePatternResolver 的功能,可以通过带前缀的Ant 风格的资源文件路径装载Spring 的配置文件。 LifeCycle:该接口是Spring 2.0 加入的,该接口提供了start()和stop()两个方法,主要用于控制异步处理过程。在具体使用时,该接口同时被 ApplicationContext 实现及具体Bean 实现,ApplicationContext 会将start/stop 的信息传递给容器中所有实现了该接口的Bean,以达到管理和控制JMX、任务调度等目的。 ConfigurableApplicationContext 扩展于ApplicationContext,它新增加了两个主要的方法:refresh()和close(),让ApplicationContext 具有启动、刷新和关闭应用上下文的能力。在应用上下文关闭的情况下调用refresh()即可启动应用上下文,在已经启动的状态下,调用 refresh()则清除缓存并重新装载配置信息,而调用close()则可关闭应用上下文。这些接口方法为容器的控制管理带来了便利.
代码示例:
ApplicationContext ctx =new ClassPathXmlApplicationContext("com/baobaotao/context/beans.xml");
ApplicationContext ctx =new FileSystemXmlApplicationContext("com/baobaotao/context/beans.xml");
ApplicationContext ctx = new ClassPathXmlApplicationContext(new String[]{"conf/beans1.xml","conf/beans2.xml"});
ApplicationContext 的初始化和BeanFactory 有一个重大的区别:BeanFactory在初始化容器时,并未实例化Bean,直到第一次访问某个Bean 时才实例目标Bean;而ApplicationContext 则在初始化应用上下文时就实例化所有单实例的Bean 。
降低Redis内存占用
1、降低redis内存占用的优点
1、有助于减少创建快照和加载快照所用的时间
2、提升载入AOF文件和重写AOF文件时的效率
3、缩短从服务器进行同步所需的时间
4、无需添加额外的硬件就可以让redis存贮更多的数据
2、短结构
Redis为列表、集合、散列、有序集合提供了一组配置选项,这些选项可以让redis以更节约的方式存储较短的结构。
2.1、ziplist压缩列表(列表、散列、有续集和)
通常情况下使用的存储方式

当列表、散列、有序集合的长度较短或者体积较小的时候,redis将会采用一种名为ziplist的紧凑存储方式来存储这些结构。
ziplist是列表、散列、有序集合这三种不同类型的对象的一种非结构化表示,它会以序列化的方式存储数据,这些序列化的数据每次被读取的时候都需要进行解码,每次写入的时候也要进行编码。
双向列表与压缩列表的区别:
为了了解压缩列表比其他数据结构更加节约内存,我们以列表结构为例进行深入研究。
典型的双向列表
1、在典型双向列表里面,每个值都都会有一个节点表示。每个节点都会带有指向链表前一个节点和后一个节点的指针,以及一个指向节点包含的字符串值的指针。
2、每个节点包含的字符串值都会分为三部分进行存储。包括字符串长度、字符串值中剩余可用字节数量、以空字符结尾的字符串本身。
例子:
假若一个某个节点存储了’abc’字符串,在32位的平台下保守估计需要21个字节的额外开销(三个指针+两个int+空字符即:34+24+1=21)
由例子可知存储一个3字节字符串就需要付出至少21个字节的额外开销。
ziplist
压缩列表是由节点组成的序列,每个节点包含两个长度和一个字符串。第一个长度记录前一个节点的长度(用于对压缩列表从后向前遍历);第二个长度是记录本当前点的长度;被存储的字符串。
例子:
存储字符串’abc’,两个长度都可以用1字节来存储,因此所带来的额外开销为2字节(两个长度即1+1=2)
结论:
压缩列表是通过避免存储额外的指针和元数据,从而达到降低额外的开销。
配置:
1 #list2 list-max-ziplist-entries 51
2 #表示允许包含的最大元素数量
3 list-max-ziplist-value 64 #表示压缩节点允许存储的最大体积
4 #hash #当超过任一限制后,将不会使用ziplist方式进行存储
5 hash-max-ziplist-entries 512
6 hash-max-ziplist-value 64
7 #zset
8 zset-max-ziplist-entries 128
9 zset-max-ziplist-value 64
测试list:
1、建立test.php文件
1 #test.php
2 <?php
3 $redis=new Redis();
4 $redis->connect('192.168.95.11','6379');
5 for ($i=0; $i<512 ; $i++)
6 {
7 $redis->lpush('test-list',$i.'-test-list'); #往test-list推入512条数据
8 }
9 ?>

此时的test-list中含有512条数据,没有超除配置文件中的限制
2、往test-list中再推入一条数据

此时test-list含有513条数据,大于配置文件中限制的512条,索引将放弃ziplist存储方式,采用其原来的linkedlist存储方式,散列与有序集合同理。
2.2、intset整数集合(集合)
前提条件,集合中包含的所有member都可以被解析为十进制整数。
以有序数组的方式存储集合不仅可以降低内存消耗,还可以提升集合操作的执行速度。
配置:
1 set-max-intset-entries 512 #限制集合中member个数,超出则不采取i那个tset存储
测试:
建立test.php文件
1 #test.php
2 <?php
3 $redis=new Redis();
4 $redis->connect('192.168.95.11','6379');
5 for ($i=0; $i<512 ; $i++)
6 {
7 $redis->sadd('test-set',$i); #给集合test-set插入512个member
8 }
9 ?>
10
2.3、性能问题
不管列表、散列、有序集合、集合,当超出限制的条件后,就会转换为更为典型的底层结构类型。因为随着紧凑结构的体积不断变大,操作这些结构的速度将会变得越来越慢。
测试:
#将采用list进行代表性测试
测试思路:
1、在默认配置下往test-list推入50000条数据,查看所需时间;接着在使用rpoplpush将test-list数据全部推入到新列表list-new中,查看所需时间
2、修改配置,list-max-ziplist-entries 100000,再执行上面的同样操作
3、对比时间,得出结论
默认配置下测试:
1、插入数据,查看时间
1 #test1.php
2 <?php
3 header("content-type: text/html;charset=utf8;");
4 $redis=new Redis();
5 $redis->connect('192.168.95.11','6379');
6 $start=time();
7 for ($i=0; $i<50000 ; $i++)
8 {
9 $redis->lpush('test-list',$i.'-aaaassssssddddddkkk');
10 }
11 $end=time();
12 echo "插入耗时为:".($end-$start).'s';
13 ?>

结果耗时4秒
2、执行相应命令,查看耗时
1 #test2.php
2 <?php
3 header("content-type: text/html;charset=utf8;");
4 $redis=new Redis();
5 $redis->connect('192.168.95.11','6379');
6 $start=time();
7 $num=0;
8 while($redis->rpoplpush('test-list','test-new'))
9 {
10 $num+=1;
11 }
12 echo '执行次数为:'.$num."<br/>";
13 $end=time();
14 echo "耗时为:".($end-$start).'s';
15 ?>
更改配置文件下测试
1、先修改配置文件
list-max-ziplist-entries 100000 #将这个值修改大一点,可以更好的凸显对性能的影响
list-max-ziplist-value 64 #此值可不做修改
2、插入数据
执行test1.php
结果为:耗时12s

3、执行相应命令,查看耗时
执行test2.php
结果为:执行次数:50000,耗时12s
结论:
在本机中执行测试50000条数据就相差8s,若在高并发下,长压缩列表和大整数集合将起不到任何的优化,反而使得性能降低。
3、片结构
分片的本质就是基于简单的规则将数据划分为更小的部分,然后根据数据所属的部分来决定将数据发送到哪个位置上。很多数据库使用这种技术来扩展存储空间,并提高自己所能处理的负载量。
结合前面讲到的,我们不难发现分片结构对于redis的重要意义。因此我们需要在配置文件中关于ziplist以及intset的相关配置做出适当的调整。
3.1、分片式散列
#ShardHash.class.php
散列分片主要是根据基础键以及散列包含的键计算出分片键ID,然后再与基础键拼接成一个完整的分片键。在执行hset与hget以及大部分hash命令时,都需要先将key(field)通过shardKey方法处理,得到分片键才能够进行下一步操作。
回到顶部
3.2、分片式集合
如何构造分片式集合才能够让它更节省内存,性能更加强大呢?主要的思路就是,将集合里面的存储的数据尽量在不改变其原有功能的情况下转换成可以被解析为十进制的数据。根据前面所讲到的,当集合中的所有成员都能够被解析为十进制数据时,将会采用intset存储方式,这不仅能够节省内存,而且还可以提高响应的性能。
4、将信息打包转换成存储字节
结合前面所讲的分片技术,采用string分片结构为大量连续的ID用户存储信息。
使用定长字符串,为每一个ID分配n个字节进行存储相应的信息。
单进程单线程的Redis如何能够高并发
1、基本原理
采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗)
(1)为什么不采用多进程或多线程处理?
多线程处理可能涉及到锁
多线程处理会涉及到线程切换而消耗CPU
(2)单线程处理的缺点?
无法发挥多核CPU性能,不过可以通过在单机开多个Redis实例来完善
2、Redis不存在线程安全问题?
Redis采用了线程封闭的方式,把任务封闭在一个线程,自然避免了线程安全问题,不过对于需要依赖多个redis操作的复合操作来说,依然需要锁,而且有可能是分布式锁
3、什么是多路I/O复用(Epoll)
(1) 网络IO都是通过Socket实现,Server在某一个端口持续监听,客户端通过Socket(IP+Port)与服务器建立连接(ServerSocket.accept),成功建立连接之后,就可以使用Socket中封装的InputStream和OutputStream进行IO交互了。针对每个客户端,Server都会创建一个新线程专门用于处理 (2) 默认情况下,网络IO是阻塞模式,即服务器线程在数据到来之前处于【阻塞】状态,等到数据到达,会自动唤醒服务器线程,着手进行处理。阻塞模式下,一个线程只能处理一个流的IO事件 (3) 为了提升服务器线程处理效率,有以下三种思路
(1)非阻塞【忙轮询】:采用死循环方式轮询每一个流,如果有IO事件就处理,这样可以使得一个线程可以处理多个流,但是效率不高,容易导致CPU空转
(2)Select代理(无差别轮询):可以观察多个流的IO事件,如果所有流都没有IO事件,则将线程进入阻塞状态,如果有一个或多个发生了IO事件,则唤醒线程去处理。但是还是得遍历所有的流,才能找出哪些流需要处理。如果流个数为N,则时间复杂度为O(N)
(3)Epoll代理:Select代理有一个缺点,线程在被唤醒后轮询所有的Stream,还是存在无效操作。 Epoll会哪个流发生了怎样的I/O事件通知处理线程,因此对这些流的操作都是有意义的,复杂度降低到了O(1)
4、其它开源软件采用的模型
Nginx:多进程单线程模型
Memcached:单进程多线程模型
Redis为什么是单线程的?
因为CPU不是Redis的瓶颈。Redis的瓶颈最有可能是机器内存或者网络带宽。(以上主要来自官方FAQ)既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了。关于redis的性能,官方网站也有,普通笔记本轻松处理每秒几十万的请求,参见:How fast is Redis?
如果万一CPU成为你的Redis瓶颈了,或者,你就是不想让服务器其他核闲置,那怎么办?
那也很简单,你多起几个Redis进程就好了。Redis是keyvalue数据库,又不是关系数据库,数据之间没有约束。只要客户端分清哪些key放在哪个Redis进程上就可以了。redis-cluster可以帮你做的更好。
单线程可以处理高并发请求吗?
当然可以了,Redis都实现了。
有一点概念需要澄清,并发并不是并行。
(相关概念:并发性I/O流,意味着能够让一个计算单元来处理来自多个客户端的流请求。并行性,意味着服务器能够同时执行几个事情,具有多个计算单元)
Redis总体快速的原因:
采用队列模式将并发访问变为串行访问(?)
单线程指的是网络请求模块使用了一个线程(所以不需考虑并发安全性),其他模块仍用了多个线程。
总体来说快速的原因如下:
1)绝大部分请求是纯粹的内存操作(非常快速)
2)采用单线程,避免了不必要的上下文切换和竞争条件
3)非阻塞IO
内部实现采用epoll,采用了epoll+自己实现的简单的事件框架。epoll中的读、写、关闭、连接都转化成了事件,然后利用epoll的多路复用特性,绝不在io上浪费一点时间
这3个条件不是相互独立的,特别是第一条,如果请求都是耗时的,采用单线程吞吐量及性能可想而知了。应该说redis为特殊的场景选择了合适的技术方案。
- Redis服务端是个单线程的架构,不同的Client虽然看似可以同时保持连接,但发出去的命令是序列化执行的,这在通常的数据库理论下是最高级别的隔离(serialize)
- 用MULTI/EXEC 来把多个命令组装成一次发送,达到原子性
- 用WATCH提供的乐观锁功能,在你EXEC的那一刻,如果被WATCH的键发生过改动,则MULTI到EXEC之间的指令全部不执行,不需要rollback
- 其他回答中提到的DISCARD指令只是用来撤销EXEC之前被暂存的指令,并不是回滚
多线程对同一个Key操作时,Redis服务是根据先到先作的原则,其他排队(可设置为直接丢弃),因为是单线程。
修改默认的超时时间,默认2秒。但是大部份的操作都在30ms以内。
-
使用Redis有哪些好处?
(1) 速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
(2) 支持丰富数据类型,支持string,list,set,sorted set,hash
(3) 支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
(4) 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
-
Redis相比memcached有哪些优势?
(1) memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型
(2) redis的速度比memcached快很多
(3) redis可以持久化其数据
(4)Redis支持数据的备份,即master-slave模式的数据备份。
(5)、使用底层模型不同
它们之间底层实现方式 以及与客户端之间通信的应用协议不一样。
Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
(6)value大小:redis最大可以达到1GB,而memcache只有1MB
-
redis常见性能问题和解决方案:
(1) Master最好不要做任何持久化工作,如RDB内存快照和AOF日志文件
(Master写内存快照,save命令调度rdbSave函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以Master最好不要写内存快照;AOF文件过大会影响Master重启的恢复速度)
(2) 如果数据比较重要,某个Slave开启AOF备份数据,策略设置为每秒同步一次
(3) 为了主从复制的速度和连接的稳定性,Master和Slave最好在同一个局域网内
(4) 尽量避免在压力很大的主库上增加从库
(5) 主从复制不要用图状结构,用单向链表结构更为稳定,即:Master <- Slave1 <- Slave2 <- Slave3…
这样的结构方便解决单点故障问题,实现Slave对Master的替换。如果Master挂了,可以立刻启用Slave1做Master,其他不变。
redis的一些其他特点:
(1)Redis是单进程单线程的
redis利用队列技术将并发访问变为串行访问,消除了传统数据库串行控制的开销
(2)读写分离模型
通过增加Slave DB的数量,读的性能可以线性增长。为了避免Master DB的单点故障,集群一般都会采用两台Master DB做双机热备,所以整个集群的读和写的可用性都非常高。 读写分离架构的缺陷在于,不管是Master还是Slave,每个节点都必须保存完整的数据,如果在数据量很大的情况下,集群的扩展能力还是受限于单个节点的存储能力,而且对于Write-intensive类型的应用,读写分离架构并不适合。
(3)数据分片模型
为了解决读写分离模型的缺陷,可以将数据分片模型应用进来。
可以将每个节点看成都是独立的master,然后通过业务实现数据分片。
结合上面两种模型,可以将每个master设计成由一个master和多个slave组成的模型。
(4)Redis的回收策略
-
-
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
-
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
-
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
-
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
-
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
-
no-enviction(驱逐):禁止驱逐数据
注意这里的6种机制,volatile和allkeys规定了是对已设置过期时间的数据集淘汰数据还是从全部数据集淘汰数据,后面的lru、ttl以及random是三种不同的淘汰策略,再加上一种no-enviction永不回收的策略。
使用策略规则:
1、如果数据呈现幂律分布,也就是一部分数据访问频率高,一部分数据访问频率低,则使用allkeys-lru
2、如果数据呈现平等分布,也就是所有的数据访问频率都相同,则使用allkeys-random
-
redis 的持久化有哪几种方式?不同的持久化机制都有什么优缺点?持久化机制具体底层是如何实现的?
redis 的持久化有哪几种方式?
- RDB:RDB 持久化机制,是对 redis 中的数据执行周期性的持久化。
- AOF:AOF 机制对每条写入命令作为日志,以 append-only 的模式写入一个日志文件中,在 redis 重启的时候,可以通过回放 AOF 日志中的写入指令来重新构建整个数据集。 通过 RDB 或 AOF,都可以将 redis 内存中的数据给持久化到磁盘上面来,然后可以将这些数据备份到别的地方去,比如说阿里云等云服务。
如果 redis 挂了,服务器上的内存和磁盘上的数据都丢了,可以从云服务上拷贝回来之前的数据,放到指定的目录中,然后重新启动 redis,redis 就会自动根据持久化数据文件中的数据,去恢复内存中的数据,继续对外提供服务。
如果同时使用 RDB 和 AOF 两种持久化机制,那么在 redis 重启的时候,会使用 AOF 来重新构建数据,因为 AOF 中的数据更加完整。
不同的持久化机制都有什么优缺点?
RDB 优缺点
-
RDB 会生成多个数据文件,每个数据文件都代表了某一个时刻中 redis 的数据,这种多个数据文件的方式,非常适合做冷备,可以将这种完整的数据文件发送到一些远程的安全存储上去,比如说 Amazon 的 S3 云服务上去,在国内可以是阿里云的 ODPS 分布式存储上,以预定好的备份策略来定期备份 redis 中的数据。
-
RDB 对 redis 对外提供的读写服务,影响非常小,可以让 redis 保持高性能,因为 redis 主进程只需要 fork 一个子进程,让子进程执行磁盘 IO 操作来进行 RDB 持久化即可。
-
相对于 AOF 持久化机制来说,直接基于 RDB 数据文件来重启和恢复 redis 进程,更加快速。
-
如果想要在 redis 故障时,尽可能少的丢失数据,那么 RDB 没有 AOF 好。一般来说,RDB 数据快照文件,都是每隔 5 分钟,或者更长时间生成一次,这个时候就得接受一旦 redis 进程宕机,那么会丢失最近 5 分钟的数据。
-
RDB 每次在 fork 子进程来执行 RDB 快照数据文件生成的时候,如果数据文件特别大,可能会导致对客户端提供的服务暂停数毫秒,或者甚至数秒。
AOF 优缺点
- AOF 可以更好的保护数据不丢失,一般 AOF 会每隔 1 秒,通过一个后台线程执行一次fsync操作,最多丢失 1 秒钟的数据。
- AOF 日志文件以 append-only 模式写入,所以没有任何磁盘寻址的开销,写入性能非常高,而且文件不容易破损,即使文件尾部破损,也很容易修复。
- AOF 日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写。因为在 rewrite log 的时候,会对其中的指令进行压缩,创建出一份需要恢复数据的最小日志出来。在创建新日志文件的时候,老的日志文件还是照常写入。当新的 merge 后的日志文件 ready 的时候,再交换新老日志文件即可。
- AOF 日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用 flushall 命令清空了所有数据,只要这个时候后台 rewrite 还没有发生,那么就可以立即拷贝 AOF 文件,将最后一条 flushall 命令给删了,然后再将该 AOF 文件放回去,就可以通过恢复机制,自动恢复所有数据。
- 对于同一份数据来说,AOF 日志文件通常比 RDB 数据快照文件更大。
- AOF 开启后,支持的写 QPS 会比 RDB 支持的写 QPS 低,因为 AOF 一般会配置成每秒 fsync 一次日志文件,当然,每秒一次 fsync,性能也还是很高的。(如果实时写入,那么 QPS 会大降,redis 性能会大大降低)
- 以前 AOF 发生过 bug,就是通过 AOF 记录的日志,进行数据恢复的时候,没有恢复一模一样的数据出来。所以说,类似 AOF 这种较为复杂的基于命令日志 / merge / 回放的方式,比基于 RDB 每次持久化一份完整的数据快照文件的方式,更加脆弱一些,容易有 bug。不过 AOF 就是为了避免 rewrite 过程导致的 bug,因此每次 rewrite 并不是基于旧的指令日志进行 merge 的,而是基于当时内存中的数据进行指令的重新构建,这样健壮性会好很多。
RDB 和 AOF 到底该如何选择
- 不要仅仅使用 RDB,因为那样会导致你丢失很多数据;
- 也不要仅仅使用 AOF,因为那样有两个问题:第一,你通过 AOF 做冷备,没有 RDB 做冷备来的恢复速度更快;第二,RDB 每次简单粗暴生成数据快照,更加健壮,可以避免 AOF 这种复杂的备份和恢复机制的 bug;
- redis 支持同时开启开启两种持久化方式,我们可以综合使用 AOF 和 RDB 两种持久化机制,用 AOF 来保证数据不丢失,作为数据恢复的第一选择; 用 RDB 来做不同程度的冷备,在 AOF 文件都丢失或损坏不可用的时候,还可以使用 RDB 来进行快速的数据恢复。
Redis常见性能问题和解决办法
1.Master写内存快照,save命令调度rdbSave函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以Master最好不要写内存快照。
2.Master AOF持久化,如果不重写AOF文件,这个持久化方式对性能的影响是最小的,但是AOF文件会不断增大,AOF文件过大会影响Master重启的恢复速度。
3.Master调用BGREWRITEAOF重写AOF文件,AOF在重写的时候会占大量的CPU和内存资源,导致服务load过高,出现短暂服务暂停现象。
下面是我的一个实际项目的情况,大概情况是这样的:一个Master,4个Slave,没有Sharding机制,仅是读写分离,Master负责写入操作和AOF日志备份,AOF文件大概5G,Slave负责读操作,当Master调用BGREWRITEAOF时,Master和Slave负载会突然陡增,Master的写入请求基本上都不响应了,持续了大概5分钟,Slave的读请求过半也无法及时响应,上面的情况本来不会也不应该发生的,是因为以前Master的这个机器是Slave,在上面有一个shell定时任务在每天的上午10点调用BGREWRITEAOF重写AOF文件,后来由于Master机器down了,就把备份的这个Slave切成Master了,但是这个定时任务忘记删除了,就导致了上面悲剧情况的发生,原因还是找了几天才找到的。
将no-appendfsync-on-rewrite的配置设为yes可以缓解这个问题,设置为yes表示rewrite期间对新写操作不fsync,暂时存在内存中,等rewrite完成后再写入。最好是不开启Master的AOF备份功能。
4.Redis主从复制的性能问题,第一次Slave向Master同步的实现是:Slave向Master发出同步请求,Master先dump出rdb文件,然后将rdb文件全量传输给slave,然后Master把缓存的命令转发给Slave,初次同步完成。第二次以及以后的同步实现是:Master将变量的快照直接实时依次发送给各个Slave。不管什么原因导致Slave和Master断开重连都会重复以上过程。Redis的主从复制是建立在内存快照的持久化基础上,只要有Slave就一定会有内存快照发生。虽然Redis宣称主从复制无阻塞,但由于磁盘io的限制,如果Master快照文件比较大,那么dump会耗费比较长的时间,这个过程中Master可能无法响应请求,也就是说服务会中断,对于关键服务,这个后果也是很可怕的。
以上1.2.3.4根本问题的原因都离不开系统io瓶颈问题,也就是硬盘读写速度不够快,主进程 fsync()/write() 操作被阻塞。
5.单点故障问题,由于目前Redis的主从复制还不够成熟,所以存在明显的单点故障问题,这个目前只能自己做方案解决,如:主动复制,Proxy实现Slave对Master的替换等,这个也是Redis作者目前比较优先的任务之一,作者的解决方案思路简单优雅,详情可见 Redis Sentinel design draft http://redis.io/topics/sentinel-spec。
总结:
1.Master最好不要做任何持久化工作,包括内存快照和AOF日志文件,特别是不要启用内存快照做持久化。
2.如果数据比较关键,某个Slave开启AOF备份数据,策略为每秒同步一次。
3.为了主从复制的速度和连接的稳定性,Slave和Master最好在同一个局域网内。
4.尽量避免在压力较大的主库上增加从库
5.为了Master的稳定性,主从复制不要用图状结构,用单向链表结构更稳定,即主从关系为:Master<–Slave1<–Slave2<–Slave3…….,这样的结构也方便解决单点故障问题,实现Slave对Master的替换,也即,如果Master挂了,可以立马启用Slave1做Master,其他不变。
SpringBoot面试题
1、Spring Boot、Spring MVC 和 Spring 有什么区别?
什么是Spring?它解决了什么问题?
我们说到Spring,一般指代的是Spring Framework,它是一个开源的应用程序框架,提供了一个简易的开发方式,通过这种开发方式,将避免那些可能致使代码变得繁杂混乱的大量的业务/工具对象,说的更通俗一点就是由框架来帮你管理这些对象,包括它的创建,销毁等,比如基于Spring的项目里经常能看到的Bean,它代表的就是由Spring管辖的对象。
什么是Spring MVC?它解决了什么问题?
Spring MVC是Spring的一部分,Spring 出来以后,大家觉得很好用,于是按照这种模式设计了一个 MVC框架(一些用Spring 解耦的组件),主要用于开发WEB应用和网络接口,它是Spring的一个模块,通过Dispatcher Servlet, ModelAndView 和 View Resolver,让应用开发变得很容易
什么是Spring Boot?它解决了什么问题?
初期的Spring通过代码加配置的形式为项目提供了良好的灵活性和扩展性,但随着Spring越来越庞大,其配置文件也越来越繁琐,太多复杂的xml文件也一直是Spring被人诟病的地方,特别是近些年其他简洁的WEB方案层出不穷,如基于Python或Node.Js,几行代码就能实现一个WEB服务器,对比起来,大家渐渐觉得Spring那一套太过繁琐,此时,Spring社区推出了Spring Boot,它的目的在于实现自动配置,降低项目搭建的复杂度
2、什么是自动配置?
Spring Boot:__该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。__Spring Boot采用约定大约配置的方式,大量的减少了配置文件的使用
可以通过查看源码的run方法,通过一个简单的run方法,将引发的是一系列复杂的内部调用和加载过程,从而初始化一个应用所需的配置、环境、资源以及各种自定义的类。在这个阶段,会导入一些列自动配置的类,实现强大的自动配置的功能
我们可以点开@SpringBootApplicaton 注解, 其中,@ComponentScan将扫描和加载一些自定义的类,@EnableAutoConfiguration将导入一些自动配置的类
3、我们说的springboot约定大于配置是什么意思呢?
自动配置在加载一个类的时候,会首先去读取项目当中的配置文件,假如没有,就会启用默认值,这就是springboot约定大于配置原理。以Thymeleaf为例:看下下面我们就知道,为什么我们使用Thymeleaf模板引擎,html文件默认放在resources下面的templates文件夹下面,因为这是Thymeleaf的默认配置。
4、什么是 Spring Boot Stater
starter可以理解成pom配置了一堆jar组合的空maven项目,用来简化maven依赖配置,starter可以继承也可以依赖于别的starter。
如果我要使用redis,我直接引入redis驱动jar包就行了,何必要引入starter包?starter和普通jar包的区别在于,它能够实现自动配置,和Spring Boot无缝衔接,从而节省我们大量开发时间。
5、你能否举一个例子来解释更多 Staters 的内容
比如 我们开发一个web 应用程序或者是公开的 REST 服务的应用程序 Spring Boot Stater Web,是首选,它会加载 :
Spring - core,beans,context,aop
Web MVC - (Spring MVC)
Jackson - for JSON Binding
Validation - Hibernate,Validation API
Enbedded Servlet Container - Tomcat
Logging - logback,slf4j
而且我不用担心这个些依赖项之间的版本兼容性
6、Spring Boot 还提供了其它的哪些 Starter Project Options
Spring Boot 也提供了其它的启动器项目包括,包括用于开发特定类型应用程序的典型依赖项。
spring-boot-starter-web-services - SOAP Web Services
spring-boot-starter-web - Web 和 RESTful 应用程序
spring-boot-starter-test - 单元测试和集成测试
spring-boot-starter-jdbc - 传统的 JDBC
spring-boot-starter-hateoas - 为服务添加 HATEOAS 功能
spring-boot-starter-security - 使用 SpringSecurity 进行身份验证和授权
spring-boot-starter-data-jpa - 带有 Hibeernate 的 Spring Data JPA
spring-boot-starter-data-rest - 使用 Spring Data REST 公布简单的 REST 服务
7、Spring 是如何快速创建产品就绪应用程序的
Spring Boot 致力于快速产品就绪应用程序。为此,它提供了一些譬如高速缓存,日志记录,监控和嵌入式服务器等开箱即用的非功能性特征。
spring-boot-starter-actuator - 使用一些如监控和跟踪应用的高级功能
spring-boot-starter-undertow, spring-boot-starter-jetty, spring-boot-starter-tomcat - 选择您的特定嵌入式 Servlet 容器
spring-boot-starter-logging - 使用 logback 进行日志记录
spring-boot-starter-cache - 启用 Spring Framework 的缓存支持
8、创建一个 Spring Boot Project 的最简单的方法是什么
Spring Initializr是启动 Spring Boot Projects 的一个很好的工具
9、Spring Initializr 是创建 Spring Boot Projects 的唯一方法吗?
Spring Initializr,还有通过maven创建
10、为什么我们需要 spring-boot-maven-plugin?
-
spring-boot-maven-plugin 提供了一些像 jar 一样打包或者运行应用程序的命令。
- spring-boot:run 运行你的 SpringBooty 应用程序。
- spring-boot:repackage 重新打包你的 jar 包或者是 war 包使其可执行
- spring-boot:start 和 spring-boot:stop 管理 Spring Boot 应用程序的生命周期(也可以说是为了集成测试)。
- spring-boot:build-info 生成执行器可以使用的构造信息。
11、如何使用 SpringBoot 自动重装我的应用程序?
把下面的依赖项添加至你的 Spring Boot Project pom.xml 中
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
</dependency>
重启应用程序,然后就可以了。
12、什么是嵌入式服务器?我们为什么要使用嵌入式服务器呢?
思考一下在你的虚拟机上部署应用程序需要些什么。
第一步: 安装 Java
第二部: 安装 Web 或者是应用程序的服务器(Tomat/Wbesphere/Weblogic 等等)
第三部: 部署应用程序 war 包
如果我们想简化这些步骤,应该如何做呢?
让我们来思考如何使服务器成为应用程序的一部分?
你只需要一个安装了 Java 的虚拟机,就可以直接在上面部署应用程序了, 是不是很爽?
这个想法是嵌入式服务器的起源。
当我们创建一个可以部署的应用程序的时候,我们将会把服务器(例如,tomcat)嵌入到可部署的服务器中。
例如,对于一个 Spring Boot 应用程序来说,你可以生成一个包含 Embedded Tomcat 的应用程序 jar。你就可以想运行正常 Java 应用程序一样来运行 web 应用程序了。
嵌入式服务器就是我们的可执行单元包含服务器的二进制文件
13、如何在 Spring Boot 中添加通用的 JS 代码?
在源文件夹下,创建一个名为 static 的文件夹。然后,你可以把你的静态的内容放在这里面。
例如,myapp.js 的路径是 resources\static\js\myapp.js
你可以参考它在 jsp 中的使用方法
14、错误:HAL browser gives me unauthorized error - Full authenticaition is required to access this resource.该如何来修复这个错误呢?
{
"timestamp": 1488656019562,
"status": 401,
"error": "Unauthorized",
"message": "Full authentication is required to access this resource.",
"path": "/beans"
}
两种方法:
方法 1:关闭安全验证
application.properties
management.security.enabled:FALSE
方法二:在日志中搜索密码并传递至请求标头中
15、什么是 Spring Date
Spring Data的使命是为数据访问提供熟悉且一致的基于Spring的编程模型,同时仍保留底层数据存储的特殊特性。
它使数据访问技术,关系数据库和非关系数据库,map-reduce框架和基于云的数据服务变得简单易用。这是一个伞形项目,其中包含许多特定于给定数据库的子项目。这些项目是通过与这些激动人心的技术背后的许多公司和开发人员合作开发的。
主要模块 Spring Data主要使用的一些模块,根据需要选择对应的一些功能模块。
- Spring Data common- 支持每个Spring Data模块的Core Spring概念。
- Spring Data JDBC- 对JDBC的Spring Data存储库支持。
- Spring Data JPA - 对JPA的Spring Data存储库支持。
- Spring Data MongoDB - 对MongoDB的基于Spring对象文档的存储库支持。
- Spring Data Redis - 从Spring应用程序轻松配置和访问Redis。
- Spring Data JDBC Ext- 支持标准JDBC的数据库特定扩展,包括对Oracle RAC快速连接故障转移的支持,AQ JMS支持以及对使用高级数据类型的支持。
- Spring Data KeyValue - Map基于库和SPI轻松建立键值存储一个Spring数据模块。
- Spring Data LDAP - 对Spring LDAP的 Spring Data存储库支持。
- Spring Data REST- 将Spring Data存储库导出为超媒体驱动的RESTful资源。
- Spring Data for Pivotal GemFire - 轻松配置和访问Pivotal GemFire,实现高度一致,低延迟/高吞吐量,面向数据的Spring应用程序。
- Spring Data for Apache Cassandra- 轻松配置和访问Apache Cassandra或大规模,高可用性,面向数据的Spring应用程序。
- Spring Data for Apace Geode- 轻松配置和访问Apache Geode,实现高度一致,低延迟,面向数据的Spring应用程序。
- Spring Data for Apache Solr- 为面向搜索的Spring应用程序轻松配置和访问Apache Solr。
16、什么是 Spring Data REST
Spring Data REST是基于Spring Data的repository之上,可以把 repository 自动 输出为REST资源,目前支持Spring Data JPA、Spring Data MongoDB、Spring Data Neo4j、Spring Data GemFire、Spring Data Cassandra的 repository 自动 转换成REST服务。
17、当 Spring Boot 应用程序作为 Java 应用程序运行时,后台会发生什么?
当你启动 java 应用程序的时候,spring boot 自动配置文件就会魔法般的启用了。
- 当 Spring Boot 应用程序检测到你正在开发一个 web 应用程序的时候,它就会启动 tomcat。
18、我们能否在 spring-boot-starter-web 中用 jetty 代替 tomcat?
在 spring-boot-starter-web 移除现有的依赖项,并把下面这些添加进去。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jetty</artifactId>
</dependency
19、如何使用 Spring Boot 生成一个 WAR 文件?
-
war -
在pom.xml中加入build节点,build节点中的finalName可改成项目名称(包名)
-
在spring-boot-starter-web依赖中移除tomcat模块:
-
新建启动类:主要是SpringApplicationBuilder configure 方法
20、如何使用 Spring Boot 部署到不同的服务器?
- 在一个项目中生成一个 war 文件。
- 将它部署到你最喜欢的服务器(websphere 或者 Weblogic 或者 Tomcat and so on)。
21、RequestMapping 和 GetMapping 的不同之处在哪里?
- RequestMapping 具有类属性的,可以进行 GET,POST,PUT 或者其它的注释中具有的请求方法。
- GetMapping 是 GET 请求方法中的一个特例。它只是 ResquestMapping 的一个延伸,目的是为了提高清晰度
22、为什么我们不建议在实际的应用程序中使用 Spring Data Rest?
我们认为 Spring Data Rest 很适合快速原型制造!在大型应用程序中使用需要谨慎。
通过 Spring Data REST 你可以把你的数据实体作为 RESTful 服务直接发布。
当你设计 RESTful 服务器的时候,最佳实践表明,你的接口应该考虑到两件重要的事情:
- 你的模型范围。
- 你的客户。
- Spring Data Rest 在做复杂数据库查询不适合
通过 With Spring Data REST,你不需要再考虑这两个方面,只需要作为 TEST 服务发布实体。
这就是为什么我们建议使用 Spring Data Rest 在快速原型构造上面,或者作为项目的初始解决方法。对于完整演变项目来说,这并不是一个好的注意。
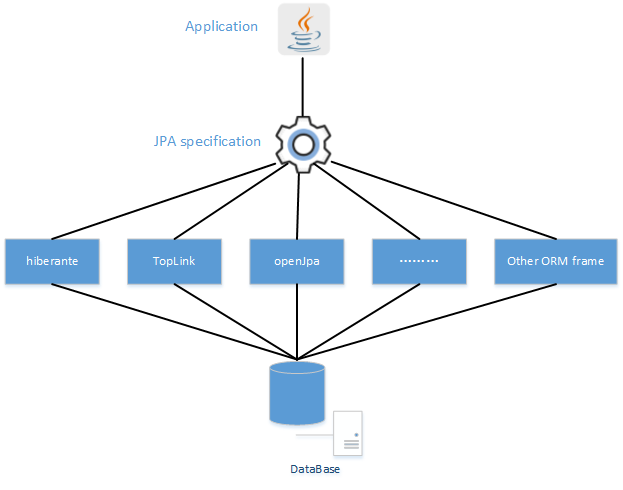
23、JPA 和 Hibernate 有哪些区别?
- JPA 是一个规范或者接口
- Hibernate 是 JPA 的一个实现
24、业务边界应该从哪一层开始?
我们建议在服务层管理业务。商业业务逻辑在商业层或者服务层,与此同时,你想要执行的业务管理也在该层。
25、使用 Spring Boot 启动连接到内存数据库 H2 的 JPA 应用程序需要哪些依赖项?
在 Spring Boot 项目中,当你确保下面的依赖项都在类路里面的时候,你可以加载 H2 控制台。
- web 启动器
- h2
- jpa 数据启动器
26、如何不通过任何配置来选择 Hibernate 作为 JPA 的默认实现?
因为 Spring Boot 是自动配置的。
下面是我们添加的依赖项
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
spring-boot-stater-data-jpa 对于 Hibernate 和 JPA 有过渡依赖性。
当 Spring Boot 在类路径中检测到 Hibernate 中,将会自动配置它为默认的 JPA 实现
27、指定的数据库连接信息在哪里?它是如何知道自动连接至 H2 的?
这就是 Spring Boot 自动配置的魔力。
来自:https://docs.spring.io/spring-boot/docs/current/reference/html/using-boot-auto-configuration.html
Spring Boot auto-configuration 试图自动配置你已经添加的基于 jar 依赖项的 Spring 应用程序。比如说,如果 HSQLDBis 存在你的类路径中,并且,数据库连接 bean 还没有手动配置,那么我们可以自动配置一个内存数据库。
进一步的阅读:
http://www.springboottutorial.com/spring-boot-auto-configuration
28、我们如何连接一个像 MYSQL 或者 orcale 一样的外部数据库?
让我们以 MySQL 为例来思考这个问题:
第一步 - 把 mysql 连接器的依赖项添加至 pom.xml
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
第二步 - 从 pom.xml 中移除 H2 的依赖项
或者至少把它作为测试的范围。
<!--
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>test</scope>
</dependency>
-->
第三步 - 安装你的 MySQL 数据库
更多的来看看这里 -https://github.com/in28minutes/jpa-with-hibernate#installing-and-setting-up-mysql
第四步 - 配置你的 MySQL 数据库连接
配置 application.properties
spring.jpa.hibernate.ddl-auto=none
spring.datasource.url=jdbc:mysql://localhost:3306/todo_example
spring.datasource.username=todouser
spring.datasource.password=YOUR_PASSWORD
第五步 - 重新启动,你就准备好了!
就是这么简单!
29、Spring Boot 配置的默认 H2 数据库的名字是上面?为什么默认的数据库名字是 testdb?
在 application.properties 里面,列出了所有的默认值
- https://docs.spring.io/spring-boot/docs/current/reference/html/common-application-properties.html
找到下面的属性
spring.datasource.name=testdb # Name of the datasource.
如果你使用了 H2 内部存储数据库,它里面确定了 Spring Boot 用来安装你的 H2 数据库的名字。
30、你能否举一个以 ReadOnly 为事务管理的例子?
- 当你从数据库读取内容的时候,你想把事物中的用户描述或者是其它描述设置为只读模式,以便于 Hebernate 不需要再次检查实体的变化。这是非常高效的。
Spring事务管理的两种方式
只读事务(@Transactional(readOnly = true))的一些概念
31、发布 Spring Boot 用户应用程序自定义配置的最好方法是什么?
@Value 的问题在于,您可以通过应用程序分配你配置值。更好的操作是采取集中的方法。 你可以使用 @ConfigurationProperties 定义一个配置组件。
@Component
@ConfigurationProperties("basic")
public class BasicConfiguration {
private boolean value;
private String message;
private int number;
你可以在 application.properties 中配置参数。
basic.value: true
basic.message: Dynamic Message
basic.number: 100
32、配置文件的需求是什么?
企业应用程序的开发是复杂的,你需要混合的环境:
- Dev
- QA
- Stage
- Production
在每个环境中,你想要不同的应用程序配置。
配置文件有助于在不同的环境中进行不同的应用程序配置。
Spring 和 Spring Boot 提供了你可以制定的功能。
- 不同配置文件中,不同环境的配置是什么?
- 为一个制定的环境设置活动的配置文件。
Spring Boot 将会根据特定环境中设置的活动配置文件来选择应用程序的配置
33、如何使用配置文件通过 Spring Boot 配置特定环境的配置?
配置文件不是设别环境的关键。
在下面的例子中,我们将会用到两个配置文件
- dev
- prod
缺省的应用程序配置在 application.properties 中。让我们来看下面的例子:
application.properties
basic.value= true
basic.message= Dynamic Message
basic.number= 100
我们想要为 dev 文件自定义 application.properties 属性。我们需要创建一个名为 application-dev.properties 的文件,并且重写我们想要自定义的属性。
application-dev.properties
basic.message: Dynamic Message in DEV
一旦你特定配置了配置文件,你需要在环境中设定一个活动的配置文件。
有多种方法可以做到这一点:
- 在 VM 参数中使用 Dspring.profiles.active=prod
- 在 application.properties 中使用 spring.profiles.active=prod
SpringBoot打成war包,部署到Tomcat服务器
SpringBoot默认达成jar包,使用SpringBoot构想web应用,默认使用内置的Tomcat。但考虑到项目需要集群部署或者进行优化时,就需要打成war包部署到外部的Tomcat服务器中。
==本文所使用SpringBoot版本为:2.0.3.RELEASE==
一、修改pom.xml文件将默认的jar方式改为war:
<groupId>com.example</groupId>
<artifactId>application</artifactId>
<version>0.0.1-SNAPSHOT</version>
<!--默认为jar方式-->
<!--<packaging>jar</packaging>-->
<!--改为war方式-->
<packaging>war</packaging>
二、排除内置的Tomcat容器(两种方式都可):
1.排除spring-boot-starter-web中的Tomcat
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
</exclusion>
</exclusions>
</dependency>
2.添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
<!--打包的时候可以不用包进去,别的设施会提供。事实上该依赖理论上可以参与编译,测试,运行等周期。
相当于compile,但是打包阶段做了exclude操作-->
<scope>provided</scope>
</dependency>
三、继承org.springframework.boot.web.servlet.support.SpringBootServletInitializer,实现configure方法:
为什么继承该类,SpringBootServletInitializer源码注释:
Note that a WebApplicationInitializer is only needed if you are building a war file and deploying it.
If you prefer to run an embedded web server then you won’t need this at all.
注意,如果您正在构建WAR文件并部署它,则需要WebApplicationInitializer。
如果你喜欢运行一个嵌入式Web服务器,那么你根本不需要这个。
启动类代码:
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
1.方式一,启动类继承SpringBootServletInitializer实现configure:
@SpringBootApplication
public class Application extends SpringBootServletInitializer {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@Override
protected SpringApplicationBuilder configure(SpringApplicationBuilder builder) {
return builder.sources(Application.class);
}
}
2.方式二,新增加一个类继承SpringBootServletInitializer实现configure:
public class ServletInitializer extends SpringBootServletInitializer {
@Override
protected SpringApplicationBuilder configure(SpringApplicationBuilder builder) {
//此处的Application.class为带有@SpringBootApplication注解的启动类
return builder.sources(Application.class);
}
}
注意事项:
使用外部Tomcat部署访问的时候,application.properties(或者application.yml)中配置的
server.port=
server.servlet.context-path=
将失效,请使用tomcat的端口,tomcat,webapps下项目名进行访问。
为了防止应用上下文所导致的项目访问资源加载不到的问题,
建议pom.xml文件中
<build>
<!-- 应与application.properties(或application.yml)中context-path保持一致 -->
<finalName>war包名称</finalName>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
使用mvn命令行打包,运行:
clean是清除之前的包,-Dmaven.test.skip=true是忽略测试代码
jar 方式打包,使用内置Tomcat:mvn clean install -Dmaven.test.skip=true
运行:java -jar 包名.jar
war方式打包,使用外置Tomcat:mvn clean package -Dmaven.test.skip=true
运行:${Tomcat_home}/bin/目录下执行startup.bat(windows)或者startup.sh(linux)
Spring Boot自动配置实现原理
我们在使用Spring Boot构建Java Web项目的时候,实现起来非常的简单,那么SpringBoot是如何做到看似简单,却能够实现我们之前使用SSM或者SSH结合复杂配置实现的功能的呢?
我们在看Spring Boot的介绍的时候,常看到下面一段话:Spring Boot 是由 Pivotal 团队提供的全新框架,其__设计目的是用来简化新 Spring 应用的初始搭建以及开发过程__。该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。Spring Boot采用约定大约配置的方式,大量的减少了配置文件的使用。那么,Spring Boot是如何做到约定大于配置的呢?
首先我们看一下Spring Boot的主程序功能,也就是Spring Boot官方文档里面写的,你可以直接run
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
一个非常简单的run方法的执行,加上@SpringBootApplication的注解,我们看一下run方法的源代码:
public class SpringApplication{
......
public ConfigurableApplicationContext run(String... args) {
//监控任务执行时间
StopWatch stopWatch = new StopWatch();
stopWatch.start();
//创建应用上下文
ConfigurableApplicationContext context = null;
//用来记录关于启动的错误报告
Collection<SpringBootExceptionReporter> exceptionReporters = new ArrayList<>();
configureHeadlessProperty();
//可以监听springboot应用启动过程中的一些生命周期事件
SpringApplicationRunListeners listeners = getRunListeners(args);
listeners.starting();
try {
//程序运行参数
ApplicationArguments applicationArguments = new DefaultApplicationArguments(
args);
//加载相关的配置文件
ConfigurableEnvironment environment = prepareEnvironment(listeners,
applicationArguments);
configureIgnoreBeanInfo(environment);
//打印Banner,也就是springboot启动后最开始打印的图像
Banner printedBanner = printBanner(environment);
//真正的创建应用上下文
context = createApplicationContext();
exceptionReporters = getSpringFactoriesInstances(
SpringBootExceptionReporter.class,
new Class[] { ConfigurableApplicationContext.class }, context);
prepareContext(context, environment, listeners, applicationArguments,
printedBanner);
refreshContext(context);
afterRefresh(context, applicationArguments);
stopWatch.stop();
if (this.logStartupInfo) {
new StartupInfoLogger(this.mainApplicationClass)
.logStarted(getApplicationLog(), stopWatch);
}
listeners.started(context);
callRunners(context, applicationArguments);
}
catch (Throwable ex) {
handleRunFailure(context, ex, exceptionReporters, listeners);
throw new IllegalStateException(ex);
}
try {
listeners.running(context);
}
catch (Throwable ex) {
handleRunFailure(context, ex, exceptionReporters, null);
throw new IllegalStateException(ex);
}
return context;
}
......
}
在上面这段run方法的源代码当中,有一个context = createApplicationContext();方法
protected ConfigurableApplicationContext createApplicationContext() {
Class<?> contextClass = this.applicationContextClass;
if (contextClass == null) {
try {
switch (this.webApplicationType) {
case SERVLET:
//假如是servlet应用,默认加载DEFAULT_WEB_CONTEXT_CLASS
contextClass = Class.forName(DEFAULT_WEB_CONTEXT_CLASS);
break;
case REACTIVE:
contextClass = Class.forName(DEFAULT_REACTIVE_WEB_CONTEXT_CLASS);
break;
default:
contextClass = Class.forName(DEFAULT_CONTEXT_CLASS);
}
}
catch (ClassNotFoundException ex) {
throw new IllegalStateException(
"Unable create a default ApplicationContext, "
+ "please specify an ApplicationContextClass",
ex);
}
}
return (ConfigurableApplicationContext) BeanUtils.instantiateClass(contextClass);
}
也就是说,通过一个简单的run方法,将引发的是一系列复杂的内部调用和加载过程,从而初始化一个应用所需的配置、环境、资源以及各种自定义的类。在这个阶段,会导入一些列自动配置的类,实现强大的自动配置的功能。那么自动配置类是从哪里来的呢?这就需要@SpringBootApplicaton起到作用了。
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan(excludeFilters = {
@Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class),
@Filter(type = FilterType.CUSTOM, classes = AutoConfigurationExcludeFilter.class) })
public @interface SpringBootApplication {
......
}
其中,@ComponentScan将扫描和加载一些自定义的类,@EnableAutoConfiguration将导入一些自动配置的类。这些自动配置的类很多,并且他们都处于org.springframework.boot.autoconfigure这个包下面。这些配置类都会被导入并处于备用状态。假如你在maven文件当中引入了相关的包的时候,相关功能将被启用。
那么,我们说的springboot约定大于配置是什么意思呢?自动配置在加载一个类的时候,会首先去读取项目当中的配置文件,假如没有,就会启用默认值,这就是springboot约定大于配置原理。以Thymeleaf为例:看下下面我们就知道,为什么我们使用Thymeleaf模板引擎,html文件默认放在resources下面的templates文件夹下面,因为这是Thymeleaf的默认配置。
@ConfigurationProperties(prefix = “spring.thymeleaf”) public class ThymeleafProperties {
@ConfigurationProperties(prefix = "spring.thymeleaf")
public class ThymeleafProperties {
private static final Charset DEFAULT_ENCODING = StandardCharsets.UTF_8;
public static final String DEFAULT_PREFIX = "classpath:/templates/";
public static final String DEFAULT_SUFFIX = ".html";
private boolean checkTemplate = true;
private boolean checkTemplateLocation = true;
private String prefix = DEFAULT_PREFIX;
private String suffix = DEFAULT_SUFFIX;
private String mode = "HTML";
private Charset encoding = DEFAULT_ENCODING;
private boolean cache = true;
......
}
} 并且这些约定的配置一般都以Properties为结尾,比如
org.springframework.boot.autoconfigure.jdbc.DataSourceProperties(数据库连接配置)
org.springframework.boot.autoconfigure.data.redis.RedisProperties(Redis连接配置)
org.springframework.boot.autoconfigure.amqp.RabbitProperties(RabbitMQ连接配置)
org.springframework.boot.autoconfigure.web.ResourceProperties(Web资源配置)
org.springframework.boot.autoconfigure.kafka.KafkaProperties(Kafka连接配置)
org.springframework.boot.autoconfigure.cache.CacheProperties(缓存配置)
那么,我们知道程序会自动装配加载很多类,但是我们假如不想程序去加载某些类(毕竟加载需要耗时),我们如何去自定义我们想加载的配置类呢?
我们只需要把@SpringBootApplication注解去掉,换成@Congfiguation注解,并通过@Import注解去指定需要加载的配置类就可以了(非常不建议这么做,因为我们可能不是特别了解所有自动加载的类的特性)。
@Configuration
@Import({
DispatcherServletAutoConfiguration.class,
HttpEncodingAutoConfiguration.class,
ThymeleafAutoConfiguration.class,
WebMvcAutoConfiguration.class,
WebSocketServletAutoConfiguration.class,
MultipartAutoConfiguration.class
//继续加载你需要的配置
})
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
339 post articles, 43 pages.