redis面试题
1、什么是 Redis?.
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API
2、Redis 的数据类型?
string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)
3、使用 Redis 有哪些好处?
(1) 速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
(2) 支持丰富数据类型,支持string,list,set,sorted set,hash
(3) 支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
(4) 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
4、Redis 相比 Memcached 有哪些优势?
(1) memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型
(2) redis的速度__比memcached快很多__
(3) redis可以__持久化其数据__
5、Memcache 与 Redis 的区别都有哪些?
1)、存储方式 Memecache把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。 Redis有部份存在硬盘上,这样能保证数据的持久性。 2)、数据支持类型 Memcache对数据类型支持相对简单。 Redis有复杂的数据类型。 3)、使用底层模型不同 它们之间底层实现方式 以及与客户端之间通信的应用协议不一样。 Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。 4),value大小 redis最大可以达到1GB,而memcache只有1MB
6、Redis 是单进程单线程的?
-
redis 的瓶颈不在cpu 在内存
- 多线程处理可能涉及到锁
-
多线程处理会涉及到线程切换而消耗CPU
- 无法发挥多核CPU性能,不过可以通过在单机开多个Redis实例来完善
7、一个字符串类型的值能存储最大容量是多少?
string 类型是 Redis 最基本的数据类型,string 类型的值最大能存储 512MB
8、Redis 的持久化机制是什么?各自的优缺点?
- RDB:RDB 持久化机制,是对 redis 中的数据执行周期性的持久化。
-
AOF:AOF 机制对每条写入命令作为日志,以
append-only的模式写入一个日志文件中,在 redis 重启的时候,可以通过回放 AOF 日志中的写入指令来重新构建整个数据集 - 不要仅仅使用 RDB,因为那样会导致你丢失很多数据;
- 也不要仅仅使用 AOF,因为那样有两个问题:第一,你通过 AOF 做冷备,没有 RDB 做冷备来的恢复速度更快;第二,RDB 每次简单粗暴生成数据快照,更加健壮,可以避免 AOF 这种复杂的备份和恢复机制的 bug;
- redis 支持同时开启开启两种持久化方式,我们可以综合使用 AOF 和 RDB 两种持久化机制,用 AOF 来保证数据不丢失,作为数据恢复的第一选择; 用 RDB 来做不同程度的冷备,在 AOF 文件都丢失或损坏不可用的时候,还可以使用 RDB 来进行快速的数据恢复。 优缺点详细
9、Redis 常见性能问题和解决方案:
(1) Master最好不要做任何持久化工作,如RDB内存快照和AOF日志文件
(2) 如果数据比较重要,某个Slave开启AOF备份数据,策略设置为每秒同步一次
(3) 为了主从复制的速度和连接的稳定性,Master和Slave最好在同一个局域网内
(4) 尽量避免在压力很大的主库上增加从库
(5) 主从复制不要用图状结构,用单向链表结构更为稳定,即:Master <- Slave1 <- Slave2 <- Slave3…
这样的结构方便解决单点故障问题,实现Slave对Master的替换。如果Master挂了,可以立刻启用Slave1做Master,其他不变
10、redis 过期键的删除策略?
一,过期删除策略
redis数据库键的过期时间都保存在过期字典中,根据系统时间和存活时间判断是否过期。
redis有三种不同的删除策略:
1,定时删除:实现方式,创建定时器
2,惰性删除:每次获取键时,检查是否过期
3,定期删除:每隔一段时间,对数据库进行一次检查,删除过期键,由算法决定删除多少过期键和检查多少数据库
二,优缺点
1,定时删除,对内存友好,但是对cpu很不友好
2,惰性删除,对cpu友好,对内存很不友好
3,定期删除,是两种折中,但是,如果删除太频繁,将退化为定时删除,如果删除次数太少,将退化为惰性删除。
11、Redis 的回收策略(淘汰策略)?
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-enviction(驱逐):禁止驱逐数据
注意这里的 6 种机制,volatile 和 allkeys 规定了是对已设置过期时间的数据集淘汰数据还是从全部数据集淘汰数据,后面的 lru、ttl 以及 random 是三种不同的淘汰策略,再加上一种 no-enviction 永不回收的策略。
使用策略规则:
(1)如果数据呈现幂律分布,也就是一部分数据访问频率高,一部分数据访问频率低,则使用 allkeys-lru
(2)如果数据呈现平等分布,也就是所有的数据访问频率都相同,则使用allkeys-random
12、为什么 Redis 需要把所有数据放到内存中?
Redis 为了达到最快的读写速度将数据都读到内存中,并通过异步的方式将数据写入磁盘。所以 redis 具有快速和数据持久化的特征。如果不将数据放在内存中,磁盘 I/O 速度为严重影响 redis 的性能。在内存越来越便宜的今天,redis 将会越来越受欢迎。如果设置了最大使用的内存,则数据已有记录数达到内存限值后不能继续插入新值
13、Redis 的同步机制了解么?
Redis 可以使用__主从同步,从从同步__。第一次同步时,主节点做一次 bgsave,并同时将后续修改操作记录到内存 buffer,待完成后将 rdb 文件全量同步到复制节点,复制节点接受完成后将 rdb 镜像加载到内存。加载完成后,再通知主节点将期间修改的操作记录同步到复制节点进行重放就完成了同步过程。
14、Pipeline 有什么好处,为什么要用 pipeline?
多个指令之间没有依赖关系,可以使用 pipeline 一次性执行多个指令,减少 IO,缩减时间
15、是否使用过 Redis 集群,集群的原理是什么?
(1)Redis Sentinal 着眼于高可用,在 master 宕机时会自动将 slave 提升为master,继续提供服务。
(2)Redis Cluster 着眼于扩展性,在单个 redis 内存不足时,使用 Cluster 进行分片存储。
16、Redis 集群方案什么情况下会导致整个集群不可用?
有 A,B,C 三个节点的集群,在没有复制模型的情况下,如果节点 B 失败了,那么整个集群就会以为缺少 5501-11000 这个范围的槽而不可用。
17、Redis 支持的 Java 客户端都有哪些?官方推荐用哪个?
Redisson、Jedis、lettuce 等等,官方推荐使用 Redisson
18、Jedis 与 Redisson 对比有什么优缺点?
Jedis 是 Redis 的 Java 实现的客户端,其 API 提供了比较全面的 Redis 命令的支持;Redisson 实现了分布式和可扩展的 Java 数据结构,和 Jedis 相比,功能较为简单,不支持字符串操作,不支持排序、事务、管道、分区等 Redis 特性。
Redisson 的宗旨是促进使用者对 Redis 的关注分离,从而让使用者能够将精力更集中地放在处理业务逻辑上。
19、Redis 如何设置密码及验证密码?
设置密码:config set requirepass 123456
授权密码:auth 123456
20、说说 Redis 哈希槽的概念?
Redis 集群没有使用一致性 hash,而是引入了哈希槽的概念,Redis 集群有16384 个哈希槽,每个 key 通过 CRC16 校验后对 16384 取模来决定放置哪个槽,集群的每个节点负责一部分 hash 槽。
21、Redis 集群的主从复制模型是怎样的?
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有 N-1 个复制品.
22、Redis 集群会有写操作丢失吗?为什么?
Redis 并不能保证数据的强一致性,这意味这在实际中集群在特定的条件下可能会丢失写操作
23、Redis 集群之间是如何复制的?
异步复制
24、Redis 集群最大节点个数是多少?
16384 个。
25、Redis 集群如何选择数据库?
Redis 集群目前无法做数据库选择,默认在 0 数据库。
26、怎么测试 Redis 的连通性?
使用 ping 命令。
27、怎么理解 Redis 事务?
(1)事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
(2)事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
28、Redis 事务相关的命令有哪几个?
MULTI、EXEC、DISCARD、WATCH
29、Redis key 的过期时间和永久有效分别怎么设置?
EXPIRE 和 PERSIST 命令
30、Redis 如何做内存优化?
尽可能使用散列表(hashes),散列表(是说散列表里面存储的数少)使用的内存非常小,所以你__应该尽可能的将你的数据模型抽象到一个散列表里面__。比如你的 web 系统中有一个用户对象,不要为这个用户的名称,姓氏,邮箱,密码设置单独的 key,而是应该把这个用户的所有信息存储到一张散列表里面。
31、Redis 回收进程如何工作的?
一个客户端运行了新的命令,添加了新的数据。Redis 检查内存使用情况,如果大于 maxmemory 的限制, 则根据设定好的策略进行回收。一个新的命令被执行,等等。所以我们不断地穿越内存限制的边界,通过不断达到边界然后不断地回收回到边界以下。如果一个命令的结果导致大量内存被使用(例如很大的集合的交集保存到一个新的键),不用多久内存限制就会被这个内存使用量超越。
32、都有哪些办法可以降低 Redis 的内存使用情况呢?
如果你使用的是 32 位的 Redis 实例,可以好好利用 Hash,list,sorted set,set等集合类型数据,因为通常情况下很多小的 Key-Value 可以用更紧凑的方式存放到一起。
33、Redis 的内存用完了会发生什么?
如果达到设置的上限,__Redis 的写命令会返回错误信息(但是读命令还可以正常返回。)__或者你可以将 Redis 当缓存来使用配置淘汰机制,当 Redis 达到内存上限时会冲刷掉旧的内容。
34、一个 Redis 实例最多能存放多少的 keys?List、Set、Sorted Set他们最多能存放多少元素?
理论上 Redis 可以处理多达 $2^(32)$ 的 keys,并且在实际中进行了测试,每个实例至少存放了 2 亿 5 千万的 keys。我们正在测试一些较大的值。任何 list、set、和 sorted set 都可以放 $2^(32)$ 个元素。换句话说,Redis 的存储极限是系统中的可用内存值。
35、MySQL 里有 2000w 数据,redis 中只存 20w 的数据,如何保证redis 中的数据都是热点数据?
当redis使用的内存超过了设置的最大内存时,会触发redis的key淘汰机制,在redis 3.0中有6种淘汰策略:
- noeviction: 不删除策略。当达到最大内存限制时, 如果需要使用更多内存,则直接返回错误信息。(redis默认淘汰策略)
- allkeys-lru: 在所有key中优先删除最近最少使用(less recently used ,LRU) 的 key。
- allkeys-random: 在所有key中随机删除一部分 key。
- volatile-lru: 在设置了超时时间(expire )的key中优先删除最近最少使用(less recently used ,LRU) 的 key。
- volatile-random: 在设置了超时时间(expire)的key中随机删除一部分 key。
- volatile-ttl: 在设置了超时时间(expire )的key中优先删除剩余时间(time to live,TTL) 短的key。 场景:
数据库中有1000w的数据,而redis中只有50w数据,如何保证redis中10w数据都是热点数据?
方案:
限定 Redis 占用的内存,Redis 会根据自身数据淘汰策略,留下热数据到内存。所以,计算一下 50W 数据大约占用的内存,然后设置一下 Redis 内存限制即可,并将淘汰策略为volatile-lru或者allkeys-lru。
设置Redis最大占用内存:
打开redis配置文件,设置maxmemory参数,maxmemory是bytes字节类型
# In short... if you have slaves attached it is suggested that you set a lower
# limit for maxmemory so that there is some free RAM on the system for slave
# output buffers (but this is not needed if the policy is 'noeviction').
#
# maxmemory <bytes>
maxmemory 268435456
设置过期策略:
maxmemory-policy volatile-lru
36、Redis 最适合的场景?
Redis最适合所有数据in-momory的场景,虽然Redis也提供持久化功能,但实际更多的是一个disk-backed的功能,跟传统意义上的持久化有比较大的差别,那么可能大家就会有疑问,似乎Redis更像一个加强版的Memcached,那么何时使用Memcached,何时使用Redis呢?
如果简单地比较Redis与Memcached的区别,大多数都会得到以下观点:
1 、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
2 、Redis支持数据的备份,即master-slave模式的数据备份。
3 、Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
(1)、会话缓存(Session Cache)
最常用的一种使用Redis的情景是会话缓存(session cache)。用Redis缓存会话比其他存储(如Memcached)的优势在于:Redis提供持久化。当维护一个不是严格要求一致性的缓存时,如果用户的购物车信息全部丢失,大部分人都会不高兴的,现在,他们还会这样吗?
幸运的是,随着 Redis 这些年的改进,很容易找到怎么恰当的使用Redis来缓存会话的文档。甚至广为人知的商业平台Magento也提供Redis的插件。
(2)、全页缓存(FPC)
除基本的会话token之外,Redis还提供很简便的FPC平台。回到一致性问题,即使重启了Redis实例,因为有磁盘的持久化,用户也不会看到页面加载速度的下降,这是一个极大改进,类似PHP本地FPC。
再次以Magento为例,Magento提供一个插件来使用Redis作为全页缓存后端。
此外,对WordPress的用户来说,Pantheon有一个非常好的插件 wp-redis,这个插件能帮助你以最快速度加载你曾浏览过的页面。
(3)、队列
Reids在内存存储引擎领域的一大优点是提供 list 和 set 操作,这使得Redis能作为一个很好的消息队列平台来使用。Redis作为队列使用的操作,就类似于本地程序语言(如Python)对 list 的 push/pop 操作。
(4),排行榜/计数器
Redis在内存中对数字进行递增或递减的操作实现的非常好。集合(Set)和有序集合(Sorted Set)也使得我们在执行这些操作的时候变的非常简单,Redis只是正好提供了这两种数据结构。所以,我们要从排序集合中获取到排名最靠前的10个用户–我们称之为“user_scores”,我们只需要像下面一样执行即可:
当然,这是假定你是根据你用户的分数做递增的排序。如果你想返回用户及用户的分数,你需要这样执行:
ZRANGE user_scores 0 10 WITHSCORES
Agora Games就是一个很好的例子,用Ruby实现的,它的排行榜就是使用Redis来存储数据的
37、假如 Redis 里面有 1 亿个 key,其中有 10w 个 key 是以某个固定的已知的前缀开头的,如何将它们全部找出来?
使用 keys 指令可以扫出指定模式的 key 列表。
对方接着追问:如果这个 redis 正在给线上的业务提供服务,那使用 keys 指令会有什么问题?
这个时候你要回答 redis 关键的一个特性:redis 的单线程的。keys 指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用 scan 指令,scan 指令可以无阻塞的提取出指定模式的 key 列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用 keys 指令长。
38、如果有大量的 key 需要设置同一时间过期,一般需要注意什么?
如果大量的 key 过期时间设置的过于集中,到过期的那个时间点,redis 可能会出现短暂的卡顿现象。一般需要在时间上加一个随机值,使得过期时间分散一些。
39、使用过 Redis 做异步队列么,你是怎么用的?
答:一般使用 list 结构作为队列,rpush 生产消息,lpop 消费消息。当 lpop 没有消息的时候,要适当 sleep 一会再重试。如果对方追问可不可以不用 sleep 呢?list 还有个指令叫 blpop,在没有消息的时候,它会阻塞住直到消息到来。如果对方追问能不能生产一次消费多次呢?使用 pub/sub 主题订阅者模式,可以实现1:N 的消息队列。
如果对方追问 pub/sub 有什么缺点?
在消费者下线的情况下,生产的消息会丢失,得使用专业的消息队列如 RabbitMQ等。
如果对方追问 redis 如何实现延时队列?
我估计现在你很想把面试官一棒打死如果你手上有一根棒球棍的话,怎么问的这么详细。但是你很克制,然后神态自若的回答道:使用 sortedset,拿时间戳作为score,消息内容作为 key 调用 zadd 来生产消息,消费者用 zrangebyscore 指令获取 N 秒之前的数据轮询进行处理。到这里,面试官暗地里已经对你竖起了大拇指。但是他不知道的是此刻你却竖起了中指,在椅子背后。
40、使用过 Redis 分布式锁么,它是什么回事?
先拿 setnx 来争抢锁,抢到之后,再用 expire 给锁加一个过期时间防止锁忘记了释放。
这时候对方会告诉你说你回答得不错,然后接着问如果在 setnx 之后执行 expire之前进程意外 crash 或者要重启维护了,那会怎么样?这时候你要给予惊讶的反馈:唉,是喔,这个锁就永远得不到释放了。紧接着你需要抓一抓自己得脑袋,故作思考片刻,好像接下来的结果是你主动思考出来的,然后回答:我记得 set 指令有非常复杂的参数,这个应该是可以同时把 setnx 和expire 合成一条指令来用的!对方这时会显露笑容,心里开始默念:摁,这小子还不错。
jvm面试题
1、JVM三大性能调优参数,JVM 几个重要的参数
2、JVM调优
3、JVM内存管理,JVM的常见的垃圾收集器,G1垃圾收集器。GC调优,Minor GC ,Full GC 触发条件
4、java内存模型
5、Java垃圾回收机制
6、jvm怎样 判断一个对象是否可回收,怎样的对象才能作为GC root
7、OOM说一下?怎么排查?哪些会导致OOM? OOM出现在什么时候
8、什么是Full GC?GC? major GC? stop the world
9、描述JVM中一次full gc过程。
10、JVM中类加载机制,类加载过程,什么是双亲委派模型?,类加载器有哪些
11、如何判断是否有内存泄露?定位 Full GC 发生的原因,有哪些方式?
12、Java 中都有哪些引用类型?
13、堆,栈,方法区分别保存哪些信息?
堆:存对象、数组、非静态变量
方法区:静态变量(static)、常量(final)、所有方法(包括静态和非静态)
栈:对象引用,方法参数,基本类型变量区、执行环境上下文、操作指令区(存放操作指令)。
活锁例子
我们都知道死锁,然而还存在一种锁叫做活锁。死锁是一直死等,活锁他不死等,它会一直执行,但是线程就是不能继续,因为它不断重试相同的操作。换句话说,就是信息处理线程并没有发生阻塞,但是永远都不会前进了。
活锁同样会发生在多个相互协作的线程间,当他们为了彼此间的响应而相互礼让,使得没有一个线程能够继续前进,那么就发生了活锁。
好比两个过于礼貌的人在半路相遇,出于礼貌他们相互礼让,避开对方的路,但是在另一条路上又相遇了。就这样,不停地一直避让下去。。。。
活锁典型的例子实在一些重试机制中,比如以太网络上,两个基站尝试使用相同的载波发送数据包,包会发生冲突。发生冲突后,稍后都会重发。如果这时他们都是在 1s 后重发,那么他们又会再次发生冲突,一直循环下去,导致数据包永远不能发送。为了解决这个问题,我们可以对重试机制引入一些随机性,不指定 1s 重发,而是重发的时间内是随机的。通过随机的等待再发送能够相当有效的避免活锁的发生。
下面看一个活锁例子:
/************************
* 活锁例子
* 创建一个勺子类,有且只有一个。
* 丈夫和妻子用餐时,需要使用勺子,这时只能有一人持有,也就是说同一时刻只有一个人能够进餐。
* 但是丈夫和妻子互相谦让,都想让对方先吃,所以勺子一直传递来传递去,谁都没法用餐。
* */
public class LiveLockTest {
//定义一个勺子,ower 表示这个勺子的拥有者
static class Spoon {
Diner owner;//勺子的拥有者
//获取拥有者
public String getOwnerName() {
return owner.getName();
}
//设置拥有者
public void setOwner(Diner diner) {
this.owner = diner;
}
public Spoon(Diner diner) {
this.owner = diner;
}
//表示正在用餐
public void use() {
System.out.println(owner.getName() + " use this spoon and finish eat.");
}
}
//定义一个晚餐类
static class Diner {
public Diner(boolean isHungry, String name) {
this.isHungry = isHungry;
this.name = name;
}
private boolean isHungry;//是否饿了
private String name;//定义当前用餐者的名字
public String getName() {//获取当前用餐者
return name;
}
//可以理解为和某人吃饭
public void eatWith(Diner spouse, Spoon sharedSpoon) {
try {
synchronized (sharedSpoon) {
while (isHungry) {
//当前用餐者和勺子拥有者不是同一个人,则进行等待
while (!sharedSpoon.getOwnerName().equals(name)) {
sharedSpoon.wait();
//System.out.println("sharedSpoon belongs to" + sharedSpoon.getOwnerName())
}
//spouse此时是饿了,把勺子分给他,并通知他可以用餐
if (spouse.isHungry) {
System.out.println("I am " + name + ", and my " + spouse.getName() + " is hungry, I should give it to him(her).\n");
sharedSpoon.setOwner(spouse);
sharedSpoon.notifyAll();
} else {
//用餐
sharedSpoon.use();
sharedSpoon.setOwner(spouse);
isHungry = false;
}
Thread.sleep(500);
}
}
} catch (InterruptedException e) {
System.out.println(name + " is interrupted.");
}
}
}
public static void main(String[] args) {
final Diner husband = new Diner(true, "husband");//创建一个丈夫用餐类
final Diner wife = new Diner(true, "wife");//创建一个妻子用餐类
final Spoon sharedSpoon = new Spoon(wife);//创建一个勺子,初始状态并由妻子持有
//创建一个 线程,由丈夫进行用餐
Thread h = new Thread() {
@Override
public void run() {
//表示和妻子用餐,这个过程判断妻子是否饿了,如果是,则会把勺子分给妻子,并通知她
husband.eatWith(wife, sharedSpoon);
}
};
h.start();
//创建一个 线程,由妻子进行用餐
Thread w = new Thread() {
@Override
public void run() {
//表示和妻子用餐,这个过程判断丈夫是否饿了,如果是,则会把勺子分给丈夫,并通知他
wife.eatWith(husband, sharedSpoon);
}
};
w.start();
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
h.interrupt();
w.interrupt();
try {
h.join();//join()方法阻塞调用此方法的线程(calling thread),直到线程t完成,此线程再继续;通常用于在main()主线程内,等待其它线程完成再结束main()主线程。
w.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
输出结果:
I am wife, and my husband is hungry, I should give it to him(her).
I am husband, and my wife is hungry, I should give it to him(her).
I am wife, and my husband is hungry, I should give it to him(her).
I am husband, and my wife is hungry, I should give it to him(her).
I am wife, and my husband is hungry, I should give it to him(her).
I am husband, and my wife is hungry, I should give it to him(her).
I am wife, and my husband is hungry, I should give it to him(her).
I am husband, and my wife is hungry, I should give it to him(her).
I am wife, and my husband is hungry, I should give it to him(her).
I am husband, and my wife is hungry, I should give it to him(her).
I am wife, and my husband is hungry, I should give it to him(her).
I am husband, and my wife is hungry, I should give it to him(her).
并发面试题
1、在 java 中守护线程和本地线程区别?
- 守护线程:任何线程可通过Thread.setDaemon(bool on) 设置为守护线程 ,GC是守护线程
- 本地线程:也是普通线程,
2、线程与进程的区别?
- 一个程序至少有一个进程,一个进程至少有一个线程
- 线程的划分尺度小于进程,使得多线程程序的并发性高
- 进程在执行的过程中有独立的内存单元,而多线程共享内存,从而极大的提高了程序的效率
- 线程依托于应用程序,由应用程序提高多线程的执行控制
-
从逻辑角度来看,多线程的意义在于一个应用程序中,有多个执行部分可以同时执行。但操作系统并没有将多个线程看做多个独立的应用,来实现进程的调度和管理以及资源分配。这就是进程和线程的重要区别。
- 现在有自己的堆栈和局部变量,进程之间有单独的地址空间
- 进程是操作系统分配资源的最小单元,线程是操作系统调度的最小单元。
3、什么是多线程中的上下文切换?
多线程编程中一般线程的个数都大于 CPU 核心的个数,而一个 CPU 核心在任意时刻只能被一个线程使用,为了让这些线程都能得到有效执行,CPU 采取的策略是为每个线程分配时间片并轮转的形式。当一个线程的时间片用完的时候就会重新处于就绪状态让给其他线程使用,这个过程就属于一次上下文切换。
概括来说就是:当前任务在执行完 CPU 时间片切换到另一个任务之前会先保存自己的状态,以便下次再切换回这个任务时,可以再加载这个任务的状态。任务从保存到再加载的过程就是一次上下文切换。
上下文切换通常是计算密集型的。也就是说,它需要相当可观的处理器时间,在每秒几十上百次的切换中,每次切换都需要纳秒量级的时间。所以,上下文切换对系统来说意味着消耗大量的 CPU 时间,事实上,可能是操作系统中时间消耗最大的操作
4、死锁与活锁的区别,死锁与饥饿的区别?
1.死锁:通俗地说,死锁是两个或者多个线程,相互占用对方需要的资源,而都不进行释放,导致彼此之间都相互等待对方释放资源,产生了无限制等待的现象,死锁一旦发生,如果没有外力介入,这种等待将永远存在,从而对程序产生严重的影响
产生死锁的必要条件:
- 互斥条件:所谓互斥就是进程在某一时间内独占资源。
- 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:进程已获得资源,在末使用完之前,不能强行剥夺。
- 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系
降低死锁的方法:
- 尽可能减小锁的作用范围,比如使用同步代码块而不使用同步方法
- 尽量不编写在通时刻获取多个锁的代码,因为在一个线程持有多个资源的时候很容易发生死锁
- 根据情况将过大范围的锁进行切分,让每个锁的作用范围减小,从而降低死锁发生的概率。这以原则的典型应用是ConcurrentHashMap的锁分段技术,具体可以参看这篇文章。
2.饥饿: 指的线程无法访问到它需要的资源而不能继续执行时,引发饥饿最常见资源就是CPU时钟周期。虽然在Thread API中由指定线程优先级的机制,但是只能作为操作系统进行线程调度的一个参考,换句话说就是操作系统在进行线程调度是平台无关的,会尽可能提供公平的、活跃性良好的调度,那么即使在程序中指定了线程的优先级,也有可能在操作系统进行调度的时候映射到了同一个优先级。
产生饥饿的可能情况:
- 引发饥饿最常见资源就是CPU时钟周期
- 不要区修改线程的优先级,一旦修改程序的行为就会与平台相关,并且会导致饥饿问题的产生
- 线程被永久堵塞在一个等待进入同步块的状态,因为其他线程总是能在它之前持续地对该同步块进行访问。
- 线程在等待一个本身也处于永久等待完成的对象(比如调用这个对象的wait方法),因为其他线程总是被持续地获得唤醒。
解决饥饿的方法:
- 在程序中使用的Thread.yield或者Thread.sleep表明该程序试图客服优先级调整问题,让优先级更低的线程拥有被CPU调度的机会。
3.活锁 指的是线程不断重复执行相同的操作,但每次操作的结果都是失败的。尽管这个问题不会阻塞线程,但是程序也无法继续执行。活锁通常发生在处理事务消息的应用程序中,如果不能成功处理这个事务那么事务将回滚整个操作。解决活锁的办法是在每次重复执行的时候引入随机机制,这样由于出现的可能性不同使得程序可以继续执行其他的任务。
5、Java 中用到的线程调度算法是什么?
抢占式。一个线程用完CPU之后,操作系统会根据线程优先级、线程饥饿情况等数据算出一个总的优先级并分配下一个时间片给某个线程执行。
操作系统中可能会出现某条线程常常获取到VPU控制权的情况,为了让某些优先级比较低的线程也能获取到CPU控制权,可以使用Thread.sleep(0)手动触发一次操作系统分配时间片的操作,这也是平衡CPU控制权的一种操作。
6、什么是线程组,为什么在 Java 中不推荐使用?
- 1.线程组ThreadGroup对象中比较有用的方法是stop、resume、suspend等方法,由于这几个方法会导致线程的安全问题(主要是死锁问题),已经被官方废弃掉了,所以线程组本身的应用价值就大打折扣了。
- 2.线程组ThreadGroup不是线程安全的,这在使用过程中获取的信息并不全是及时有效的,这就降低了它的统计使用价值。
虽然线程组现在已经不被推荐使用了,但是它在线程的异常处理方面还是做出了一定的贡献。当线程运行过程中出现异常情况时,在某些情况下JVM会把线程的控制权交到线程关联的线程组对象上来进行处理。所以对线程组的了解还是有一定必要的。
7、为什么使用 Executor 框架?(其实问的是线程池)
- 每次执行任务创建线程 new Thread()比较消耗性能,创建一个线程是比较耗时、耗资源的。
- 调用 new Thread()创建的线程缺乏管理,被称为野线程,而且可以无限制的创建,线程之间的相互竞争会导致过多占用系统资源而导致系统瘫痪,还有线程之间的频繁交替也会消耗很多系统资源。
- 接使用new Thread() 启动的线程不利于扩展,比如定时执行、定期执行、定时定期执行、线程中断等都不便实现。
8、在 Java 中 Executor 和 Executors 的区别?
- Executors 工具类的不同方法按照我们的需求创建了不同的线程池,来满足业务的需求。
- Executor 接口对象能执行我们的线程任务。
- ExecutorService接口继承了Executor接口并进行了扩展,提供了更多的方法我们能获得任务执行的状态并且可以获取任务的返回值。
- 使用ThreadPoolExecutor 可以创建自定义线程池。
- Future 表示异步计算的结果,他提供了检查计算是否完成的方法,以等待计算的完成,并可以使用get()方法获取计算的结果。Future 可异步执行任务,但是Future.get() 方法是阻塞的
9、如何在 Windows 和 Linux 上查找哪个线程使用的 CPU 时间最长?
(1)获取项目的pid,jps或者ps -ef | grep java
(2)top -H -p pid,顺序不能改变
10、什么是原子操作?在 Java Concurrency API 中有哪些原子类(atomic classes)?
原子操作(atomic operation)意为”不可被中断的一个或一系列操作” 。 处理器使用基于对缓存加锁或总线加锁的方式来实现多处理器之间的原子操作。 在Java中可以通过锁和循环CAS的方式来实现原子操作。 CAS操作——Compare & Set,或是 Compare & Swap,现在几乎所有的CPU指令都支持CAS的原子操作。
原子操作是指一个不受其他操作影响的操作任务单元。原子操作是在多线程环境下避免数据不一致必须的手段。 int++并不是一个原子操作,所以当一个线程读取它的值并加1时,另外一个线程有可能会读到之前的值,这就会引发错误。 为了解决这个问题,必须保证增加操作是原子的,在JDK1.5之前我们可以使用同步技术来做到这一点。到JDK1.5,java.util.concurrent.atomic包提供了int和long类型的原子包装类,它们可以自动的保证对于他们的操作是原子的并且不需要使用同步。
java.util.concurrent这个包里面提供了一组原子类。其基本的特性就是在多线程环境下,当有多个线程同时执行这些类的实例包含的方法时,具有排他性,即当某个线程进入方法,执行其中的指令时,不会被其他线程打断,而别的线程就像自旋锁一样,一直等到该方法执行完成,才由JVM从等待队列中选择一个另一个线程进入,这只是一种逻辑上的理解。
原子类: AtomicBoolean,AtomicInteger,AtomicLong,AtomicReference 原子数组: AtomicIntegerArray,AtomicLongArray,AtomicReferenceArray 原子属性更新器: AtomicLongFieldUpdater,AtomicIntegerFieldUpdater,AtomicReferenceFieldUpdater 解决ABA问题的原子类: AtomicMarkableReference(通过引入一个boolean来反映中间有没有变过),AtomicStampedReference(通过引入一个int来累加来反映中间有没有变过)
11、Java Concurrency API 中的 Lock 接口(Lock interface)是什么?对比同步它有什么优势?
Lock 与 synchronized 相同的功能是都能对多线程对静态资源的修改做同步(互斥)控制:但Lock有优势的地方在于:
- 操作方面(锁控制): Lock 是可以手动控制加锁与释放锁操作的。而synchronized自动释放锁。
- 性能方面: 使用到 Lock 接口 的实现类 ReadWriteLock 子类 ReentrantReadWriteLock 的 对象rwl,在多线程同时对静态资源进行修改时,可以使用 rwl.readLock().lock() 或者 rwl.writeLock().lock() 对静态资源做并发修改控制。读写锁可以实现读写互斥,但是读读不互斥,这个是synchroized实现不了的,synchroized对读读也互斥。
- 线程通信方面: Lock对应的实现类对象lock 通过 lock.newCondition() 可以实例化Condition对象condition,condition 通过 condition.await() 实现synchronized + t.wait() 的效果,t代表线程,通过condition.signal()或者 condition.signalAll()实现线程唤醒,且lock 可以为读写线程创建两种不同操作(read or write)类型的Condition对象,使得线程间通信要比传统的wait(),notifiy()进行线程通信的效率要高很多。使得加锁,释放锁的操作更具选择性,精准性。
12、什么是 Executors 框架?
Executors框架其内部采用了线程池机制,他在java.util.cocurrent包下,通过该框架来控制线程的启动、执行、关闭,可以简化并发编程的操作。因此,通过Executors来启动线程比使用Thread的start方法更好,而且更容易管理,效率更好,还有关键的一点:有助于避免this溢出。
Executors框架包括:线程池、Executor,Executors,ExecutorService、CompletionServince,Future、Callable。
13、什么是阻塞队列?阻塞队列的实现原理是什么?如何使用阻塞队列来实现生产者-消费者模型?
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。
这两个附加的操作是:在队列为空时,获取元素的线程会等待队列变为非空。当队列满时,存储元素的线程会等待队列可用。
阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。
JDK7提供了7个阻塞队列。分别是:
- ArrayBlockingQueue :一个由数组结构组成的有界阻塞队列。
- LinkedBlockingQueue :一个由链表结构组成的有界阻塞队列。
- PriorityBlockingQueue :一个支持优先级排序的***阻塞队列。
- DelayQueue:一个使用优先级队列实现的***阻塞队列。
- SynchronousQueue:一个不存储元素的阻塞队列。
- LinkedTransferQueue:一个由链表结构组成的***阻塞队列。
- LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
Java 5之前实现同步存取时,可以使用普通的一个集合,然后在使用线程的协作和线程同步可以实现生产者,消费者模式,主要的技术就是用好,wait ,notify,notifyAll,sychronized这些关键字。而在java 5之后,可以使用阻塞队列来实现,此方式大大简少了代码量,使得多线程编程更加容易,安全方面也有保障。 BlockingQueue接口是Queue的子接口,它的主要用途并不是作为容器,而是作为线程同步的的工具,因此他具有一个很明显的特性,当生产者线程试图向BlockingQueue放入元素时,如果队列已满,则线程被阻塞,当消费者线程试图从中取出一个元素时,如果队列为空,则该线程会被阻塞,正是因为它所具有这个特性,所以在程序中多个线程交替向BlockingQueue中放入元素,取出元素,它可以很好的控制线程之间的通信。
阻塞队列使用最经典的场景就是socket客户端数据的读取和解析,读取数据的线程不断将数据放入队列,然后解析线程不断从队列取数据解析。
14、什么是 Callable 和 Future?
Callable接口类似于Runnable,从名字就可以看出来了,但是Runnable不会返回结果,并且无法抛出返回结果的异常,而Callable功能更强大一些,被线程执行后,可以返回值,这个返回值可以被Future拿到,也就是说,Future可以拿到异步执行任务的返回值。 可以认为是带有回调的Runnable。
Future接口表示异步任务,是还没有完成的任务给出的未来结果。所以说Callable用于产生结果,Future用于获取结果。
15、什么是 FutureTask?使用 ExecutorService 启动任务。
在Java并发程序中FutureTask表示一个可以取消的异步运算。它有启动和取消运算、查询运算是否完成和取回运算结果等方法。只有当运算完成的时候结果才能取回,如果运算尚未完成get方法将会阻塞。一个FutureTask对象可以对调用了Callable和Runnable的对象进行包装,由于FutureTask也是调用了Runnable接口所以它可以提交给Executor来执行
16、什么是并发容器的实现?
何为同步容器: 可以简单地理解为通过synchronized来实现同步的容器,如果有多个线程调用同步容器的方法,它们将会串行执行。比如Vector,Hashtable,以及Collections.synchronizedSet,synchronizedList等方法返回的容器。 可以通过查看Vector,Hashtable等这些同步容器的实现代码,可以看到这些容器实现线程安全的方式就是将它们的状态封装起来,并在需要同步的方法上加上关键字synchronized。
并发容器 使用了与同步容器完全不同的加锁策略来提供更高的并发性和伸缩性,例如在ConcurrentHashMap中采用了一种粒度更细的加锁机制,可以称为分段锁,在这种锁机制下,允许任意数量的读线程并发地访问map,并且执行读操作的线程和写操作的线程也可以并发的访问map,同时允许一定数量的写操作线程并发地修改map,所以它可以在并发环境下实现更高的吞吐量。
17、多线程同步和互斥有几种实现方法,都是什么?
同步和互斥
当有多个线程的时候,经常需要去同步这些线程以访问同一个数据或资源。例如,假设有一个程序,其中一个线程用于把文件读到内存,而另一个线程用于统计文件中的字符数。当然,在把整个文件调入内存之前,统计它的计数是没有意义的。但是,由于每个操作都有自己的线程,操作系统会把两个线程当作是互不相干的任务分别执行,这样就可能在没有把整个文件装入内存时统计字数。为解决此问题,你必须使两个线程同步工作。
所谓同步,是指在不同进程之间的若干程序片断,它们的运行必须严格按照规定的某种先后次序来运行,这种先后次序依赖于要完成的特定的任务。如果用对资源的访问来定义的话,同步是指在互斥的基础上(大多数情况),通过其它机制实现访问者对资源的有序访问。在大多数情况下,同步已经实现了互斥,特别是所有写入资源的情况必定是互斥的。少数情况是指可以允许多个访问者同时访问资源。
所谓互斥,是指散布在不同进程之间的若干程序片断,当某个进程运行其中一个程序片段时,其它进程就不能运行它们之中的任一程序片段,只能等到该进程运行完这个程序片段后才可以运行。如果用对资源的访问来定义的话,互斥某一资源同时只允许一个访问者对其进行访问,具有唯一性和排它性。但互斥无法限制访问者对资源的访问顺序,即访问是无序的。
多线程同步和互斥有几种实现方法
线程间的同步方法大体可分为两类:用户模式和内核模式。顾名思义,内核模式就是指利用系统内核对象的单一性来进行同步,使用时需要切换内核态与用户态,而用户模式就是不需要切换到内核态,只在用户态完成操作。
用户模式下的方法有:原子操作(例如一个单一的全局变量),临界区。
内核模式下的方法有:事件,信号量,互斥量。
- 临界区:通过对多线程的串行化来访问公共资源或一段代码,速度快,适合控制数据访问。
- 互斥量:为协调共同对一个共享资源的单独访问而设计的。
- 信号量:为控制一个具有有限数量用户资源而设计。
- 事 件:用来通知线程有一些事件已发生,从而启动后继任务的开始。
18、什么是竞争条件?你怎样发现和解决竞争?
- 当多个进程都企图对共享数据进行某种处理,而最后的结果又取决于进程运行的顺序时,则我们认为这发生了竞争条件(race condition)。
19、你将如何使用 thread dump?你将如何分析 Thread dump?165
新建状态(New)
用 new 语句创建的线程处于新建状态,此时它和其他 Java 对象一样,仅仅在堆区
中被分配了内存。
就绪状态(Runnable)
当一个线程对象创建后,其他线程调用它的 start()方法,该线程就进入就绪状态,
Java 虚拟机会为它创建方法调用栈和程序计数器。处于这个状态的线程位于可运
行池中,等待获得 CPU 的使用权。
运行状态(Running)
处于这个状态的线程占用 CPU,执行程序代码。只有处于就绪状态的线程才有机
会转到运行状态。
阻塞状态(Blocked)
阻塞状态是指线程因为某些原因放弃 CPU,暂时停止运行。当线程处于阻塞状态
时,Java 虚拟机不会给线程分配 CPU。直到线程重新进入就绪状态,它才有机会
转到运行状态。
阻塞状态可分为以下 3 种:
位于对象等待池中的阻塞状态(Blocked in object’s wait pool):
当线程处于运行状态时,如果执行了某个对象的 wait()方法,Java 虚拟机就会把
线程放到这个对象的等待池中,这涉及到“线程通信”的内容。
位于对象锁池中的阻塞状态(Blocked in object’s lock pool):
当线程处于运行状态时,试图获得某个对象的同步锁时,如果该对象的同步锁已
经被其他线程占用,Java 虚拟机就会把这个线程放到这个对象的锁池中,这涉及
到“线程同步”的内容。
其他阻塞状态(Otherwise Blocked):
当前线程执行了 sleep()方法,或者调用了其他线程的 join()方法,或者发出了 I/O
请求时,就会进入这个状态。
死亡状态(Dead)
当线程退出 run()方法时,就进入死亡状态,该线程结束生命周期。
20、为什么我们调用 start()方法时会执行 run()方法,为什么我们不能直接调用 run()方法?
- start() 方法会新建一个线程,并启动,启动方法使用的是run方法
- run方法会启动当前线程
21、进程和线程的优缺点
- 线程执行开销小,但不利于资源的管理和保护,而进程相反
22、java Future 接口介绍
-
Future是JAVA并发框架Executor中的一个类,Executor就是Runnable和Callable的调度容器,Future就是对于具体的Runnable或者Callable任务的执行结果进行取消、查询是否完成、获取结果、设置结果操作,用get()可以获得执行结果;
-
如果在主线程中需要执行比较耗时的操作时,但又不想阻塞主线程时,可以把这些作业交给Future对象在后台完成,当主线程将来需要时,就可以通过Future对象获得后台作业的计算结果或者执行状态
23、Java中你怎样唤醒一个阻塞的线程
在Java发展史上曾经使用suspend()、resume()方法对于线程进行阻塞唤醒,但随之出现很多问题,比较典型的还是死锁问题。 解决方案可以使用以对象为目标的阻塞,即__利用Object类的wait()和notify()方法实现线程阻塞__。 首先,wait、notify方法是针对对象的,调用任意对象的wait()方法都将导致线程阻塞,阻塞的同时也将释放该对象的锁,相应地,调用任意对象的notify()方法则将随机解除该对象阻塞的线程,但它需要重新获取改对象的锁,直到获取成功才能往下执行;其次,wait、notify方法必须在synchronized块或方法中被调用,并且要保证同步块或方法的锁对象与调用wait、notify方法的对象是同一个,如此一来在调用wait之前当前线程就已经成功获取某对象的锁,执行wait阻塞后当前线程就将之前获取的对象锁释放。
24、Java中用到的线程调度算法是什么
计算机通常只有一个CPU,在任意时刻只能执行一条机器指令,每个线程只有获得CPU的使用权才能执行指令.所谓多线程的并发运行,其实是指从宏观上看,各个线程轮流获得CPU的使用权,分别执行各自的任务.在运行池中,会有多个处于就绪状态的线程在等待CPU,JAVA虚拟机的一项任务就是负责线程的调度,线程调度是指按照特定机制为多个线程分配CPU的使用权.
有两种调度模型:分时调度模型和抢占式调度模型。 __分时调度模型__是指让所有的线程轮流获得cpu的使用权,并且平均分配每个线程占用的CPU的时间片这个也比较好理解。
java虚拟机采用抢占式调度模型,是指优先让可运行池中优先级高的线程占用CPU,如果可运行池中的线程优先级相同,那么就随机选择一个线程,使其占用CPU。处于运行状态的线程会一直运行,直至它不得不放弃CPU。
25、Java中有几种方法可以实现一个线程
继承 Thread 类 实现 Runnable 接口 实现 Callable 接口,需要实现的是 call() 方法
26、如何停止一个正在运行的线程
使用共享变量的方式 在这种方式中,之所以引入共享变量,是因为该变量可以被多个执行相同任务的线程用来作为是否中断的信号,通知中断线程的执行。
使用interrupt方法终止线程 如果一个线程由于等待某些事件的发生而被阻塞,又该怎样停止该线程呢?这种情况经常会发生,比如当一个线程由于需要等候键盘输入而被阻塞,或者调用Thread.join()方法,或者Thread.sleep()方法,在网络中调用ServerSocket.accept()方法,或者调用了DatagramSocket.receive()方法时,都有可能导致线程阻塞,使线程处于处于不可运行状态时,即使主程序中将该线程的共享变量设置为true,但该线程此时根本无法检查循环标志,当然也就无法立即中断。这里我们给出的建议是,不要使用stop()方法,而是使用Thread提供的interrupt()方法,因为该方法虽然不会中断一个正在运行的线程,但是它可以使一个被阻塞的线程抛出一个中断异常,从而使线程提前结束阻塞状态,退出堵塞代码。
27、notify()和notifyAll()有什么区别
当一个线程进入wait之后,就必须等其他线程notify/notifyall,使用notifyall,可以唤醒所有处于wait状态的线程,使其重新进入锁的争夺队列中,而notify只能唤醒一个。
如果没把握,建议notifyAll,防止notigy因为信号丢失而造成程序异常。
28、什么是Daemon线程,它有什么意义
所谓后台(daemon)线程,是指在程序运行的时候在后台提供一种通用服务的线程,并且这个线程并不属于程序中不可或缺的部分。因此,当所有的非后台线程结束时,程序也就终止了,同时会杀死进程中的所有后台线程。反过来说, 只要有任何非后台线程还在运行,程序就不会终止。必须在线程启动之前调用setDaemon()方法,才能把它设置为后台线程。注意:后台进程在不执行finally子句的情况下就会终止其run()方法。
比如:JVM的垃圾回收线程就是Daemon线程,Finalizer也是守护线程。
29、Java如何实现多线程之间的通讯和协作
中断 和 共享变量
Java线程Executor框架详解与使用
在HotSpot VM的线程模型中,Java线程被一对一映射为本地操作系统线程。Java线程启动时会创建一个本地操作系统线程;当该Java线程终止时,这个操作系统线程也会被回收,在JVM中我们可以通过-Xss设置每个线程的大小。操作系统会调度所有线程并将它们分配给可用的CPU。 在上层,Java多线程程序通常把应用分解为若干个任务,然后使用用户级的调度器(Executor框架)将这些任务映射为固定数量的线程;在底层,操作系统内核将这些线程映射到硬件处理器上。这种两级调度模型的示意图如下图所示
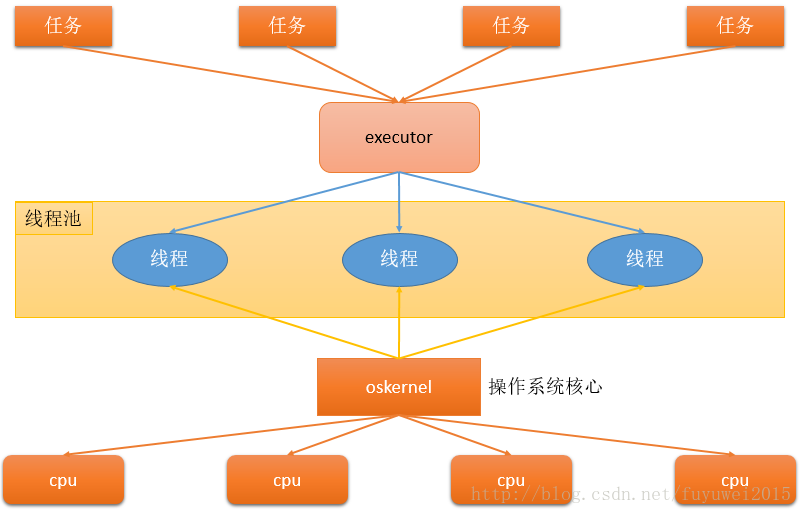
通过上图可以看出应用程序通过Executor控制上层调度,操作系统内核控制下层调度。 注:oskernel操作系统核心包括操作系统软件和应用,只是操作系统最基本的功能,例如内存管理,进程管理,硬件驱动等
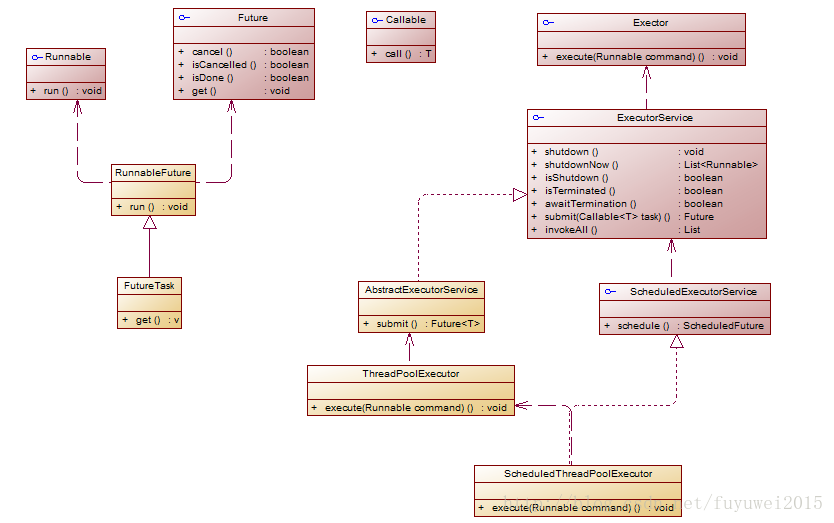
Executor结构
executor结构主要包括任务、任务的执行和异步结果的计算。 任务 包括被执行任务需要实现的接口:Runnable接口或Callable接口 任务的执行 包括任务执行机制的核心接口Executor,以及继承自Executor的ExecutorService接口。Executor框架有两个关键类实现了ExecutorService接口(ThreadPoolExecutor和ScheduledThreadPoolExecutor) 异步计算的结果 包括接口Future和实现Future接口的FutureTask类 下面我们来看看executor类图
在Executor使用过程中,主线程首先要创建实现Runnable或者Callable接口的任务对象。工具类Executors可以把一个Runnable对象封装为一个Callable对象(Executors.callable(Runnable task)或Executors.callable(Runnable task,Object resule))。 如果执行ExecutorService.submit(…),ExecutorService将返回一个实现Future接口的对象(FutureTask)。由于FutureTask实现了Runnable,我们也可以创建FutureTask,然后直接交给ExecutorService执行。最后,主线程可以执行FutureTask.get()方法来等待任务执行完成。主线程也可以执行FutureTask.cancel(boolean mayInterruptIfRunning)来取消此任务的执行。
FixedThreadPool
初始化
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}
FixedThreadPool的corePoolSize和maximumPoolSize都被设置为创建FixedThreadPool时指定的参数nThreads。当线程池中的线程数大于corePoolSize时,keepAliveTime为多余的空闲线程等待新任务的最长时间,超过这个时间后多余的线程将被终止。这里把keepAliveTime设置为0L,意味着多余的空闲线程会被立即终止
运行过程
下面是FixedThreadPool运行过程示意图
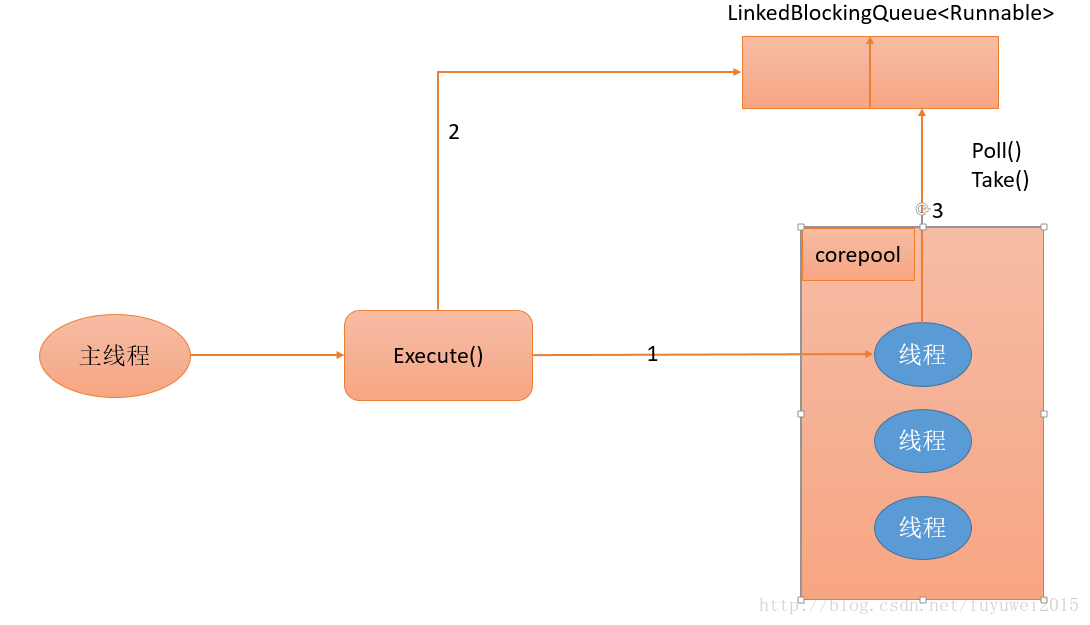
- 如果当前运行的线程数少于corePoolSize,则创建新线程来执行任务。
- 在线程池完成预热之后(当前运行的线程数等于corePoolSize),将任务加入LinkedBlockingQueue。
- 线程执行完1中的任务后,会在循环中反复从LinkedBlockingQueue获取任务来执行。 FixedThreadPool使用无界队列LinkedBlockingQueue作为线程池的工作队列(队列的容量为Integer.MAX_VALUE)。
使用无界队列作为工作队列会对线程池带来如下影响
- 当线程池中的线程数达到corePoolSize后,新任务将在无界队列中等待,因此线程池中的线程数不会超过corePoolSize。
- 由于1,使用无界队列时maximumPoolSize将是一个无效参数。
- 由于1和2,使用无界队列时keepAliveTime将是一个无效参数。
- 由于使用无界队列,运行中的FixedThreadPool(未执行方法shutdown()或shutdownNow())不会拒绝任务(不会调用RejectedExecutionHandler.rejectedExecution方法)。
使用场景
FixedThreadPool适用于为了满足资源管理的需求,而需要限制当前线程数量的应用场景,它适用于负载比较重的服务器
SingleThreadExecutor
初始化
创建使用单个线程的SingleThread-Executor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}
SingleThreadExecutor的corePoolSize和maximumPoolSize被设置为1。其他参数与FixedThreadPool相同。SingleThreadExecutor使用无界队列LinkedBlockingQueue作为线程池的工作队列(队列的容量为Integer.MAX_VALUE)。SingleThreadExecutor使用无界队列作为工作队列对线程池带来的影响与FixedThreadPool相同
运行过程
下图是SingleThreadExecutor的运行过程示意图
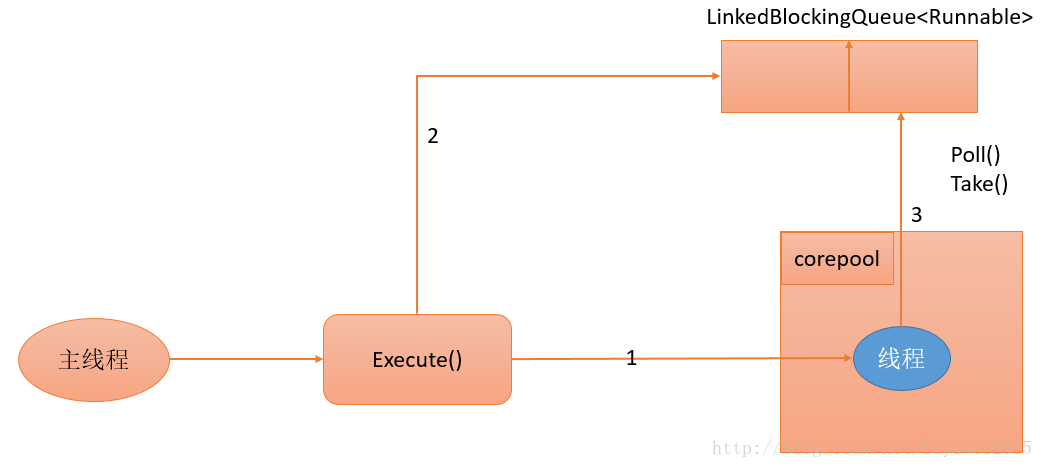
- 如果当前运行的线程数少于corePoolSize(即线程池中无运行的线程),则创建一个新线程来执行任务。
- 在线程池完成预热之后(当前线程池中有一个运行的线程),将任务加入LinkedBlockingQueue。
- 线程执行完1中的任务后,会在一个无限循环中反复从LinkedBlockingQueue获取任务来执行。
使用场景
SingleThreadExecutor适用于需要保证顺序地执行各个任务;并且在任意时间点,不会有多个线程是活动的应用场景。
CachedThreadPool
初始化
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}
CachedThreadPool的corePoolSize被设置为0,即corePool为空;maximumPoolSize被设置为Integer.MAX_VALUE,即maximumPool是无界的。这里把keepAliveTime设置为60L,意味着CachedThreadPool中的空闲线程等待新任务的最长时间为60秒,空闲线程超过60秒后将会被终止。 FixedThreadPool和SingleThreadExecutor使用无界队列LinkedBlockingQueue作为线程池的工作队列。CachedThreadPool使用没有容量的SynchronousQueue作为线程池的工作队列,但CachedThreadPool的maximumPool是无界的。这意味着,如果主线程提交任务的速度高于maximumPool中线程处理任务的速度时,CachedThreadPool会不断创建新线程。极端情况下,CachedThreadPool会因为创建过多线程而耗尽CPU和内存资源。
运行过程
下图是CachedThreadPool的运行过程示意图
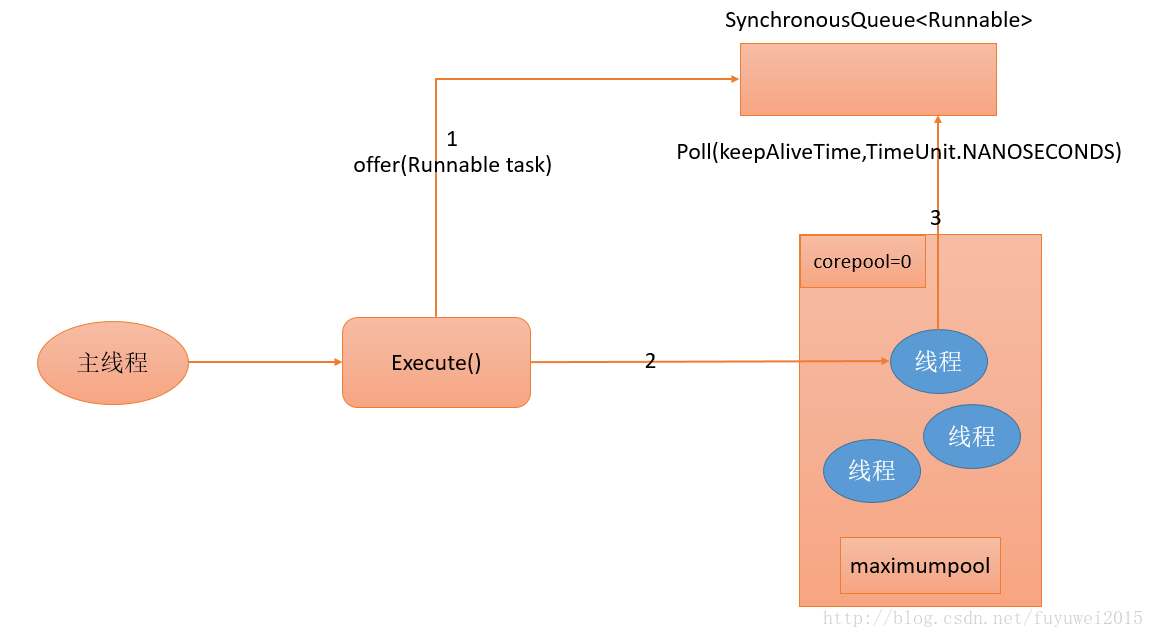
- 首先执行SynchronousQueue.offer(Runnable task)。如果当前maximumPool中有空闲线程正在执行SynchronousQueue.poll(keepAliveTime,TimeUnit.NANOSECONDS),那么主线程执行offer操作与空闲线程执行的poll操作配对成功,主线程把任务交给空闲线程执行,execute()方法执行完成;否则执行下面的步骤2)。
- 当初始maximumPool为空,或者maximumPool中当前没有空闲线程时,将没有线程执行SynchronousQueue.poll (keepAliveTime,TimeUnit.NANOSECONDS)。这种情况下,步骤1)将失败。此时CachedThreadPool会创建一个新线程执行任务,execute()方法执行完成。
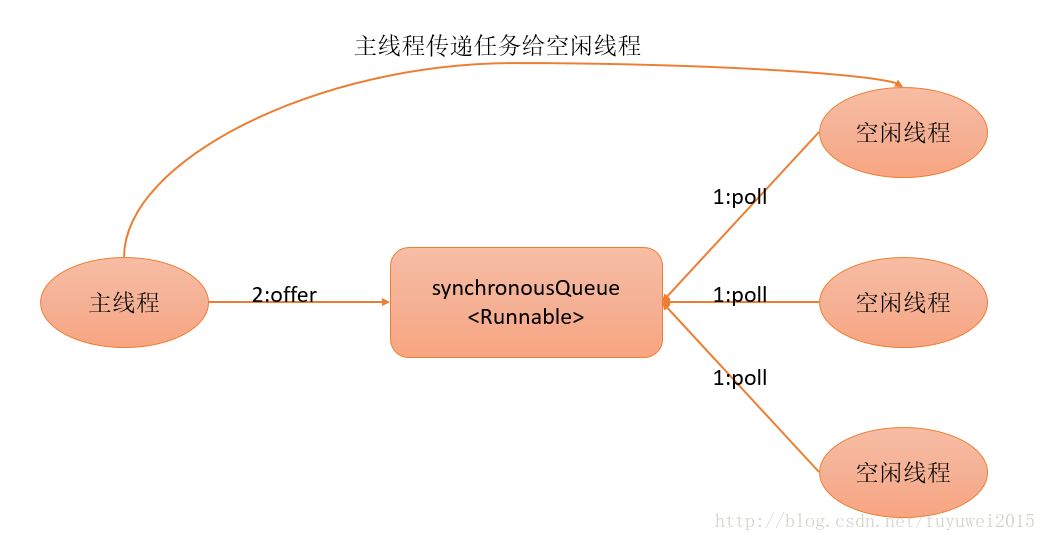
- 在步骤2)中新创建的线程将任务执行完后,会执行SynchronousQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS)。这个poll操作会让空闲线程最多在SynchronousQueue中等待60秒钟。如果60秒钟内主线程提交了一个新任务(主线程执行步骤1)),那么这个空闲线程将执行主线程提交的新任务;否则,这个空闲线程将终止。由于空闲60秒的空闲线程会被终止,因此长时间保持空闲的CachedThreadPool不会使用任何资源。 前面提到过,SynchronousQueue是一个没有容量的阻塞队列。每个插入操作必须等待另一个线程的对应移除操作,反之亦然。CachedThreadPool使用SynchronousQueue,把主线程提交的任务传递给空闲线程执行。CachedThreadPool中任务传递的示意图如下图所示:
使用场景
看名字我们可以知道cached缓存,CachedThreadPool可以创建一个可根据需要创建新线程的线程池,但是在以前构造的线程可用时将重用它们,对于执行很多短期异步任务的程序而言,这些线程池通常可提高程序性能。调用 execute 将重用以前构造的线程(如果线程可用)。如果现有线程没有可用的,则创建一个新线程并添加到池中。 CachedThreadPool是大小无界的线程池,适用于执行很多的短期异步任务的小程序,或者是负载较轻的服务器。
ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor继承自ThreadPoolExecutor。它主要用来在给定的延迟之后运行任务,或者定期执行任务。ScheduledThreadPoolExecutor的功能与Timer类似,但ScheduledThreadPoolExecutor功能更强大、更灵活。Timer对应的是单个后台线程,而ScheduledThreadPoolExecutor可以在构造函数中指定多个对应的后台线程数
初始化
ScheduledThreadPoolExecutor通常使用工厂类Executors来创建。Executors可以创建2种类型的 ScheduledThreadPoolExecutor,如下。 ScheduledThreadPoolExecutor:包含若干个线程的ScheduledThreadPoolExecutor。 SingleThreadScheduledExecutor:只包含一个线程的ScheduledThreadPoolExecutor。 下面分别介绍这两种ScheduledThreadPoolExecutor。
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, TimeUnit.NANOSECONDS,
new DelayedWorkQueue(), threadFactory, handler);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, TimeUnit.NANOSECONDS,
new DelayedWorkQueue());
}
直接调用父类ThreadPoolExecutor构造方法进行初始化。ScheduledThreadPoolExecutor适用于需要多个后台线程执行周期任务,同时为了满足资源管理的需求而需要限制后台线程的数量的应用场景。 下面看看如何创建SingleThreadScheduledExecutor
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}
public static ScheduledExecutorService newSingleThreadScheduledExecutor(ThreadFactory threadFactory) {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1, threadFactory));
}
运行过程
DelayQueue是一个无界队列,所以ThreadPoolExecutor的maximumPoolSize在ScheduledThreadPoolExecutor中没有什么意义(设置maximumPoolSize的大小没有什么效果)。ScheduledThreadPoolExecutor的执行主要分为两大部分。
- 当调用ScheduledThreadPoolExecutor的scheduleAtFixedRate()方法或者scheduleWithFixedDelay()方法时,会向ScheduledThreadPoolExecutor的DelayQueue添加一个实现了RunnableScheduledFutur接口的ScheduledFutureTask。
- 线程池中的线程从DelayQueue中获取ScheduledFutureTask,然后执行任务。
下面看看ScheduedThreadPoolExecutor运行过程示意图
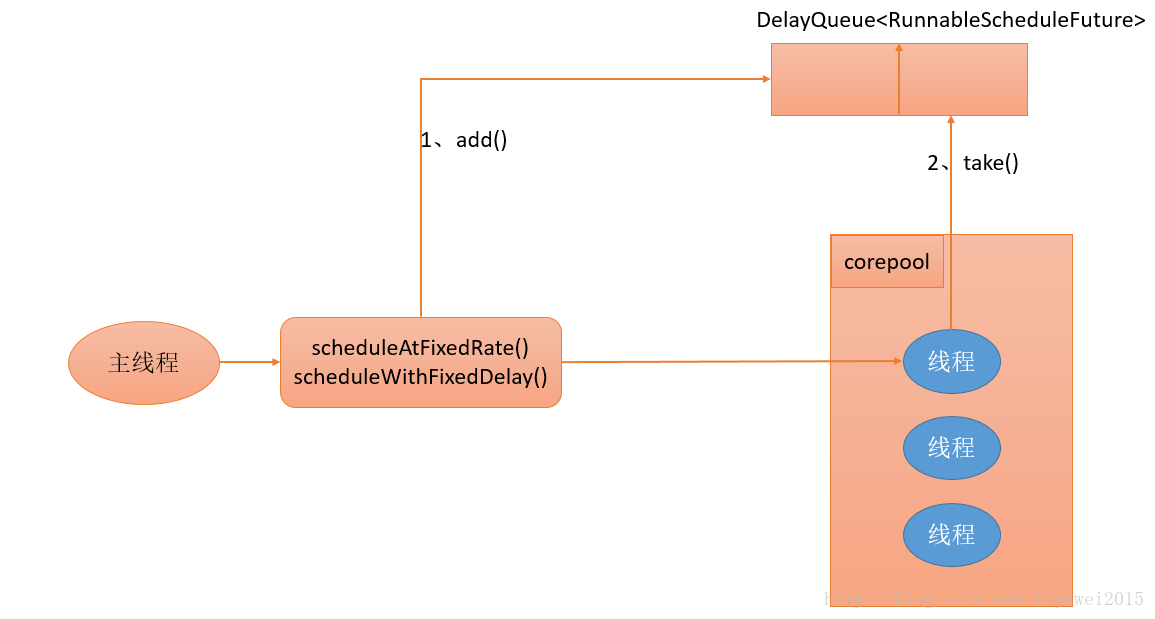
ScheduledThreadPoolExecutor为了实现周期性的执行任务,对ThreadPoolExecutor做了如下 的修改。
- 使用DelayQueue作为任务队列。
- 获取任务的方式不同(后文会说明)。
- 执行周期任务后,增加了额外的处理(后文会说明)。
实现过程分析
ScheduledThreadPoolExecutor会把待调度的任务(ScheduledFutureTask)放到一个DelayQueue中。ScheduledFutureTask主要包含3个成员变量,如下。
-
long time,表示这个任务将要被执行的具体时间。
-
long sequenceNumber,表示这个任务被添加到ScheduledThreadPoolExecutor中的序号。
-
long period,表示任务执行的间隔周期。
DelayQueue封装了一个PriorityQueue,这个PriorityQueue会对队列中的ScheduledFutureTask进行排序。排序时,time小的排在前面(时间早的任务将被先执行)。如果两个ScheduledFutureTask的time相同,就比较sequenceNumber,sequenceNumber小的排在前面(也就是说,如果两个任务的执行时间相同,那么先提交的任务将被先执行)。首先,让我们看看ScheduledThreadPoolExecutor中的线程执行周期任务的过程。如下图所示
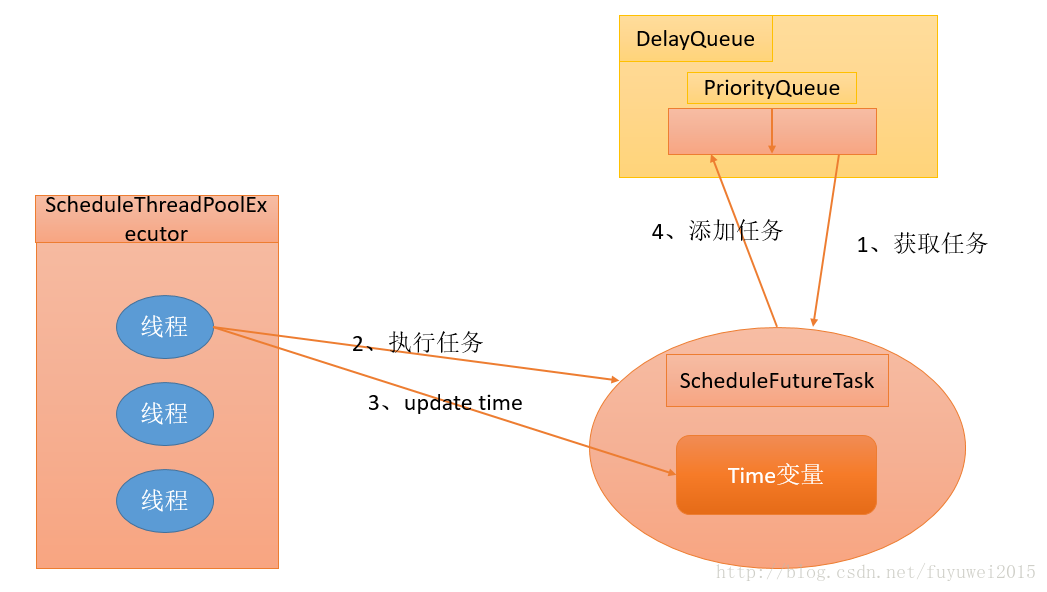
- 线程1从DelayQueue中获取已到期的ScheduledFutureTask(DelayQueue.take())。到期任务是指ScheduledFutureTask的time大于等于当前时间。
- 线程1执行这个ScheduledFutureTask。
- 线程1修改ScheduledFutureTask的time变量为下次将要被执行的时间。
- 线程1把这个修改time之后的ScheduledFutureTask放回DelayQueue中(DelayQueue.add())。
下面我们看看DelayQueue.take()的源码是如何实现的
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly(); // 1
try {
for (;;) {
E first = q.peek();
if (first == null) {
available.await(); // 2.1
} else {
long delay = first.getDelay(TimeUnit.NANOSECONDS);
if (delay > 0) {
long tl = available.awaitNanos(delay); // 2.2
} else {
E x = q.poll(); // 2.3.1
assert x != null;
if (q.size() != 0)
available.signalAll(); // 2.3.2
return x;
}
}
}
} finally {
lock.unlock(); // 3
}
}
下面我们对上面的代码用流程图展示出来
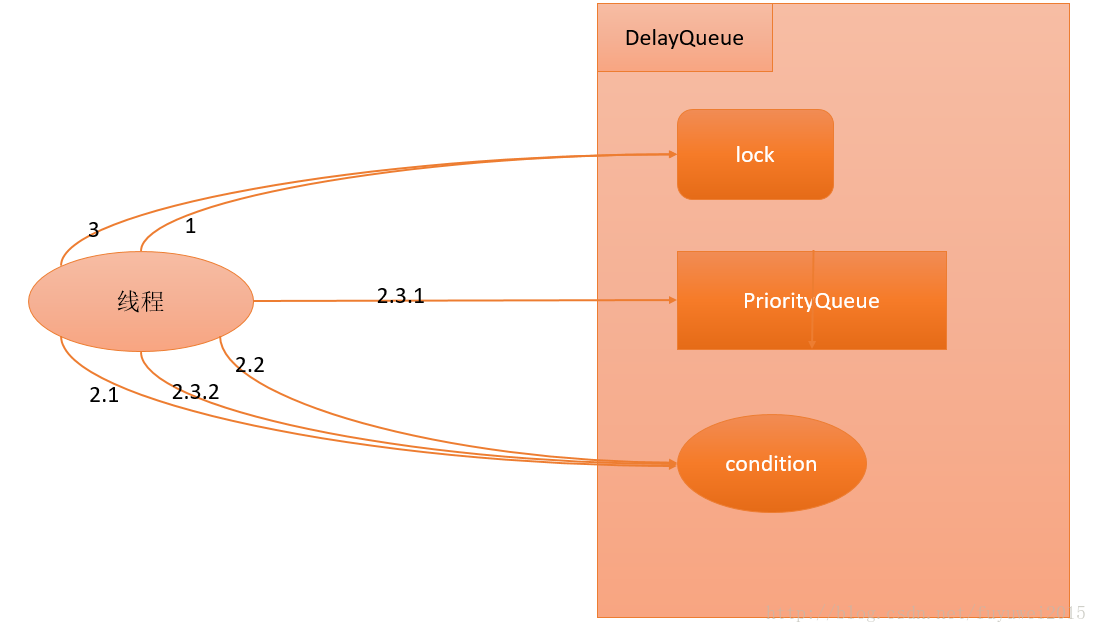
- 获取Lock。
- 获取周期任务。 a、如果PriorityQueue为空,当前线程到Condition中等待;否则执行下面的2.2。 b、如果PriorityQueue的头元素的time时间比当前时间大,到Condition中等待到time时间;否则执行下面的2.3。 c、获取PriorityQueue的头元素(2.3.1);如果PriorityQueue不为空,则唤醒在Condition中等待的所有线程(2.3.2)。
- 释放Lock。
ScheduledThreadPoolExecutor在一个循环中执行步骤2,直到线程从PriorityQueue获取到一个元素之后(执行2.3.1之后),才会退出无限循环(结束步骤2)。 下面我来看看DelayQueue.add()源码实现
public boolean offer(E e) {
final ReentrantLock lock = this.lock;
lock.lock(); // 1
try {
E first = q.peek();
q.offer(e); // 2.1
if (first == null || e.compareTo(first) < 0)
available.signalAll(); // 2.2
return true;
} finally {
lock.unlock(); // 3
}
}
下面我们对上面的代码用流程图展示出来
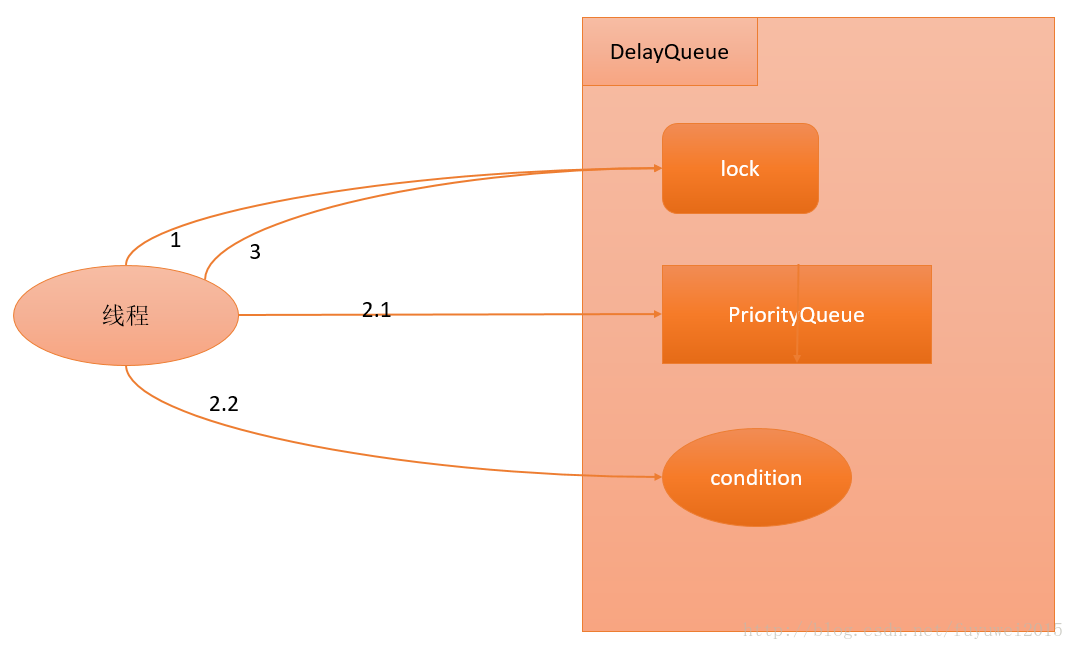
- 获取Lock。
- 添加任务。 a、向PriorityQueue添加任务。 b、如果在上面2.1中添加的任务是PriorityQueue的头元素,唤醒在Condition中等待的所有线程。
- 释放Lock。
使用场景
SingleThreadScheduledExecutor适用于需要单个后台线程执行周期任务,同时需要保证顺序地执行各个任务的应用场景。
Java深入理解深拷贝和浅拷贝区别
一、拷贝的引入
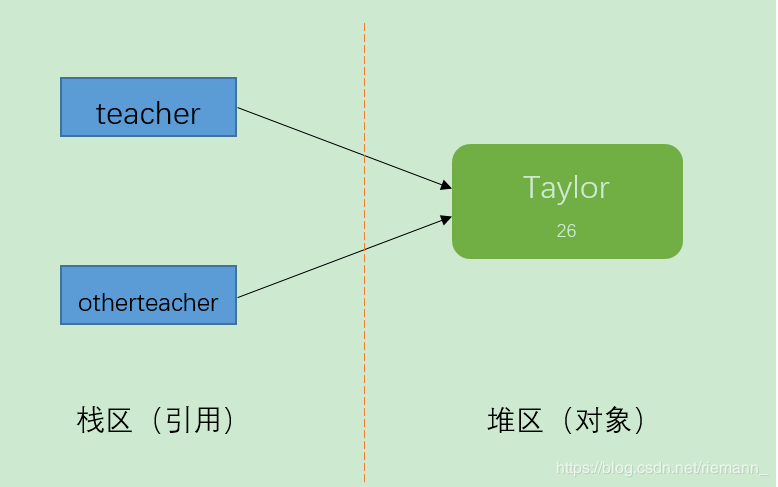
(1)、引用拷贝
创建一个指向对象的引用变量的拷贝。
Teacher teacher = new Teacher("Taylor",26);
Teacher otherteacher = teacher;
System.out.println(teacher);
System.out.println(otherteacher);
输出结果:
blog.Teacher@355da254
blog.Teacher@355da254
结果分析:由输出结果可以看出,它们的地址值是相同的,那么它们肯定是同一个对象。teacher和otherteacher的只是引用而已,他们都指向了一个相同的对象Teacher(“Taylor”,26)。 这就叫做引用拷贝。
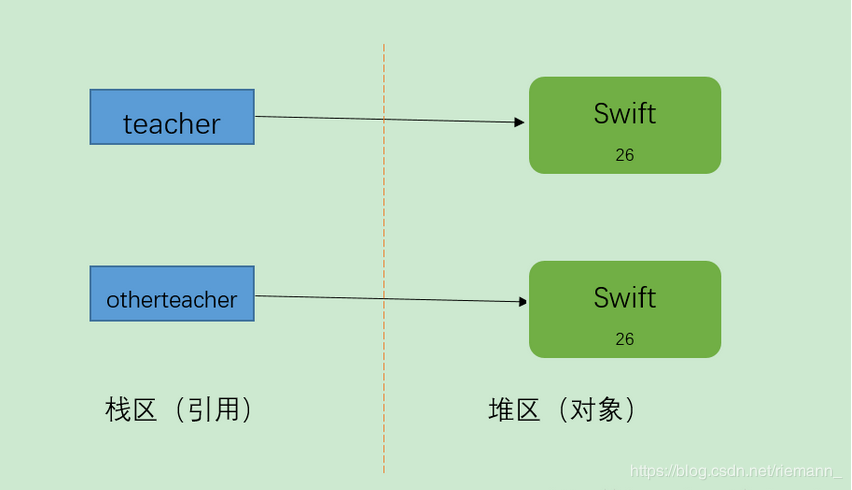
(2)、对象拷贝
创建对象本身的一个副本。
Teacher teacher = new Teacher("Swift",26);
Teacher otherteacher = (Teacher)teacher.clone();
System.out.println(teacher);
System.out.println(otherteacher);
输出结果:
blog.Teacher@355da254
blog.Teacher@4dc63996
结果分析:由输出结果可以看出,它们的地址是不同的,也就是说创建了新的对象, 而不是把原对象的地址赋给了一个新的引用变量,这就叫做对象拷贝。
==注:深拷贝和浅拷贝都是对象拷贝==
二、浅拷贝
(1)、定义
被复制对象的所有变量都含有与原来的对象相同的值,而所有的对其他对象的引用仍然指向原来的对象。即对象的浅拷贝会对“主”对象进行拷贝,但不会复制主对象里面的对象。”里面的对象“会在原来的对象和它的副本之间共享。
简而言之,浅拷贝仅仅复制所考虑的对象,而不复制它所引用的对象
(2)、浅拷贝实例
package com.test;
public class ShallowCopy {
public static void main(String[] args) throws CloneNotSupportedException {
Teacher teacher = new Teacher();
teacher.setName("riemann");
teacher.setAge(27);
Student2 student1 = new Student2();
student1.setName("edgar");
student1.setAge(18);
student1.setTeacher(teacher);
Student2 student2 = (Student2) student1.clone();
System.out.println("拷贝后");
System.out.println(student2.getName());
System.out.println(student2.getAge());
System.out.println(student2.getTeacher().getName());
System.out.println(student2.getTeacher().getAge());
System.out.println("修改老师的信息后-------------");
// 修改老师的信息
teacher.setName("Games");
System.out.println(student1.getTeacher().getName());
System.out.println(student2.getTeacher().getName());
}
}
class Teacher implements Cloneable {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
class Student2 implements Cloneable {
private String name;
private int age;
private Teacher teacher;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Teacher getTeacher() {
return teacher;
}
public void setTeacher(Teacher teacher) {
this.teacher = teacher;
}
public Object clone() throws CloneNotSupportedException {
Object object = super.clone();
return object;
}
}
输出结果:
拷贝后
edgar
18
riemann
27
修改老师的信息后-------------
Games
Games
结果分析: 两个引用student1和student2指向不同的两个对象,但是两个引用student1和student2中的两个teacher引用指向的是同一个对象,所以说明是浅拷贝。
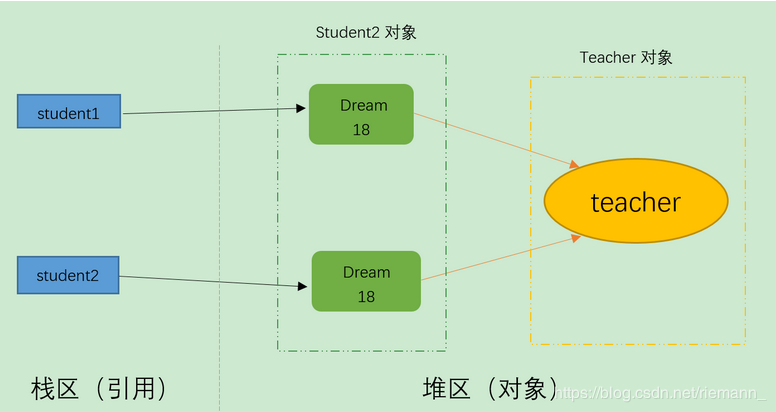
三、深拷贝
(1)、定义
深拷贝是一个整个独立的对象拷贝,深拷贝会拷贝所有的属性,并拷贝属性指向的动态分配的内存。当对象和它所引用的对象一起拷贝时即发生深拷贝。深拷贝相比于浅拷贝速度较慢并且花销较大。
简而言之,深拷贝把要复制的对象所引用的对象都复制了一遍。
(2)、深拷贝实例
package com.test;
public class DeepCopy {
public static void main(String[] args) throws CloneNotSupportedException {
Teacher2 teacher = new Teacher2();
teacher.setName("riemann");
teacher.setAge(27);
Student3 student1 = new Student3();
student1.setName("edgar");
student1.setAge(18);
student1.setTeacher(teacher);
Student3 student2 = (Student3) student1.clone();
System.out.println("拷贝后");
System.out.println(student2.getName());
System.out.println(student2.getAge());
System.out.println(student2.getTeacher().getName());
System.out.println(student2.getTeacher().getAge());
System.out.println("修改老师的信息后-------------");
// 修改老师的信息
teacher.setName("Games");
System.out.println(student1.getTeacher().getName());
System.out.println(student2.getTeacher().getName());
}
}
class Teacher2 implements Cloneable {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
class Student3 implements Cloneable {
private String name;
private int age;
private Teacher2 teacher;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Teacher2 getTeacher() {
return teacher;
}
public void setTeacher(Teacher2 teacher) {
this.teacher = teacher;
}
public Object clone() throws CloneNotSupportedException {
// 浅复制时:
// Object object = super.clone();
// return object;
// 改为深复制:
Student3 student = (Student3) super.clone();
// 本来是浅复制,现在将Teacher对象复制一份并重新set进来
student.setTeacher((Teacher2) student.getTeacher().clone());
return student;
}
}
输出结果:
拷贝后
edgar
18
riemann
27
修改老师的信息后-------------
Games
riemann
结果分析: 两个引用student1和student2指向不同的两个对象,两个引用student1和student2中的两个teacher引用指向的是两个对象,但对teacher对象的修改只能影响student1对象,所以说是深拷贝。
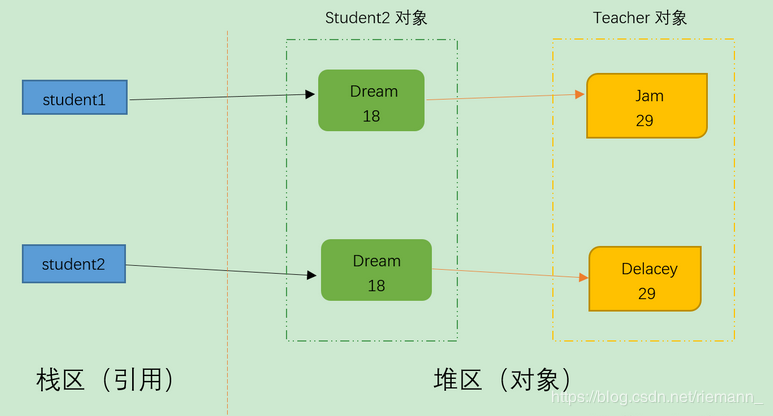
dubbo面试题
1、Dubbo是什么?
- 是一款高性能、轻量级的开源Java RPC框架,它提供了三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现。
其核心部分包含:
Remoting: 网络通信框架,实现了 sync-over-async 和 request-response 消息机制 RPC: 一个远程过程调用的抽象,支持负载均衡、容灾和集群功能 Registry: 服务目录框架用于服务的注册和服务事件发布和订阅
远程通讯: 提供对多种基于长连接的NIO框架抽象封装,包括多种线程模型,序列化,以及“请求-响应”模式的信息交换方式。 集群容错: 提供基于接口方法的透明远程过程调用,包括多协议支持,以及负载均衡、失败容错、地址路由、动态配置等集群支持。 自动发现: 基于注册中心目录服务,使服务消费方能动态的查找服务提供方,使地址透明,使服务提供方可以平滑增加或减少机器。
2、为什么要用Dubbo?
因为是阿里开源项目,国内很多互联网公司都在用,已经经过很多线上考验。内部使用了 Netty、Zookeeper,保证了高性能高可用性。
1、使用Dubbo可以将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,可用于提高业务复用灵活扩展,使前端应用能更快速的响应多变的市场需求。
2、分布式架构可以承受更大规模的并发流量。
3、Dubbo 和 Spring Cloud 有什么区别?
1、通信方式不同:Dubbo 使用的是 RPC 通信,而Spring Cloud 使用的是HTTP RESTFul 方式。
2、组成不一样:
dubbo的服务注册中心为Zookeerper,服务监控中心为dubbo-monitor,无消息总线,服务跟踪、批量任务等组件;
spring-cloud的服务注册中心为spring-cloud netflix enruka,服务监控中心为spring-boot admin,有消息总线,数据流、服务跟踪、批量任务等组件;
4、dubbo都支持什么协议,推荐用哪种?
1、dubbo://(推荐)
2、http://
3、rest://
4、redis://
5、memcached://
5、Dubbo需要 Web 容器吗?
不需要,如果硬要用Web 容器,只会增加复杂性,也浪费资源。
6、Dubbo内置了哪几种服务容器?
三种服务容器:
1、Spring Container
2、Jetty Container
3、Log4j Container
Dubbo 的服务容器只是一个简单的 Main 方法,并加载一个简单的 Spring 容器,用于暴露服务。
7、Dubbo里面有哪几种节点角色?
1、provide:暴露服务的服务提供方
2、consumer:调用远程服务的服务消费方
3、registry:服务注册于发现的注册中心
4、monitor:统计服务调用次数和调用时间的监控中心
5、container:服务运行容器
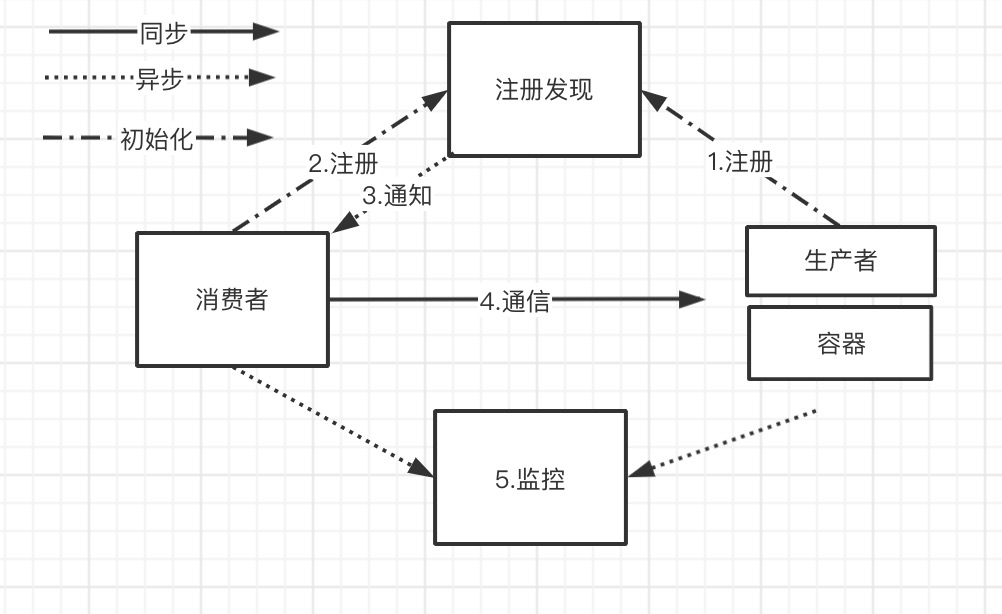
8、画一画服务注册与发现的流程图
9、Dubbo默认使用什么注册中心,还有别的选择吗?
推荐使用zookeeper作为注册中心,还有redis、multicast、simple注册中心。
10、Dubbo有哪几种配置方式?
| 标签 | 用途 | 解释 |
|---|---|---|
<dubbo:service/> |
服务配置 | 用于暴露一个服务,定义服务的元信息,一个服务可以用多个协议暴露,一个服务也可以注册到多个注册中心 |
<dubbo:reference/>[2] |
引用配置 | 用于创建一个远程服务代理,一个引用可以指向多个注册中心 |
<dubbo:protocol/> |
协议配置 | 用于配置提供服务的协议信息,协议由提供方指定,消费方被动接受 |
<dubbo:application/> |
应用配置 | 用于配置当前应用信息,不管该应用是提供者还是消费者 |
<dubbo:module/> |
模块配置 | 用于配置当前模块信息,可选 |
<dubbo:registry/> |
注册中心配置 | 用于配置连接注册中心相关信息 |
<dubbo:monitor/> |
监控中心配置 | 用于配置连接监控中心相关信息,可选 |
<dubbo:provider/> |
提供方配置 | 当 ProtocolConfig 和 ServiceConfig 某属性没有配置时,采用此缺省值,可选 |
<dubbo:consumer/> |
消费方配置 | 当 ReferenceConfig 某属性没有配置时,采用此缺省值,可选 |
<dubbo:method/> |
方法配置 | 用于 ServiceConfig 和 ReferenceConfig 指定方法级的配置信息 |
<dubbo:argument/> |
参数配置 | 用于指定方法参数配置 |
11、服务提供者能实现失效踢出是什么原理?
服务失效踢出基于zookeeper的临时节点原理。
12、在 Provider 上可以配置的 Consumer 端的属性有哪些?
1、timeout:方法调用超时
2、retries:失败重试次数,默认重试 2 次
3、loadbalance:负载均衡算法,默认随机
4、actives 消费者端,最大并发调用限制
13、Dubbo启动时如果依赖的服务不可用会怎样?
Dubbo 缺省会在启动时检查依赖的服务是否可用,不可用时会抛出异常,阻止 Spring 初始化完成,以便上线时,能及早发现问题,默认 check="true"。
可以通过 check="false" 关闭检查,比如,测试时,有些服务不关心,或者出现了循环依赖,必须有一方先启动。
另外,如果你的 Spring 容器是懒加载的,或者通过 API 编程延迟引用服务,请关闭 check,否则服务临时不可用时,会抛出异常,拿到 null 引用,如果 check="false",总是会返回引用,当服务恢复时,能自动连上。
关闭某个服务的启动时检查 (没有提供者时报错):
<dubbo:reference interface="com.foo.BarService" check="false" />
关闭所有服务的启动时检查 (没有提供者时报错):
<dubbo:consumer check="false" />
关闭注册中心启动时检查 (注册订阅失败时报错):
<dubbo:registry check="false" />
14、Dubbo推荐使用什么序列化框架,你知道的还有哪些?
推荐使用Hessian序列化,还有Duddo、FastJson、Java自带序列化;
15、Dubbo默认使用的是什么通信框架,还有别的选择吗?
Dubbo 默认使用 Netty 框架,也是推荐的选择,另外内容还集成有Mina、Grizzly。
16、Dubbo有哪几种集群容错方案,默认是哪种?
Failover Cluster
- 失败自动切换,当出现失败,重试其它服务器。通常用于读操作,但重试会带来更长延迟。可通过
retries="2"来设置重试次数(不含第一次)。
重试次数配置如下:
<dubbo:service retries="2" />
或
<dubbo:reference retries="2" />
或
<dubbo:reference>
<dubbo:method name="findFoo" retries="2" />
</dubbo:reference>
Failfast Cluster
快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
Failsafe Cluster
失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
Failback Cluster
失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
Forking Cluster
并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks="2" 来设置最大并行数。
Broadcast Cluster
广播调用所有提供者,逐个调用,任意一台报错则报错。通常用于通知所有提供者更新缓存或日志等本地资源信息。
例子:
<dubbo:service cluster="failsafe" />
17、Dubbo有哪几种负载均衡策略,默认是哪种?
Random LoadBalance
- 随机,按权重设置随机概率(默认)。
- 在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重。
RoundRobin LoadBalance
- 轮询,按公约后的权重设置轮询比率。
- 存在慢的提供者累积请求的问题,比如:第二台机器很慢,但没挂,当请求调到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上。
LeastActive LoadBalance
- 最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差。
- 使慢的提供者收到更少请求,因为越慢的提供者的调用前后计数差会越大。
ConsistentHash LoadBalance
- 一致性 Hash,相同参数的请求总是发到同一提供者。
- 当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。
- 算法参见:http://en.wikipedia.org/wiki/Consistent_hashing
- 缺省只对第一个参数 Hash,如果要修改,请配置
<dubbo:parameter key="hash.arguments" value="0,1" /> - 缺省用 160 份虚拟节点,如果要修改,请配置
<dubbo:parameter key="hash.nodes" value="320" />
18、注册了多个同一样的服务,如果测试指定的某一个服务呢?
19、Dubbo支持服务多协议吗?
Dubbo 允许配置多协议,在不同服务上支持不同协议或者同一服务上同时支持多种协议。
20、当一个服务接口有多种实现时怎么做?
当一个接口有多种实现时,可以用 group 属性来分组,服务提供方和消费方都指定同一个 group 即可。
21、Dubbo服务之间的调用是阻塞的吗?
默认是同步等待结果阻塞的,支持异步调用。
Dubbo 是基于 NIO 的非阻塞实现并行调用,客户端不需要启动多线程即可完成并行调用多个远程服务,相对多线程开销较小,异步调用会返回一个 Future 对象。

Dubbo暂时不支持分布式事务。
22、Dubbo的管理控制台能做什么?
管理控制台主要包含:路由规则,动态配置,服务降级,访问控制,权重调整,负载均衡,等管理功能。
注:dubbo源码中的dubbo-admin模块打成war包,发布运行即可得到dubbo控制管理界面。
23、Dubbo 服务暴露的过程
Dubbo 会在 Spring 实例化完 bean 之后,在刷新容器最后一步发布 ContextRefreshEvent 事件的时候,通知实现了 ApplicationListener 的 ServiceBean 类进行回调 onApplicationEvent 事件方法,Dubbo 会在这个方法中调用 ServiceBean 父类 ServiceConfig 的 export 方法,而该方法真正实现了服务的(异步或者非异步)发布。
24、服务上线怎么兼容旧版本?
dubbo可实现灰度升级,可以用版本号(version)过渡,多个不同版本的服务注册到注册中心,版本号不同的服务相互间不引用。这个和服务分组的概念有一点类似。
25、出现调用超时com.alibaba.dubbo.remoting.TimeoutException异常怎么办?
通常是业务处理太慢,可在服务提供方执行:jstack PID > jstack.log 分析线程都卡在哪个方法调用上,这里就是慢的原因。
如果不能调优性能,请将timeout设大。
26、出现java.util.concurrent.RejectedExecutionException或者Thread pool exhausted怎么办?
1、RejectedExecutionException表示线程池已经达到最大值,并且没有空闲连,拒绝执行了一些任务。
2、Thread pool exhausted通常是min和max不一样大时,表示当前已创建的连接用完,进行了一次扩充,创建了新线程,但不影响运行。
原因可能是连接池不够用,请调整dubbo.properites中的:
// 设成一样大,减少线程池收缩开销
dubbo.service.min.thread.pool.size=200
dubbo.service.max.thread.pool.size=200
27、Dubbo可以对结果进行缓存吗?
可以,Dubbo 提供了声明式缓存,用于加速热门数据的访问速度,以减少用户加缓存的工作量。
28、Dubbo支持服务降级吗?
Dubbo 2.2.0 以上版本支持。
29、服务读写推荐的容错策略是怎样的?
读操作建议使用 Failover 失败自动切换,默认重试两次其他服务器。
写操作建议使用 Failfast 快速失败,发一次调用失败就立即报错
30、在使用过程中都遇到了些什么问题?
Dubbo 的设计目的是为了满足高并发小数据量的 rpc 调用,在大数据量下的性能表现并不好,建议使用 rmi 或 http 协议。
MYSQL调优----如何设置合理的数据库连接池的大小
一、前言
基本上来说,大部分项目都需要跟数据库做交互,那么,数据库连接池的大小设置成多大合适呢?
一些开发老鸟可能还会告诉你:没关系,尽量设置的大些,比如设置成 200,这样数据库性能会高些,吞吐量也会大些!
你也许会点头称是,真的是这样吗?看完这篇文章,也许会颠覆你的认知哦!
二、正菜开始
可以很直接的说,关于数据库连接池大小的设置,每个开发者都可能在一环节掉进坑里,事实上呢,大部分程序员可能都会依靠自己的直觉去设置它的大小,设置成 100 ?思量许久后,自顾自想,应该差不多吧?
三、假设你的服务有1万并发的访问
不妨意淫一下,你手里有个网站,并发压力虽然还没到 Facebook 那个级别,但是呢?也有个1万上下的并发量!也就是说差不多2万左右的 TPS。
那么问题来了!这个网站的数据库连接池应该设置成多大合适呢?
其实这个问法本身就是有问题的,我们需要反过来问,正确问法应该是:
“这个网站的数据库连接池应该设置成多小合适呢?”
PS: 这里有一个 Oracle 性能小组发布的简短视频,链接地址为 https://www.youtube.com/watch?v=xNDnVOCdvQ0,友情提示,需要科学上网才能访问哦!
口述一下,视频中对 Oracle 数据库进行了压力测试,模拟 9600 个并发线程来操作数据库,每两次数据库操作之间 sleep 550ms,注意,视频中刚开始设置的线程池大小为 2048。
让我们来看看数据库连接池的大小为 2048 性能测试结果的鬼样子:
每个请求要在连接池队列里等待 33ms,获得连接之后,执行SQL需要耗时77ms, CPU 消耗维持在 95% 左右;
接下来,我们将连接池的大小改小点,设置成 1024,其他测试参数不变,结果咋样?
“这里,获取连接等待时长基本不变,但是 SQL 的执行耗时降低了!”
哎呦,有长进哦!
接下来,我们再设置小些,连接池的大小降低到 96,并发数等其他参数不变,看看结果如何:
每个请求在连接池队列中的平均等待时间为 1ms, SQL 执行耗时为 2ms.
我去!什么鬼?
我们没调整任何东西,仅仅只是将数据库连接池的大小降低了,这样,就能把之前平均 100ms 响应时间缩短到了 3ms。吞吐量指数级上升啊!
你这也太溜了!
四、为啥有这种效果?
我们不妨想一下,为啥 Nginx 内部仅仅使用了 4 个线程,其性能就大大超越了 100 个进程的 Apache HTTPD 呢?追究其原因的话,回想一下计算机科学的基础知识,答案其实非常明显。
要知道,即使是单核 CPU 的计算机也能“同时”运行着数百个线程。但我们其实都知道,这只不过是操作系统快速切换时间片,跟我们玩的一个小把戏罢了。
一核 CPU同一时刻只能执行一个线程,然后操作系统切换上下文,CPU 核心快速调度,执行另一个线程的代码,不停反复,给我们造成了所有进程同时运行假象。
其实,在一核 CPU 的机器上,顺序执行A和B永远比通过时间分片切换“同时”执行A和B要快,其中原因,学过操作系统这门课程的童鞋应该很清楚。一旦线程的数量超过了 CPU 核心的数量,再增加线程数系统就只会更慢,而不是更快,因为这里涉及到上下文切换耗费的额外的性能。
说到这里,你应该恍然大悟了 ……
五、其他应该考虑到的因素
上小节中说到了主要原因,但其实没有这么简单,我们还需要考虑到一些其他的因素。
当我们在寻找数据库的性能瓶颈时,大致可归为三类:
- CPU
- 磁盘 IO
- 网络 IO
也许你会说,还有内存这一因素?内存的确是需要考虑的,但是比起磁盘IO和网络IO,稍显微不足道,这里就不加了。
假设我们不考虑磁盘 IO 和网络 IO,就很好定论了,在一个 8 核的服务器上,数据库连接数/线程数设置为 8 能够提供最优的性能,如果再增加连接数,反而会因为上下文切换导致性能下降。
大家都知道,数据库通常把数据存储在磁盘上,而磁盘呢,通常是由一些旋转着的金属碟片和一个装在步进马达上的读写头组成的。读/写头同一时刻只能出现在一个位置,当它需要再次执行读写操作时,它必须“寻址”到另外一个位置才能完成任务。所以呢?这里就有了寻址的耗时,此外还有旋转耗时,读写头需要等待磁盘碟片上的目标数据“旋转到位”才能进行读写操作。使用缓存当然是能够提升性能的,但上述原理仍然适用。
在这段(”I/O等待”)时间内,线程是处于“阻塞”等待状态,也就是说没干啥正事!此时操作系统可以将这个空闲的CPU 核心用于服务其他线程。
这里我们可以总结一下,当你的线程处理的是 I/O 密集型业务时,便可以让线程/连接数设置的比 CPU核心大一些,这样就能够在同样的时间内,完成更多的工作,提升吞吐量。
那么问题又来了?
大小设置成多少合适呢?
这要取决于磁盘,如果你使用的是 SSD 固态硬盘,它不需要寻址,也不需要旋转碟片。打住打住!!!你千万可别理所当然的认为:“既然SSD速度更快,我们把线程数的大小设置的大些吧!!”
结论正好相反!无需寻址和没有旋回耗时的确意味着更少的阻塞,所以更少的线程(更接近于CPU核心数)会发挥出更高的性能。只有当阻塞密集时,更多的线程数才能发挥出更好的性能。
上面我们已经说过了磁盘 IO, 接下来我们谈谈网络 IO!
网络 IO 其实也是非常相似的。通过以太网接口读写数据时也会造成阻塞,10G带宽会比1G带宽的阻塞耗时少一些,而 1G 带宽又会比 100M 带宽的阻塞少一些。通常情况下,我们把网络 IO 放在第三顺位来考虑,然而有些人会在性能计算中忽略网络 IO 带来的影响。
上图是 PostgreSQL 的基准性能测试数据,从图中我们可以看到,TPS 在连接数达到 50 时开始变缓。回过头来想下,在上面 Oracle 的性能测试视频中,测试人员们将连接数从 2048 降到了 96,实际上 96 还是太高了,除非你的服务器 CPU 核心数有 16 或 32。
六、连接数计算公式
下面公式由 PostgreSQL 提供,不过底层原理是不变的,它适用于市面上绝大部分数据库产品。还有,你应该模拟预期的访问量,并通过下面的公式先设置一个偏合理的值,然后在实际的测试中,通过微调,来寻找最合适的连接数大小。
连接数 = ((核心数 * 2) + 有效磁盘数)
核心数不应包含超线程(hyper thread),即使打开了超线程也是如此,如果热点数据全被缓存了,那么有效磁盘数实际是0,随着缓存命中率的下降,有效磁盘数也逐渐趋近于实际的磁盘数。另外需要注意,这一公式作用于SSD 的效果如何,尚未明了。
好了,按照这个公式,如果说你的服务器 CPU 是 4核 i7 的,连接池大小应该为 ((4*2)+1)=9。
取个整, 我们就设置为 10 吧。你这个行不行啊?10 也太小了吧!
你要是觉得不太行的话,可以跑个性能测试看看,我们可以保证,它能轻松支撑 3000 用户以 6000 TPS 的速率并发执行简单查询的场景。你还可以将连接池大小超过 10,那时,你会看到响应时长开始增加,TPS 开始下降。
七、结论:你需要的是一个小连接池,和一个等待连接的线程队列
假设说你有 10000 个并发访问,而你设置了连接池大小为 10000,你怕是石乐志哦。
改成 1000,太高?改成 100?还是太多了。
你仅仅需要一个大小为 10 数据库连接池,然后让剩下的业务线程都在队列里等待就可以了。
连接池中的连接数量大小应该设置成:数据库能够有效同时进行的查询任务数(通常情况下来说不会高于 2*CPU核心数)。
你应该经常会看到一些用户量不是很大的 web 应用中,为应付大约十来个的并发,却将数据库连接池设置成 100, 200 的情况。请不要过度配置您的数据库连接池的大小。
八、额外需要注意的点
实际上,连接池的大小的设置还是要结合实际的业务场景来说事。
比如说,你的系统同时混合了长事务和短事务,这时,根据上面的公式来计算就很难办了。正确的做法应该是创建两个连接池,一个服务于长事务,一个服务于”实时”查询,也就是短事务。
还有一种情况,比方说一个系统执行一个任务队列,业务上要求同一时间内只允许执行一定数量的任务,这时,我们就应该让并发任务数去适配连接池连接数,而不是连接数大小去适配并发任务数。
Ref
https://github.com/brettwooldridge/HikariCP/wiki/About-Pool-Sizing
339 post articles, 43 pages.