eureka中的核心参数
eureka中的核心参数:
client端核心参数:
eureka:
client:
##=========>基本参数<============
#告知Client有哪些region和availability-zones,支持配置修改运行时生效
availability-zones: null
#是否过滤出注册到eureka中所有InstanceStatus为UP的实例,默认为true
filter-only-up-instances: true
#是否将该实例注册到 eureka server,eureka注册中心配置为false,不把自身注册到eureka
register-with-eureka: true
#是否优先使用与该实例处于相同zone的Eureka server ,默认为true,
#即默认会使用与实力处于相同zone的server,如果找不到,才会默认使用defaultZone中配置的
prefer-same-zone-eureka: true
#是否将本地实例状态通过ApplicationInfoManager实时同步到到Eureka Server中,默认是true,一般情况下不要改,默认就行
on-demand-update-status-change: true
##=========>定时任务参数<============
#指定用于刷新缓存的CacheRefreshThread的线程池大小,默认是2个
cache-refresh-executor-thread-pool-size: 2
#调度任务执行超时时,下次再次执行的延时时间
cache-refresh-executor-exponential-back-off-bound: 12
#发送心跳线程的线程池大小
heartbeat-executor-thread-pool-size: 3
#CacherefreshThread线程的调度频率,eureka默认30秒刷新一次缓存
registry-fetch-interval-seconds: 30
#刷新Eureka Server地址的时间间隔
eureka-service-url-poll-interval-seconds: 300
#instanceInfoReplication将实例信息变更同步到Eureka Server的初始延时时间,默认40秒
initial-instance-info-replication-interval-seconds: 40
#InstanceInfoReplication将实例信息变更同步到Eureka Server的时间间隔
instance-info-replication-interval-seconds: 30
##=========>http参数<============
#连接server的超时时间 默认5秒
eureka-server-connect-timeout-seconds: 5
#client 从server读取数据超时时间,默认8秒
eureka-server-read-timeout-seconds: 8
#连接池最大的活动链接数 最大默认200个连接数
eureka-server-total-connections: 200
#每个host能使用的最大连接数 ,默认每个主机最多只能使用50个练级
eureka-server-total-connections-per-host: 50
#连接池中连接的空闲时间
eureka-connection-idle-timeout-seconds: 30
instance:
##=========>基本参数<============
#指定该应用实例的元数据信息
metadata-map:
#是否优先使用IP地址来代替host name作为市里的hostname字段值,默认是false
prefer-ip-address: false
#指定Eureka Client间隔多久向Eureka Server发送心跳来告知Eureka Server该实例还存活,默认是90秒
lease-expiration-duration-in-seconds: 30
##=========>定时任务参数<============
#Eureka Client向Server发送心跳的时间间隔,默认CLient隔30秒就会向Server发送一次心跳
lease-renewal-interval-in-seconds: 30
Server端参数
eureka:
server:
##=========>基本参数<============
#是否开启自我保护模式,默认是开启的
enable-self-preservation: true
#每分钟需要收到的续约次数的阈值 server会根据某个应用注册时实例数,计算每分钟应收到的续约次数
#若收到的次数少于该阈值,server会关闭该租约,并禁止定时任务剔除失效的实例,保护注册信息
renewal-percent-threshold: 0.85
#指定updateRenewalThreshold定时任务的调度频率,来动态更新expectedNumberOfRenewsPerMin和numberOfRenewsPerMinThreshold值
renewal-threshold-update-interval-ms: 15
#指定EvictionTask定时任务的调度频率,用于剔除过期的实例,默认是60秒执行一次
eviction-interval-timer-in-ms: 60000
##=========>response cache参数<============
#是否使用只读的response-cache,默认是使用
use-read-only-response-cache: true
#设置CacheUpdateTask的调度时间间隔,用于从readWriteCacheMap更新数据到readOnlyCacheMap
#仅在use-read-only-response-cache设置为true是才生效
response-cache-update-interval-ms: 30000
#设置readWriteCacheMap的expireAfterWrite参数,指定写入多长时间后,cache过期
response-cache-auto-expiration-in-seconds: 180
##=========>peer参数 eureka server节点间同步数据的配置<============
#指定peerUpdateTask调度的时间间隔,
#用于从配置文件刷新peerEurekaNodes节点之间的配置信息(eureka.client.serviceUrl相关的zone的配置)
#默认10分钟
peer-eureka-nodes-update-interval-ms: 10
#指定更新peer node状态的时间间隔,默认30秒更新各node间的状态信息
peer-eureka-status-refresh-time-interval-ms: 30000
##=========>http参数<============
#server各node间连接超时时长,默认200毫秒,200毫秒没连接上server的其他节点,就会认为该node不可用
peer-node-connect-timeout-ms: 200
#从其他节点读取数据超时时间 ,默认200毫秒
peer-node-read-timeout-ms: 200
#server的单个node连接池最大的活动连接数
peer-node-total-connections: 1000
#server的单个node每个hot能使用的最大连接数
peer-node-total-connections-per-host: 500
#server的node连接池连接的空闲时间
peer-node-connection-idle-timeout-seconds: 30
instance:
registry:
##=========>基本参数<============
#指定每分钟需要收到的续约次数值,实际该值被写死为实例值*2
expected-number-of-clients-sending-renews: 1
参数调优
一般最简单常见的问题有这几个:
- 服务下线了,为什么还能调通接口
- 服务注册了,Client不能及时获取到
- 自我保护机制。
解决办法
- 因为Eureka不是强一致性的,因此registry中会有过期的实例信息,实例过期有以下原因
- 应用实例异常挂掉,在挂掉之前没来得及通知Eureka Server要下线掉自己这个实例。这个要Eureka的 EvicitionTask去剔除了
- 剔除可以人工手动请求剔除
- 在yml配置文件中,可以配置剔除时间间隔,可以调小一些
- 应用实例下线时有通知Server下线自己这个实例,但是由于Server 的API有启用readOnlyCache,所以需要等 待缓存过期才能更新
- 缓存可以开启和关闭,关闭久不存在这个问题
- 在开启情况下,也可以设置更新缓存的时间
- 由于Server开启了自我保护机制,导致registry不能因过期而剔除 针对Client下线,没来得及通知server,可以调整EvictionTask的调度频率,加快剔除过期实例的频率
- 针对responseCache问题,可以根据实际情况关机readOnlyCacheMap,或者调整readWriteCacheMap的过期时间,缩短点cache过期时间
- 应用实例异常挂掉,在挂掉之前没来得及通知Eureka Server要下线掉自己这个实例。这个要Eureka的 EvicitionTask去剔除了
针对自我保护机制,测试环境可以适当选择关闭自我保护机制。但是有时候,由于网络问题,Client的续约未能如期保持,但是服务本身是健康的,这个时候按照租约机制剔除的话,会造成误判。可以选择适当的调低触发自我保护机制的阈值,或者调低client向Server发送心跳的时间间隔
针对服务上线了,Client不能及时获取到,可以适当提高Client获取Server注册信息的频率,如将30秒改为5秒
eureka-server
eureka-server知识点
注册,下线,心跳,剔除,拉取注册表,集群同步
生产环境相应优化
eureka-server 优化指导
-
优化目的:减少服务上下线的延时
-
自我保护的选择:看网络和服务情况
-
服务更新:停止,在发送线下请求
server: # enable-replicated-request-compression: false #关闭自我保护 renewal-percent-threshold: 0.85 # 在开启的情况下,设置自我保护阀值 eviction-interval-timer-in-ms: 1000 # 踢除服务毫秒数,如果其他服务在1秒内拉取服务,还是能拉取的,包括不可用的服务 use-read-only-response-cache: true # 关闭eureka 三级缓存 在高并发下可以更快速的读取数据 response-cache-update-interval-ms: 1000 # 开启的情况下,提高服务被发现的速度
client配置总结
-
刷新注册(拉取注册表)间隔
-
心跳间隔
client: # 针对新服务上线, Eureka client获取不及时的问题,在测试环境,可以适当提高Client端拉取Server注册信息的频率,默认:30秒 registry-fetch-interval-seconds: 30 instance: lease-renewal-interval-in-seconds: 30 # 再续约时间 -
实际工作中service-ul:打乱配置,不要所有的服务都写一样顺序的配置
某一台连接eureka的客户端:defaultZone: http://localhost:7900/eureka/,http://localhost:7901/eureka/,http://localhost:7902/eureka/ 另一台连接eureka的客户端:defaultZone: http://localhost:7901/eureka/,http://localhost:7900/eureka/,http://localhost:7902/eureka/ -
多个eureka之间要互相注册,才能互相通信同步信息
```yml spring: application: name: cloud-eureka eureka: instance: # prefer-ip-address: true # ip-address: 127.0.0.1
client: register-with-eureka: true # false 禁止自己当做服务注册 fetch-registry: true # false #屏蔽注册信息 service-url: # 5 24 defaultZone: http://eureka-7900:7900/eureka/,http://eureka-7901:7901/eureka/,http://eureka-7902:7902/eureka/ #, server: # 自我保护看自己情况 enable-self-preservation: true # 续约阈值,和自我保护相关 renewal-percent-threshold: 0.85 # server剔除过期服务的时间间隔 eviction-interval-timer-in-ms: 1000 # 是否开启readOnly读缓存 use-read-only-response-cache: true # 关闭 readOnly response-cache-update-interval-ms: 1000
spring: profiles: 7900 server: port: 7900 eureka: instance: hostname: eureka-7900 client: register-with-eureka: true fetch-registry: true service-url: # 5 24 互相注册 defaultZone: http://eureka-7900:7901/eureka/,http://eureka-7900:7902/eureka/
spring: profiles: 7901 server: port: 7901 eureka: instance: hostname: eureka-7901 client: register-with-eureka: true fetch-registry: true service-url: # 5 24 互相注册 defaultZone: http://eureka-7900:7900/eureka/,http://eureka-7900:7902/eureka/ — spring: profiles: 7902 server: port: 7902 eureka: instance: hostname: eureka-7902 client: register-with-eureka: true fetch-registry: true service-url: # 5 24 互相注册 defaultZone: http://eureka-7900:7900/eureka/,http://eureka-7900:7901/eureka/
### eureka
#### cap
- 三级缓存
```xml
use-read-only-response-cache: false # 关闭eureka 三级缓存 在高并发下可以更快速的读取数据
-
从其他peer拉取注册表,peer
- p:网络不好的情况下,还是可以拉取到注册表进行调用的,服务还可以调用
自我保护剔除(*eureka优化)
-
eureka会定期的将没有心跳的服务剔除
eviction-interval-timer-in-ms: 1000 # 踢除服务毫秒数,如果其他服务在1秒内拉取服务,还是能拉取的,包括不可用的服务 -
开关
enable-replicated-request-compression: false #关闭自我保护 -
阀值
renewal-percent-threshold: 0.85 # 在开启的情况下,设置自我保护阀值 eviction-interval-timer-in-ms: 1000 # 踢除服务毫秒数,如果其他服务在1秒内拉取服务,还是能拉取的,包括不可用的服务 -
推荐: 服务少不开自我保护,服务多开自我保护
- 当服务少时,开了自我保护,当其中一个服务不能使用,请求依然会指向不可用的服务
- 当服务多时,开启自我保护,因为服务集群够多,请求到不能使用的服务将会被路由的其他可用的服务,所以可以里面重启会在让不可以服务变为空用即可,比如网络抖动不用了,就没必要提出
- 服务即时感知
- 上线感知
- 下线感知
- 缓存问题
- 写度
- 滥用缓存
- 服务滞后时间
- 分布式事务
- 服务注册
- 服务向eureka注册,发送心跳,下线,服务向eureka拉取注册表
- 集群同步
- 服务发现
- 另一个服务也向eureka拉去注册表,拉去完之后,两个服务之间就可以互相调用
- Cap 在eureka中为什么只有ap
- C表示强一致性,而eureka 做不到
- 当新的eureka启动的时候,会触发拉取久的eureka的注册表,在在这个时候如果有新的服务向久的eureka发起注册,新的eureka时获取不到新的服务的信息的
- 服务测算
- 20个服务,每个服务部署5个,则eureka lient 连接100个
- 默认30发起一次 renewal 再续时间,即1分钟200次心跳
- 一天差不多几十万次心跳,即 eureka每天能承受多大的访问量
-
相应的可以选择对应能承受该心跳次数的硬件
- eureka 使用guava 做缓存
-
实际应用中可通过 guava 做一些 集合+时间 的一些业务,比如做限流
- 验证参数可以通过 validata实现,可以减少if else 的使用
- CAP原则
- 一致性、可用性和分区容错性,其中最多只能同时满是两个,而大多数情况下时满是AP,可用性(集群解决单点故障),容错性(),一致性都是通过最终一致性
| 序号 | 被抛弃的谁 | 说明 |
|---|---|---|
| 1 | 放弃P,满足AC | 将数据和服务都放在一个节点上,避免因网络引起的负面影响, 充分保证系统的可用性和一致性。但放弃P意味着放弃了系统的可扩展性 |
| 2 | 放弃A,满足PC | 当节点故障或者网络故障时,受到影响的服务需要等待一定的世 界,因此在等待时间里,系统无法对外提供正常服务,因此是不可用的 |
| 3 | 放弃C,满足AP | 系统无法保证数据的实时一致性,但是承诺数据最终会保证一致 性。因此存在数据不一致的窗口期,至于窗口期的长短取决于系统的设计 |
面试题
- 生产环境中,服务重启时,先停服,在手动出发下线
设计模式
| 设计模式 | 典型应用 | 框架中的应用 |
|---|---|---|
| 工厂方法 | 适合在单个产品上做纬度扩展 | |
| 抽象工厂 | 适合在产品族的纬度上扩展 | bean工厂 |
| Mediator 调节模式 | 消息中间件(内部之间调和)(居委会大妈) | mq |
| Facade 门面模式 | 将复杂的服务整合,当用户访问后,可以通过简单的方式访问到复杂的服务(包工头) | |
| 责任链模式 | 需要用状态来确定责任是否完成,通常需要用boolean来确定 | Filter Interceptor,Filter中FilterChain负责调用的顺序,里面是一个递归的方法 |
| Observer观察者 | 事件处理模型 | |
| Decorator装饰器 | 顾名思义,就是在原来的基础上在加一层装饰,装饰的类和被装饰的类都可以横向扩展(在开发的时候,就是类在继承,而方法在嵌套) | 在IO流中,比如Reader 包含InputStream |
| *观察者模式Observer | 观察者很少和事件源打交道,主要是和事件打交道,和Listener,hook function,callback function 都是观察者 | 很多系统中,Observer模式往往和负责责任链共同负责对于事件的处理,其中某一个observer负责是否将事件进一步传递 |
| 组合Composite | 树状结构专用模式 | 可用于导航栏 |
| 享元Flyweight | 重复利用对象,共享元数据,有池化的概念 | String 就是这个模式,使用的时候 可以和组合模式一起使用 |
| 代理模式 | 静态代理,动态代理,springAop,代理也实现被代理类的接口,并在代理类中将接口类作为成员变量 | 有点类似 Decorator jdk实现的动态代理需要 实体类实现了接口 cglib可以对任何类进行动态代理 |
| *Iteratror迭代器 | 容器,容器遍历 | 其实就是多态的一个应用 |
| Visitor访问者 | 在结构不变的情况下动态改变对于内部元素的动作 | |
| ASM | Iteratror+Visitor+chainfresposibility | |
| builder | 构建复杂的对象 | 链式编程(在类的众多参数中,你只需要其中的一些时候,使用该模式,看代码) |
| Adapter(Wrapper) | 接口转换器 | 相当于插线板的转接头一样,加一层 |
| Bridge | 双纬度扩展 | 分离抽象和具体 |
| Command | 封装命令(doit和undo方法) | 别名:Action/Transaction |
| Prototype原型模式/克隆模式 | Object.clone() Object 自带clone模式 | 有浅克隆和深克隆区分 |
| Memento备忘录 | 记录状态便于回滚 | 记录快照(瞬时状态),存盘,使用File做序列化时,使用transient 表示透明的,不需要存盘,需要存盘的都需要实现序列化接口,或者父类实现序列化接口,在网络传输中序列化通常使用google的ProtoBuf |
| TemplateMethod模版方法(钩子函数) | ||
| State状态模式 | 根据状态决定行为 | |
| Intepreter解析器 | 动态脚本解析 |
记住典型的用法和类图
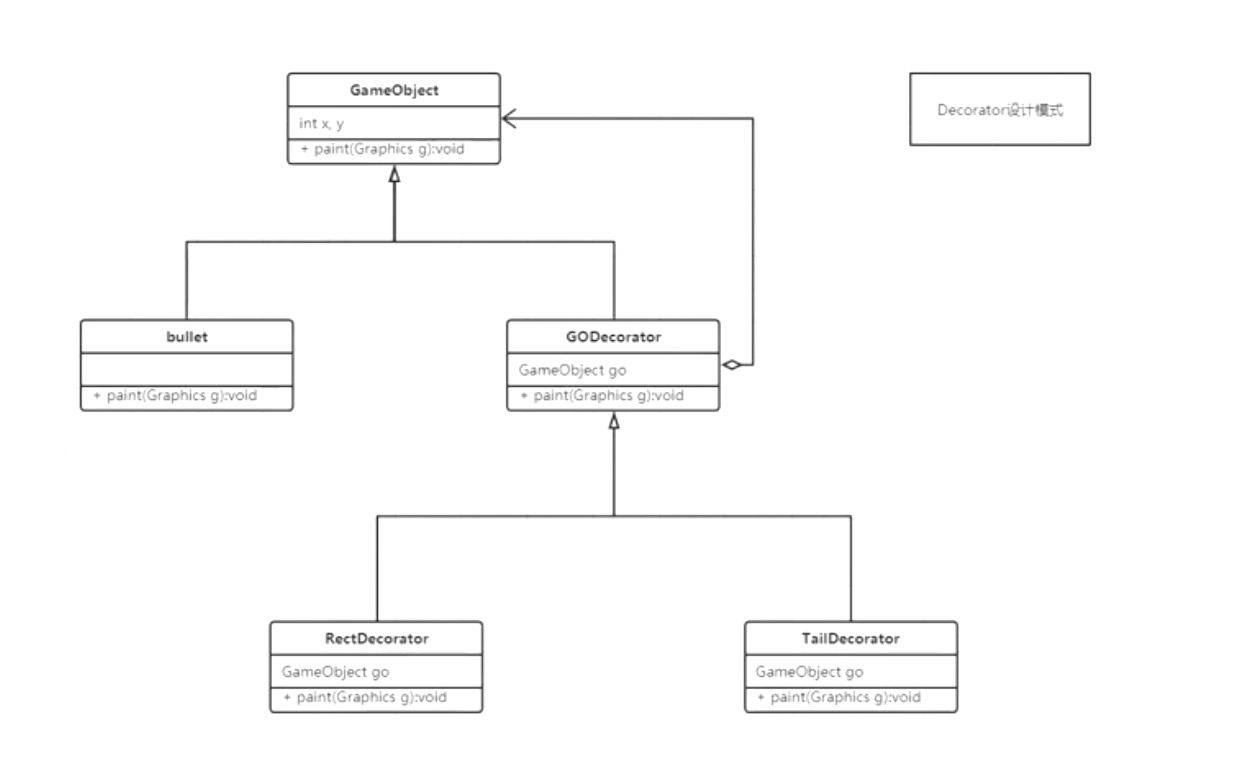
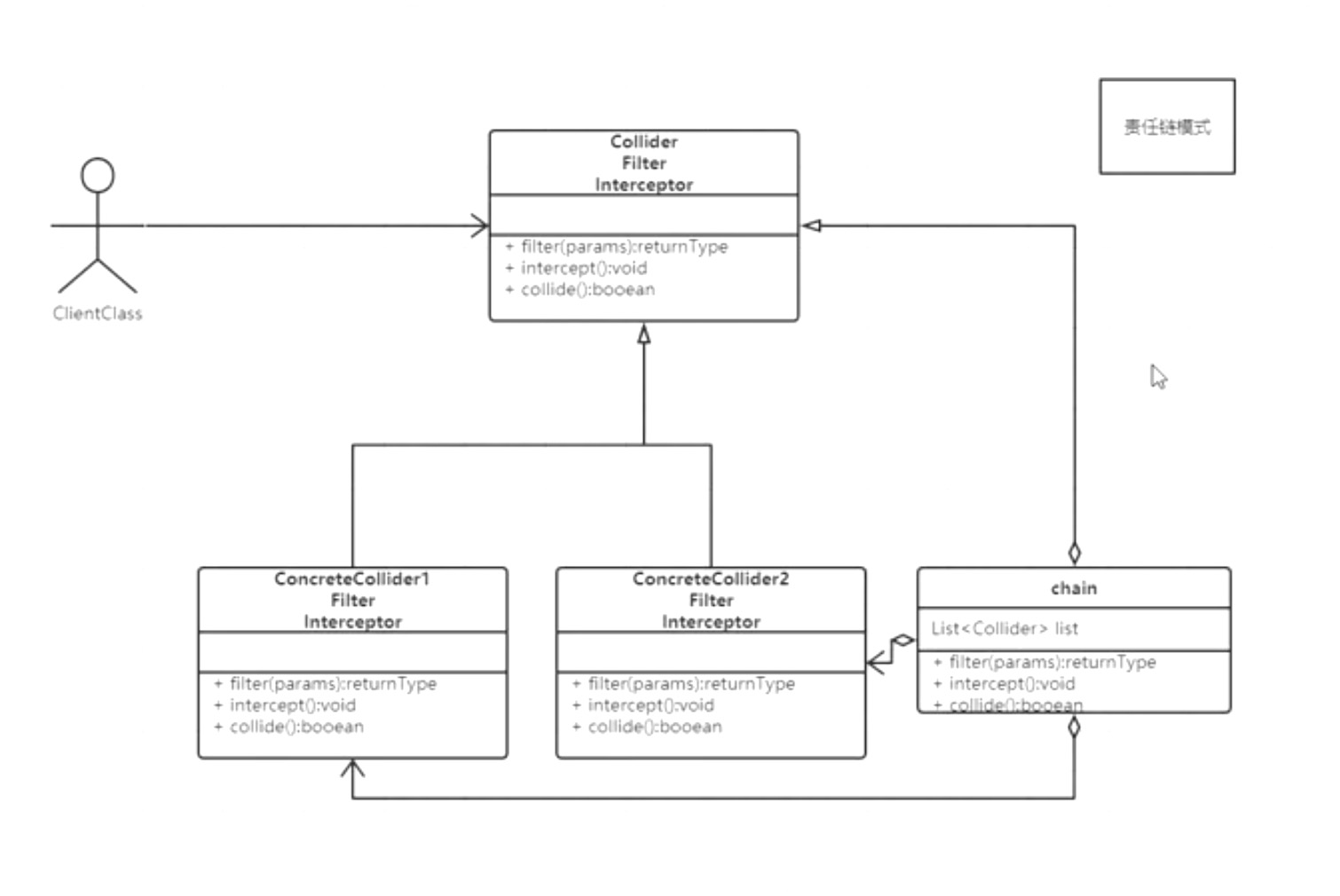
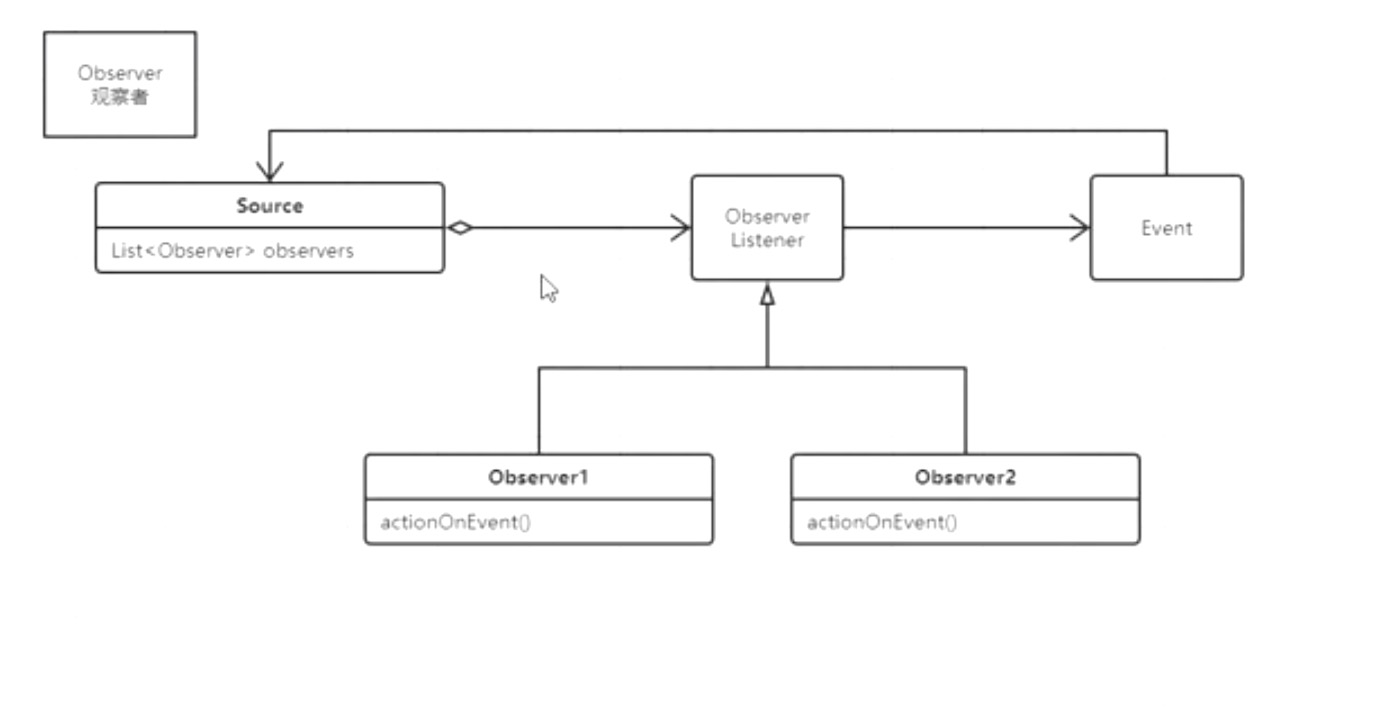

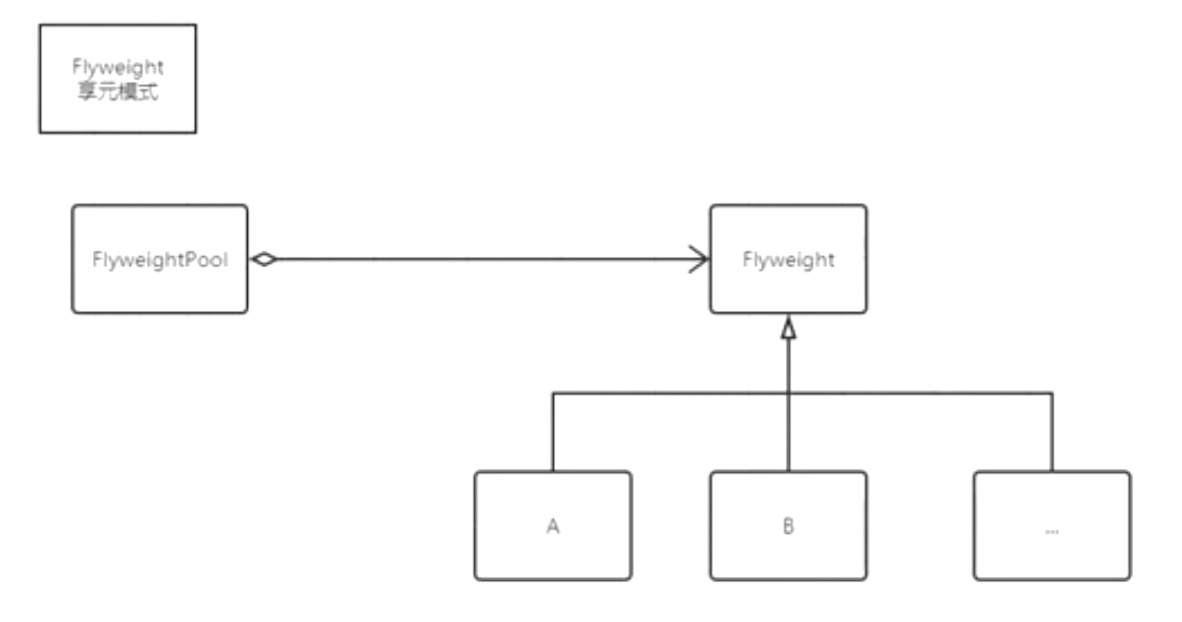
静态代理
/**
* 问题:我想记录坦克的移动时间
* 最简单的办法:修改代码,记录时间
* 问题2:如果无法改变方法源码呢?
* 用继承?
* v05:使用代理
* v06:代理有各种类型
* 问题:如何实现代理的各种组合?继承?Decorator?
* v07:代理的对象改成Movable类型-越来越像decorator了
*
*/
public class Tank implements Movable {
/**
* 模拟坦克移动了一段儿时间
*/
@Override
public void move() {
System.out.println("Tank moving claclacla...");
try {
Thread.sleep(new Random().nextInt(10000));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
Tank t = new Tank();
TankTimeProxy ttp = new TankTimeProxy(t);
TankLogProxy tlp = new TankLogProxy(ttp);
tlp.move();
// new TankLogProxy(
// new TankTimeProxy(
// new Tank()
// )
// ).move();
}
}
class TankTimeProxy implements Movable {
Movable m;
public TankTimeProxy(Movable m) {
this.m = m;
}
@Override
public void move() {
long start = System.currentTimeMillis();
m.move();
long end = System.currentTimeMillis();
System.out.println(end - start);
}
}
class TankLogProxy implements Movable {
Movable m;
public TankLogProxy(Movable m) {
this.m = m;
}
@Override
public void move() {
System.out.println("start moving...");
m.move();
long end = System.currentTimeMillis();
System.out.println("stopped!");
}
}
interface Movable {
void move();
}
动态代理
/**
* 问题:我想记录坦克的移动时间
* 最简单的办法:修改代码,记录时间
* 问题2:如果无法改变方法源码呢?
* 用继承?
* v05:使用代理
* v06:代理有各种类型
* 问题:如何实现代理的各种组合?继承?Decorator?
* v07:代理的对象改成Movable类型-越来越像decorator了
* v08:如果有stop方法需要代理...
* 如果想让LogProxy可以重用,不仅可以代理Tank,还可以代理任何其他可以代理的类型
* (毕竟日志记录,时间计算是很多方法都需要的东西),这时该怎么做呢?
* 分离代理行为与被代理对象
* 使用jdk的动态代理
*
* v09: 横切代码与业务逻辑代码分离 AOP
* v10: 通过反射观察生成的代理对象
* jdk反射生成代理必须面向接口,这是由Proxy的内部实现决定的
*/
public class Tank implements Movable {
/**
* 模拟坦克移动了一段儿时间
*/
@Override
public void move() {
System.out.println("Tank moving claclacla...");
try {
Thread.sleep(new Random().nextInt(10000));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
Tank tank = new Tank();
System.getProperties().put("jdk.proxy.ProxyGenerator.saveGeneratedFiles","true");
Movable m = (Movable)Proxy.newProxyInstance(Tank.class.getClassLoader(),
new Class[]{Movable.class}, //tank.class.getInterfaces()
new TimeProxy(tank)
);
m.move();
}
}
class TimeProxy implements InvocationHandler {
Movable m;
public TimeProxy(Movable m) {
this.m = m;
}
public void before() {
System.out.println("method start..");
}
public void after() {
System.out.println("method stop..");
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//Arrays.stream(proxy.getClass().getMethods()).map(Method::getName).forEach(System.out::println);
before();
Object o = method.invoke(m, args);
after();
return o;
}
}
interface Movable {
void move();
}
链式编程 builder模式
public class Person {
int id;
String name;
int age;
double weight;
int score;
Location loc;
private Person() {}
public static class PersonBuilder {
Person p = new Person();
public PersonBuilder basicInfo(int id, String name, int age) {
p.id = id;
p.name = name;
p.age = age;
return this;
}
public PersonBuilder weight(double weight) {
p.weight = weight;
return this;
}
public PersonBuilder score(int score) {
p.score = score;
return this;
}
public PersonBuilder loc(String street, String roomNo) {
p.loc = new Location(street, roomNo);
return this;
}
public Person build() {
return p;
}
}
public static void main(String[] args) {
Person p = new Person.PersonBuilder()
.basicInfo(1, "zhangsan", 18)
//.score(20)
.weight(200)
//.loc("bj", "23")
.build();
}
}
class Location {
String street;
String roomNo;
public Location(String street, String roomNo) {
this.street = street;
this.roomNo = roomNo;
}
}
ThreadPoolExecutor源码解析
#
1、常用变量的解释
// 1. `ctl`,可以看做一个int类型的数字,高3位表示线程池状态,低29位表示worker数量
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// 2. `COUNT_BITS`,`Integer.SIZE`为32,所以`COUNT_BITS`为29
private static final int COUNT_BITS = Integer.SIZE - 3;
// 3. `CAPACITY`,线程池允许的最大线程数。1左移29位,然后减1,即为 2^29 - 1
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
// 4. 线程池有5种状态,按大小排序如下:RUNNING < SHUTDOWN < STOP < TIDYING < TERMINATED
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// Packing and unpacking ctl
// 5. `runStateOf()`,获取线程池状态,通过按位与操作,低29位将全部变成0
private static int runStateOf(int c) { return c & ~CAPACITY; }
// 6. `workerCountOf()`,获取线程池worker数量,通过按位与操作,高3位将全部变成0
private static int workerCountOf(int c) { return c & CAPACITY; }
// 7. `ctlOf()`,根据线程池状态和线程池worker数量,生成ctl值
private static int ctlOf(int rs, int wc) { return rs | wc; }
/*
* Bit field accessors that don't require unpacking ctl.
* These depend on the bit layout and on workerCount being never negative.
*/
// 8. `runStateLessThan()`,线程池状态小于xx
private static boolean runStateLessThan(int c, int s) {
return c < s;
}
// 9. `runStateAtLeast()`,线程池状态大于等于xx
private static boolean runStateAtLeast(int c, int s) {
return c >= s;
}
2、构造方法
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
// 基本类型参数校验
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
// 空指针校验
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
// 根据传入参数`unit`和`keepAliveTime`,将存活时间转换为纳秒存到变量`keepAliveTime `中
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
3、提交执行task的过程
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
// worker数量比核心线程数小,直接创建worker执行任务
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
// worker数量超过核心线程数,任务直接进入队列
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 线程池状态不是RUNNING状态,说明执行过shutdown命令,需要对新加入的任务执行reject()操作。
// 这儿为什么需要recheck,是因为任务入队列前后,线程池的状态可能会发生变化。
if (! isRunning(recheck) && remove(command))
reject(command);
// 这儿为什么需要判断0值,主要是在线程池构造方法中,核心线程数允许为0
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 如果线程池不是运行状态,或者任务进入队列失败,则尝试创建worker执行任务。
// 这儿有3点需要注意:
// 1. 线程池不是运行状态时,addWorker内部会判断线程池状态
// 2. addWorker第2个参数表示是否创建核心线程
// 3. addWorker返回false,则说明任务执行失败,需要执行reject操作
else if (!addWorker(command, false))
reject(command);
}
4、addworker源码解析
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
// 外层自旋
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// 这个条件写得比较难懂,我对其进行了调整,和下面的条件等价
// (rs > SHUTDOWN) ||
// (rs == SHUTDOWN && firstTask != null) ||
// (rs == SHUTDOWN && workQueue.isEmpty())
// 1. 线程池状态大于SHUTDOWN时,直接返回false
// 2. 线程池状态等于SHUTDOWN,且firstTask不为null,直接返回false
// 3. 线程池状态等于SHUTDOWN,且队列为空,直接返回false
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
// 内层自旋
for (;;) {
int wc = workerCountOf(c);
// worker数量超过容量,直接返回false
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// 使用CAS的方式增加worker数量。
// 若增加成功,则直接跳出外层循环进入到第二部分
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
// 线程池状态发生变化,对外层循环进行自旋
if (runStateOf(c) != rs)
continue retry;
// 其他情况,直接内层循环进行自旋即可
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
// worker的添加必须是串行的,因此需要加锁
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
// 这儿需要重新检查线程池状态
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
// worker已经调用过了start()方法,则不再创建worker
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
// worker创建并添加到workers成功
workers.add(w);
// 更新`largestPoolSize`变量
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
// 启动worker线程
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
// worker线程启动失败,说明线程池状态发生了变化(关闭操作被执行),需要进行shutdown相关操作
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
5、线程池worker任务单元
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
/**
* This class will never be serialized, but we provide a
* serialVersionUID to suppress a javac warning.
*/
private static final long serialVersionUID = 6138294804551838833L;
/** Thread this worker is running in. Null if factory fails. */
final Thread thread;
/** Initial task to run. Possibly null. */
Runnable firstTask;
/** Per-thread task counter */
volatile long completedTasks;
/**
* Creates with given first task and thread from ThreadFactory.
* @param firstTask the first task (null if none)
*/
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
// 这儿是Worker的关键所在,使用了线程工厂创建了一个线程。传入的参数为当前worker
this.thread = getThreadFactory().newThread(this);
}
/** Delegates main run loop to outer runWorker */
public void run() {
runWorker(this);
}
// 省略代码...
}
6、核心线程执行逻辑-runworker
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
// 调用unlock()是为了让外部可以中断
w.unlock(); // allow interrupts
// 这个变量用于判断是否进入过自旋(while循环)
boolean completedAbruptly = true;
try {
// 这儿是自旋
// 1. 如果firstTask不为null,则执行firstTask;
// 2. 如果firstTask为null,则调用getTask()从队列获取任务。
// 3. 阻塞队列的特性就是:当队列为空时,当前线程会被阻塞等待
while (task != null || (task = getTask()) != null) {
// 这儿对worker进行加锁,是为了达到下面的目的
// 1. 降低锁范围,提升性能
// 2. 保证每个worker执行的任务是串行的
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
// 如果线程池正在停止,则对当前线程进行中断操作
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
// 执行任务,且在执行前后通过`beforeExecute()`和`afterExecute()`来扩展其功能。
// 这两个方法在当前类里面为空实现。
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
// 帮助gc
task = null;
// 已完成任务数加一
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
// 自旋操作被退出,说明线程池正在结束
processWorkerExit(w, completedAbruptly);
}
}
Servlet的多线程 和 Servlet线程安全
JSP/Servlet的多线程原理:
- 1.servelet就是一个CGI,但比传统的CGI要快得过
传统CGI是多进程的,servlet是多线程的 以多线程方式执行可大大降低对系统的资源需求,提高 系统的并发量及响应时间.
- JSP/Servlet容器默认是采用单实例多线程(这是造成线程安全的主因)方式处理多个请求的:
当客户端第一次请求某一个JSP文件时(有的servlet是随容器启动就startup):
- 服务端把该JSP编译成一个CLASS文件
- 并创建一个该类的实例
- 然后创建一个线程处理CLIENT端的请求。
- 多请求,多线程:
如果有多个客户端同时请求该JSP文件,则服务端会创建多个线程。每个客户端请求对应一个线程。
servlet 的线程安全
- servlet里的 实例变量
servlet里的实例变量,是被所有线程共享的,所以不是线程安全的.
- servlet方法里的局部变量
因为每个线程都有它自己的堆栈空间,方法内局部变量存储在这个线程堆栈空间内, 且参数传入方法是按传值volue copy的方式 所以是线程安全的
- Application对象
在container运行期间,被整个系统内所有用户共同使用,所以不是线程安全 的
- ServletContext对象
ServletContext是可以多线程同时读/写属性的,线程是不安全的。 struts2 的ServletContext采用的是TreadLocal模式,是线程安全的
- HttpServletRequest对象和HttpServletResponse对象
每一个请求,由一个工作线程来执行,都会创建有一对新的ServletRequest对象和ServletResponse,然后传入service()方法内 所以每个ServletRequest对象对应每个线程,而不是多线程共享,是线程安全的。所以不用担心request参数和属性的线程安全性
- HttpSession
Session对象在用户session期间存在,只能在属于同一个SessionID的请求的线程中被访问,因此Session对象的理论上是线程安全的。 (当用户打开多个同属于一个进程的浏览器窗口(常见的弹出窗口),在这些窗口的访问属于同一个Session,会出现多次请求,需要多个工作线程来处理请求,这时就有可能的出现线程安全问题)
servlet 尽量用方法内变量,就一定线程安全么? 局部变量的数据也来自request对象或session对象啊,它们线程安全么? servletRequest 线程是安全的 因为:每个 request 都会创建一个新线程,每个新线程,容器又都会创建一对servletRequest和servletResponse对象(这是servlet基本原理) 所以servletRequest对象和servletResponse对象只在一个线程内被创建,存在,被访问
常见的线程安全的解决办法: 1.使用方法内局部变量
- 是因为各线程有自己堆栈空间,存储局部变量
- 方法参数传入,多采用传值(volue copy)传入方法内
2.对操作共享资源的语句,方法,对象, 使用同步 比如写入磁盘文件,采用同步锁,但建议尽量用同步代码块,不要用同步方法
3.使用同步的集合类 使用Vector代替ArrayList 使用Hashtable代替HashMap。
4.不要在 Servlet中再创建自己的线程来完成某个功能。 Servlet本身就是多线程的,在Servlet中再创建线程,将导致执行情况复杂化
一句话介绍
what why how
相应的查下 某些技术存在的坑 编写相应的代码来试错
- mysql 分库分表 有哪些技术 这些技术有哪些坑
- mysql 读写分离 有哪些技术 这些技术有哪些坑
- mycat
- springjdbc
- linkedHashMap 有哪些应用场景 存数据有什么缺点
- 通过LUC算法,当linkedHashMap 满了之后 可以会自动删除使用最少的信息
- linkedHashMap 含有linked 在插入和删除上的缺陷
- redis有哪些必须要用到的技术点
-
倒计时
-
- 如何处理大文件的问题
- init方法和内部类有什么区别
- 内部类
- 内部类解决了java不能多继承的问题
- 枚举为什么可以直接使用
- 枚举类默认被 final static 修饰
- 枚举类的成员变量也 默认被 final static 修饰
- hashmap treemap linkedhashmap 对比
- 一般情况下,我们用的最多的是HashMap,在Map 中插入、删除和定位元素,HashMap 是最好的选择。但如果要按顺序或自定义顺序遍历键,那么TreeMap会更好。如果需要输出的顺序和输入的相同,用LinkedHashMap 可以实现,它还可以按读取顺序来排列.
- linkedhashmap 在hashmap的基础上增加了linked,在加快了遍历的速度
- treeMap 拍好顺序,在查找的时候效率比较高,插入的时候效率也没那么低
- 在多线程高并发的情况下,有ConcurrentSkipListMap 提带treemap
-
多线程使用场景
- lock 如何给对象加锁
- 无
- 1:A线程正在执行一个对象中的同步方法,B线程是否可以同时执行同一个对象中的非同步方法? 2:同上,B线程是否可以同时执行同一个对象中的另一个同步方法? 3:线程抛出异常会释放锁吗? 4:volatile和synchronized区别? 5:写一个程序,证明AtomXXX类比synchronized更高效 6:AtomXXX类可以保证可见性吗?请写一个程序来证明 7:写一个程序证明AtomXXX类的多个方法并不构成原子性 8:写一个程序模拟死锁 9:写一个程序,在main线程中启动100个线程,100个线程完成后,主线程打印“完成”,使用join()和countdownlatch都可以完成,请比较异同。 10:一个高效的游戏服务器应该如何设计架构?
- 限流
- Guava RateLimter
- 乐观锁 悲观锁 自旋锁 读写锁(共享锁,排他锁),分段锁 以及在java中的实现方式 分别对应 CAS syn CAS ReadWriteLock LongAdder
- redis 击穿的概念
- 并发和并行的区别
- 并发是指任务提交,并行指任务执行
- 创建线程为什么那么昂贵?
- 必须为线程堆栈分配并初始化一大块内存。
- 需要进行系统调用以在主机OS中创建/注册本机线程。
- 需要创建,初始化描述符并将其添加到JVM内部数据结构中
- 多线程的目的 大概有两个:
- 避免阻塞异步调用: 一是把程序细分成几个功能相对独立的模块,防止其中一个功能模块阻塞导致整个程序假死
- 提高运行效率: 比如多个核同时跑,或者单核里面,某个线程进行IO操作时,另一个线程可以同时执行
- 工厂方法适合在单个产品上做纬度扩展
- 抽象工厂适合在产品族的纬度上扩展
- 设计模式
- 工厂模式典型的应用 springioc
- mediate 调节模式 典型应用 消息中间件
- mvc 分离
- 对修改关闭,对扩展开放
- 高内聚,低耦合
- 通过单例模式降低耦合度,比如某个类作为其他类方法的参数时,可以通过直接使用单例类,而不需要作为参数传递
- 构造方法一个够用绝对不要写两个,每多一个构造函数都需要维护
- 继承是直接继承相应的父类,聚合是实现共同的接口,比如父类实现了什么接口,相应的也去实现,以达到可以控制所有实现了该接口的所有类
- 内部类,可以保证只让本类调用,不被外部的类使用
- 由普通的类来实现接口,必须将接口所有抽象方法重写
- 由抽象类来实现接口,则不必重写接口的方法。可以全部不重写或只重写一部分方法。
- 在不确定使用接口还是抽象类修饰的时候,一般形容词用接口,名称用抽象类
- 数组与链表的区别
| 数组 | 链表 |
|---|---|
| 数组静态分配内存, | 链表动态分配内存; |
| 数组在内存中连续, | 链表不连续; |
| 数组元素在栈区, | 链表元素在堆区; |
| 数组利用下标定位,时间复杂度为O(1), | 链表定位元素时间复杂度O(n); |
| 数组插入或删除元素的时间复杂度O(n), | 链表的时间复杂度O(1)。 |
- zuul和nginx的区别
- zuul是客户端的负载均衡,nginx 是服务端的负载均衡
- 分布式缓存或者分布式锁的设计原理,对分布式常用算法
多线程基础
线程基本概念
-
-
线程:在一个程序内,程序运行的最小单位,一个程序可以同时执行多个线程
- 创建线程:
- 继承 Thread 并重写run方法
- 实现 Runable 接口,重写run方法
- 启动线程的三种方式:
- Thread
- Runable
- 线程池 Executors.newCacheThread
- 让出线程
- sleep 未运行,先让别的线程先运行
- yield 运行中让出 ,进入等待队列
- join 用于等待另外一个线程结束,比如AB线程,A在运行中,通过join将B加入到A线程中,等B运行完成后,再运行A
- 可以通过join的方式,让线程顺序执行
-
线程状态
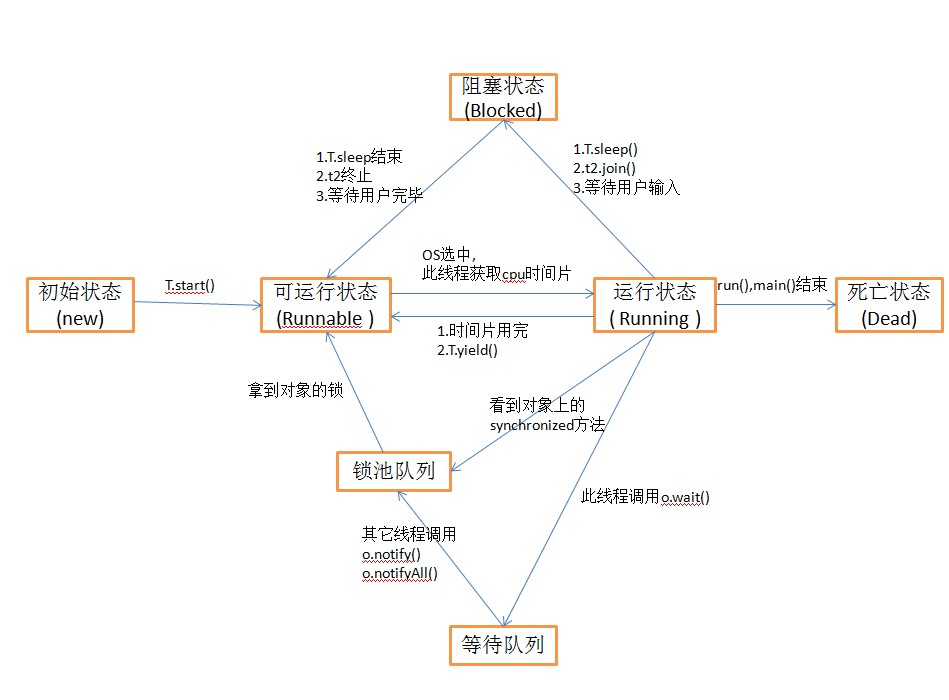
-
- 中段线程(工程中和少使用)
- 通过 interrupt() 方法中段 (需要配合try catch使用,)
- 通过stop() 中段(不建议使用,因为可能数据不一致的问题)
- 通过shell命令 kill -9 对应线程中段
-
获取线程状态
- Thread.getState();
-
多线程使用场景
-
锁
- synchronized 锁定的是某个对象,
- 对方法加锁
- 对 对象加锁
- 锁升级的概念
- 可重入锁
- 异常会释放锁,这个很危险,释放锁之后会被其他线程拿到锁做相应的业务处理
- 八锁
- Atomic lock 使用的是自旋锁 ,性能比synchronized 要高
- 自旋锁锁使用场景:执行时间短,线程少(因为等待情况下才会自旋遍历,很消耗cpu资源)
- 系统锁(synchronized)使用场景:执行时间长,线程多
- synchronized(object)
- 不能使用String常量,Integer Long
- 偏向锁
- 当线程来的时候,先拿到线程id,先不给对象加锁,当还是之前的线程,那直接执行相应的任务,这样在不直接加锁的情况下,效率更高
- 当进来的是另外一个线程,那么按照加锁的方式处理
- 自旋锁
- 当对象被一个线程锁定后,另一个线程会一直询问,是否可以拿到这把锁,会一直问10次,拿不到就进入wait 状态,进入等待队列
- 锁升级
- 偏向锁–>自旋锁–>重量级锁(系统锁)
- volatile
- 保证可见效
- 禁止指令重排
- 可以保证可见性,但是不能保证原子性,保证原子性 需要使用锁
- 没有把握不要用
- 要的时候尽量使用基础变量,不要使用引用值
- volatile可以保证引用不变,但是引用里面的值观察不到变化
- 锁优化
- 锁的粒度细化
- 锁太多的情况下 多锁做粗化
- synchronized 锁对象和锁class
- 1 无论是修饰方法还是修饰代码块都是 对象锁,当一个线程访问一个带synchronized方法时,由于对象锁的存在,所有加synchronized的方法都不能被访问(前提是在多个线程调用的是同一个对象实例中的方法)
- 2 无论是修饰静态方法还是锁定某个对象,都是 类锁.一个class其中的静态方法和静态变量在内存中只会加载和初始化一份,所以,一旦一个静态的方法被申明为synchronized,此类的所有的实例化对象在调用该方法时,共用同一把锁,称之为类锁。
- CAS (无锁优化 自旋)
- Compare and set
- cas
- CPU原语支持
- ABA问题
- 加version
- 乐观锁 悲观锁 偏向锁 自旋锁
- lock 比synchronized 好的的地方
- lock 用的是cas
- tryLock 尝试获取锁 boolean
- 可以打断线程
- 公平锁 队列里面的线程 按照顺序 线程挨个执行
- 非公平锁 队列里面等待的线程 随机执行
- CountDownLatch
- 用法
- CyclicBarrier
- 用法
- Phaser
- 用法
- ReadWriteLock
- 共享锁
- 排他锁
- 怎么用
- 分布式锁
- redis
- zookpeer
- semaphore
- LockSupport
- 可以指定线程结束阻塞状态
- 核心概念
- 所有的线程中,都是通过队列 AbstractQueuedSynchronizer 来排序
- 线程之间不可见
- notify 不释放锁
- wait 会释放锁,并进入阻塞状态
- 乐观锁 悲观锁 自旋锁 读写锁(共享锁,排他锁),分段锁 以及在java中的实现方式 分别对应 CAS syn CAS ReadWriteLock LongAdder
- synchronized 和 Condition 本质区别
- synchronized 只有一个等待队列,Condition 可以有多个
- Varhandle
- 可以将非原子性操作改成原子性操作(普通属性也可以改成原子性操作)
- 比反射的效率高,Varhandle 可以直接操作二进制的码
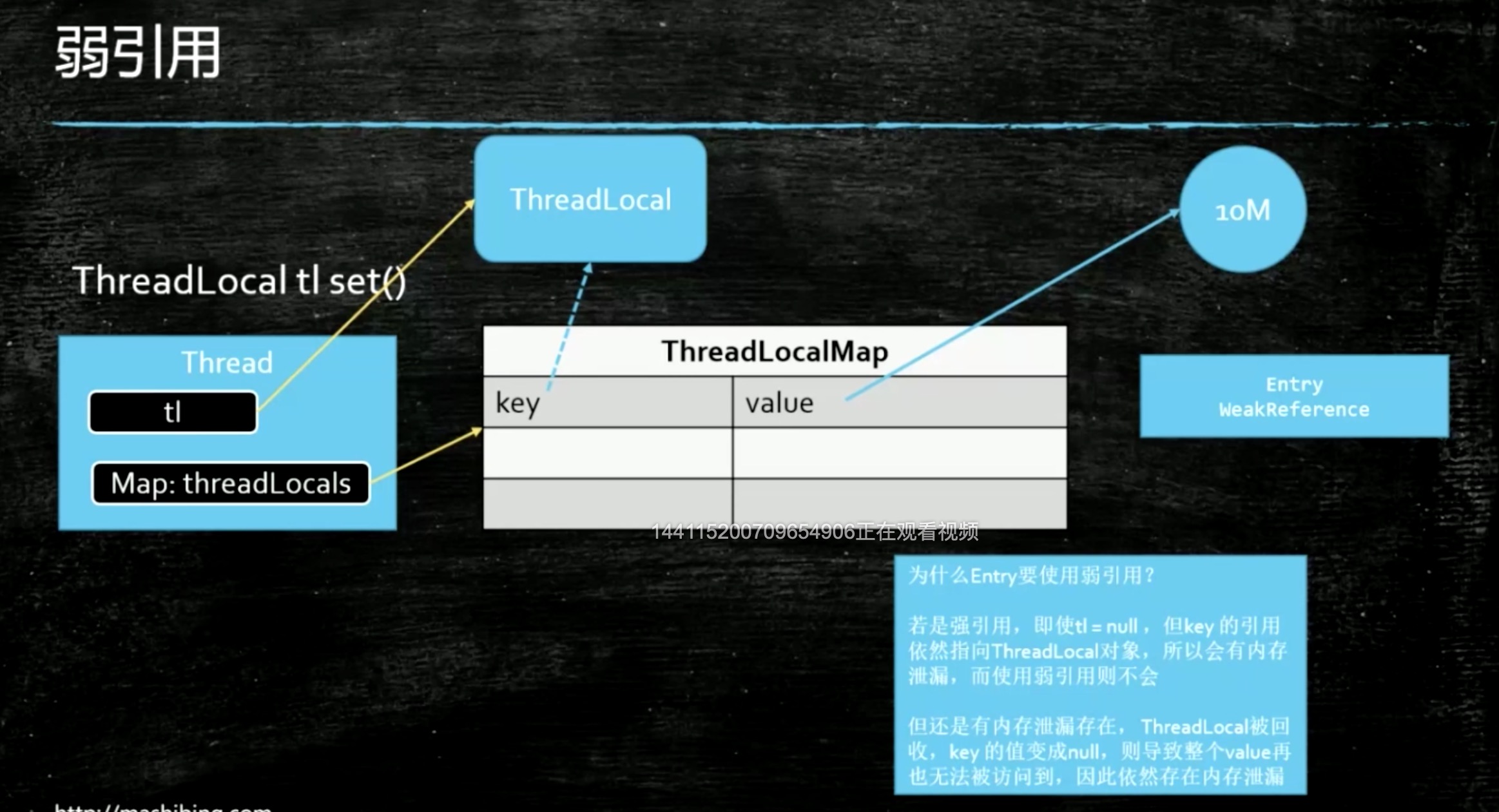
- ThreadLocal
- set
- Thread.currentThread.map(ThreadLocal,new persion)
- ThreadLocal 用途
- 声明式事务
- 使用ThreadLocal 不用的时候 ,需要做 remove 不然有可能会出现内存泄漏
- set
容器
vector hashtable
- 自带锁,性能不好,基本不用
list
set
Queue
- 高并发
- 生产者消费者模型
| 队列 | ||
|---|---|---|
| LinkedBlockingQueue | 无界的 | 最大jvm内存大小 天生的实现了生产者消费者模型 |
| ArrayBlockingQueue | 有界的 | 需要设置队列的大小 |
| PriorityQueue | 优先队列 | 数据按照一定顺序输出,默认又小到大输出,也可以自定义比较输出顺序 |
| DelayQueue | 可以用在时间上的排序 | 按照时间的顺序制作任务 |
| SynchronousQueue | 给线程之间传递任务(容量为零) | 1. 这里只能用 put 方法 ,只能put一次 ,也不能使用 add 方法 2. SynchronousQueue 没有容量,在put之后进入阻塞状态, 需要把数据tack出去 |
| LinkedTransferQueue | 可以在线程间传递多个任务 | 1. transfer() 是阻塞方法,需要 tack() 后才解除阻塞,所有需要先执行 tack() 方法 2.相对 SynchronousQueue 只能两个线程之间信息传递 ,TransferQueue 可以多个线程拿数据 3. 相对 SynchronousQueue 容量为零, TransferQueue 可以在队列里面插入多条数据 |
| ConcurrentLinkedQueue | 双端队列Deque | 1. add() 添加不了抛出异常 2. offer 能不能呢添加会有一个boolean的返回值 3. poll() 取 会remove // peek() 取 不会remove |
Map
| 三个map对比 | 写入 | 读取 |
|---|---|---|
| Hashtable | 相对快 | 满 |
| Collections.synchronizedMap(new HashMap<UUID, UUID>()); | 相对快 | 慢 |
| ConcurrentHashMap | 相对慢一点 | 极快 |
-
linkedhashmap 在hashmap的基础上增加了linked,加快了遍历的速度,但是在查找的时候比较麻烦,它的查找时间负责度是O(n),
- treeMap 排好顺序,在查找的时候效率比较高,插入的时候效率也没那么低
- ConcurrentSkipListMap
- 在多线程高并发的情况下,有ConcurrentSkipListMap 替代 treemap
- 高并发并且排序
- 跳表的概念,(在查找的时候有点二分查找的感觉)
- CopyOnWriteList 写时复制
| 普通容器 | 并发容器 | 并发容器使用场景 |
|---|---|---|
| ArrayList | CopyOnWriteArrayList | 读多写少(写加锁,读不用加锁) |
| HashMap | ConcurrentHashMap | 并发时替代HashMap |
| TreeMap | ConcurrentSkipListMap | 高并发并且排序 |
| ArrayList | Collections.synchronizedList(new ArrayList) | |
- list 和 Queue 却别
- Queue提供了 offer peek poll 等 对线程友好的api
- BlockingQueue 提供了 put 和tack阻塞方法 ,是一个很好的 生产者消费者模型
线程池 ThreadPool
Callable –> Runable + return
Future:接受未来将会产生的结果
FutrueTask –> Futurn+Runable
ExcuteThreadPool 7大参数
| ExcuteThreadPool 7大参数 | |
|---|---|
| coorePoolSize | 核心线程 |
| maximumPoolSize | 最大线程数 |
| 线程空闲时多久销毁 | 可以设置任何时间长度 |
| 销毁的时间单位 | 对应 秒,微秒等 |
| 任务队列 | BlockingQueue 的子类都可以使用 |
| 生产线程的方式 | jdk提供了一种默认策略,也可以自定义 |
| 执行任务的线程和队列满了后,对于的处理方式 | jdk提供了四种策略,也可自定义处理策略 |
ExcuteThreadPool
- 所有线程共用同一个队列
-
为甚么有SingleExcuteThread
任务队列,线程管理
- Cached vs Fixed
阿里都不用,自己估计,进行精确定义
- Scheduled 定时任务线程池
定时器框架:quartz
面试题:假如提供一个闹钟服务,订阅的人有10亿,怎么优化?
并发和并行的区别
并发是指任务提交,并行指任务执行
ForkJoinPool
- 每个线程有自己的队列
- 使用大的任务,通过切分成小的任务加快运行速度
java提高篇(八)----详解内部类
可以将一个类的定义放在另一个类的定义内部,这就是内部类。
内部类是一个非常有用的特性但又比较难理解使用的特性(鄙人到现在都没有怎么使用过内部类,对内部类也只是略知一二)。
第一次见面
内部类我们从外面看是非常容易理解的,无非就是在一个类的内部在定义一个类。
public class OuterClass {
private String name ;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
class InnerClass{
public InnerClass(){
name = "chenssy";
age = 23;
}
}
}
在这里InnerClass就是内部类,对于初学者来说内部类实在是使用的不多,鄙人菜鸟一个同样没有怎么使用过(貌似仅仅只在做swing 注册事件中使用过),但是随着编程能力的提高,我们会领悟到它的魅力所在,它可以使用能够更加优雅的设计我们的程序结构。在使用内部类之间我们需要明白为什么要使用内部类,内部类能够为我们带来什么样的好处。
一、为什么要使用内部类
为什么要使用内部类?在《Think in java》中有这样一句话:使用内部类最吸引人的原因是:每个内部类都能独立地继承一个(接口的)实现,所以无论外围类是否已经继承了某个(接口的)实现,对于内部类都没有影响。
在我们程序设计中有时候会存在一些使用接口很难解决的问题,这个时候我们可以利用内部类提供的、可以继承多个具体的或者抽象的类的能力来解决这些程序设计问题。可以这样说,接口只是解决了部分问题,而 内部类使得多重继承的解决方案变得更加完整。
public interface Father {
}
public interface Mother {
}
public class Son implements Father, Mother {
}
public class Daughter implements Father{
class Mother_ implements Mother{
}
}
其实对于这个实例我们确实是看不出来使用内部类存在何种优点,但是如果Father、Mother不是接口,而是抽象类或者具体类呢?这个时候我们就只能使用内部类才能实现多重继承了。
其实使用内部类最大的优点就在于它能够非常好的解决多重继承的问题,但是如果我们不需要解决多重继承问题,那么我们自然可以使用其他的编码方式,但是使用内部类还能够为我们带来如下特性(摘自《Think in java》):
1、内部类可以用多个实例,每个实例都有自己的状态信息,并且与其他外围对象的信息相互独立。
2、在单个外围类中,可以让多个内部类以不同的方式实现同一个接口,或者继承同一个类。
3、创建内部类对象的时刻并不依赖于外围类对象的创建。
4、内部类并没有令人迷惑的“is-a”关系,他就是一个独立的实体。
5、内部类提供了更好的封装,除了该外围类,其他类都不能访问。
二、内部类基础
在这个部分主要介绍内部类如何使用外部类的属性和方法,以及使用.this与.new。
当我们在创建一个内部类的时候,它无形中就与外围类有了一种联系,依赖于这种联系,它可以无限制地访问外围类的元素。
public class OuterClass {
private String name ;
private int age;
/**省略getter和setter方法**/
public class InnerClass{
public InnerClass(){
name = "chenssy";
age = 23;
}
public void display(){
System.out.println("name:" + getName() +" ;age:" + getAge());
}
}
public static void main(String[] args) {
OuterClass outerClass = new OuterClass();
OuterClass.InnerClass innerClass = outerClass.new InnerClass();
innerClass.display();
}
}
--------------
Output:
name:chenssy ;age:23
在这个应用程序中,我们可以看到内部了InnerClass可以对外围类OuterClass的属性进行无缝的访问,尽管它是private修饰的。这是因为当我们在创建某个外围类的内部类对象时,此时内部类对象必定会捕获一个指向那个外围类对象的引用,只要我们在访问外围类的成员时,就会用这个引用来选择外围类的成员。
其实在这个应用程序中我们还看到了如何来引用内部类:引用内部类我们需要指明这个对象的类型:OuterClasName.InnerClassName。同时如果我们需要创建某个内部类对象,必须要利用外部类的对象通过.new来创建内部类: OuterClass.InnerClass innerClass = outerClass.new InnerClass();。
同时如果我们需要生成对外部类对象的引用,可以使用OuterClassName.this,这样就能够产生一个正确引用外部类的引用了。当然这点实在编译期就知晓了,没有任何运行时的成本。
public class OuterClass {
public void display(){
System.out.println("OuterClass...");
}
public class InnerClass{
public OuterClass getOuterClass(){
return OuterClass.this;
}
}
public static void main(String[] args) {
OuterClass outerClass = new OuterClass();
OuterClass.InnerClass innerClass = outerClass.new InnerClass();
innerClass.getOuterClass().display();
}
}
-------------
Output:
OuterClass...
到这里了我们需要明确一点,内部类是个编译时的概念,一旦编译成功后,它就与外围类属于两个完全不同的类(当然他们之间还是有联系的)。对于一个名为OuterClass的外围类和一个名为InnerClass的内部类,在编译成功后,会出现这样两个class文件:OuterClass.class和OuterClass$InnerClass.class。
在Java中内部类主要分为成员内部类、局部内部类、匿名内部类、静态内部类。
三、成员内部类
成员内部类也是最普通的内部类,它是外围类的一个成员,所以他是可以无限制的访问外围类的所有 成员属性和方法,尽管是private的,但是外围类要访问内部类的成员属性和方法则需要通过内部类实例来访问。
在成员内部类中要注意两点,第一:成员内部类中不能存在任何static的变量和方法;第二:成员内部类是依附于外围类的,所以只有先创建了外围类才能够创建内部类。
public class OuterClass {
private String str;
public void outerDisplay(){
System.out.println("outerClass...");
}
public class InnerClass{
public void innerDisplay(){
//使用外围内的属性
str = "chenssy...";
System.out.println(str);
//使用外围内的方法
outerDisplay();
}
}
/*推荐使用getxxx()来获取成员内部类,尤其是该内部类的构造函数无参数时 */
public InnerClass getInnerClass(){
return new InnerClass();
}
public static void main(String[] args) {
OuterClass outer = new OuterClass();
OuterClass.InnerClass inner = outer.getInnerClass();
inner.innerDisplay();
}
}
--------------------
chenssy...
outerClass...
推荐使用getxxx()来获取成员内部类,尤其是该内部类的构造函数无参数时 。
四、局部内部类
有这样一种内部类,它是嵌套在方法和作用于内的,对于这个类的使用主要是应用与解决比较复杂的问题,想创建一个类来辅助我们的解决方案,到那时又不希望这个类是公共可用的,所以就产生了局部内部类,局部内部类和成员内部类一样被编译,只是它的作用域发生了改变,它只能在该方法和属性中被使用,出了该方法和属性就会失效。
对于局部内部类实在是想不出什么好例子,所以就引用《Think in java》中的经典例子了。
定义在方法里:
public class Parcel5 {
public Destionation destionation(String str){
class PDestionation implements Destionation{
private String label;
private PDestionation(String whereTo){
label = whereTo;
}
public String readLabel(){
return label;
}
}
return new PDestionation(str);
}
public static void main(String[] args) {
Parcel5 parcel5 = new Parcel5();
Destionation d = parcel5.destionation("chenssy");
}
}
定义在作用域内:
public class Parcel6 {
private void internalTracking(boolean b){
if(b){
class TrackingSlip{
private String id;
TrackingSlip(String s) {
id = s;
}
String getSlip(){
return id;
}
}
TrackingSlip ts = new TrackingSlip("chenssy");
String string = ts.getSlip();
}
}
public void track(){
internalTracking(true);
}
public static void main(String[] args) {
Parcel6 parcel6 = new Parcel6();
parcel6.track();
}
}
五、匿名内部类
在做Swing编程中,我们经常使用这种方式来绑定事件
button2.addActionListener(
new ActionListener(){
public void actionPerformed(ActionEvent e) {
System.out.println("你按了按钮二");
}
});
我们咋一看可能觉得非常奇怪,因为这个内部类是没有名字的,在看如下这个例子:
public class OuterClass {
public InnerClass getInnerClass(final int num,String str2){
return new InnerClass(){
int number = num + 3;
public int getNumber(){
return number;
}
}; /* 注意:分号不能省 */
}
public static void main(String[] args) {
OuterClass out = new OuterClass();
InnerClass inner = out.getInnerClass(2, "chenssy");
System.out.println(inner.getNumber());
}
}
interface InnerClass {
int getNumber();
}
----------------
Output:
5
这里我们就需要看清几个地方
1、 匿名内部类是没有访问修饰符的。
2、 new 匿名内部类,这个类首先是要存在的。如果我们将那个InnerClass接口注释掉,就会出现编译出错。
3、 注意getInnerClass()方法的形参,第一个形参是用final修饰的,而第二个却没有。同时我们也发现第二个形参在匿名内部类中没有使用过,所以当所在方法的形参需要被匿名内部类使用,那么这个形参就必须为final。
4、 匿名内部类是没有构造方法的。因为它连名字都没有何来构造方法。
PS:由于篇幅有限,对匿名内部类就介绍到这里,有关更多关于匿名内部类的知识,我就会在下篇博客(java提高篇—–详解匿名内部类)做详细的介绍,包括为何形参要定义成final,怎么对匿名内部类进行初始化等等,敬请期待……
六、静态内部类
在java提高篇—–关键字static中提到Static可以修饰成员变量、方法、代码块,其他它还可以修饰内部类,使用static修饰的内部类我们称之为静态内部类,不过我们更喜欢称之为嵌套内部类。静态内部类与非静态内部类之间存在一个最大的区别,我们知道非静态内部类在编译完成之后会隐含地保存着一个引用,该引用是指向创建它的外围内,但是静态内部类却没有。没有这个引用就意味着:
1、 它的创建是不需要依赖于外围类的。
2、 它不能使用任何外围类的非static成员变量和方法。
public class OuterClass {
private String sex;
public static String name = "chenssy";
/**
*静态内部类
*/
static class InnerClass1{
/* 在静态内部类中可以存在静态成员 */
public static String _name1 = "chenssy_static";
public void display(){
/*
* 静态内部类只能访问外围类的静态成员变量和方法
* 不能访问外围类的非静态成员变量和方法
*/
System.out.println("OutClass name :" + name);
}
}
/**
* 非静态内部类
*/
class InnerClass2{
/* 非静态内部类中不能存在静态成员 */
public String _name2 = "chenssy_inner";
/* 非静态内部类中可以调用外围类的任何成员,不管是静态的还是非静态的 */
public void display(){
System.out.println("OuterClass name:" + name);
}
}
/**
* @desc 外围类方法
* @author chenssy
* @data 2013-10-25
* @return void
*/
public void display(){
/* 外围类访问静态内部类:内部类. */
System.out.println(InnerClass1._name1);
/* 静态内部类 可以直接创建实例不需要依赖于外围类 */
new InnerClass1().display();
/* 非静态内部的创建需要依赖于外围类 */
OuterClass.InnerClass2 inner2 = new OuterClass().new InnerClass2();
/* 方位非静态内部类的成员需要使用非静态内部类的实例 */
System.out.println(inner2._name2);
inner2.display();
}
public static void main(String[] args) {
OuterClass outer = new OuterClass();
outer.display();
}
}
----------------
Output:
chenssy_static
OutClass name :chenssy
chenssy_inner
OuterClass name:chenssy
上面这个例子充分展现了静态内部类和非静态内部类的区别。
到这里内部类的介绍就基本结束了!对于内部类其实本人认识也只是皮毛,逼近菜鸟一枚,认知有限!我会利用这几天时间好好研究内部类!
339 post articles, 43 pages.