FeignClient详解、配置
FeignClient详解
首先查看@FeignClient注解的源码:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface FeignClient {
@AliasFor("name")
String value() default "";
@Deprecated
String serviceId() default "";
@AliasFor("value")
String name() default "";
String qualifier() default "";
String url() default "";
boolean decode404() default false;
Class<?>[] configuration() default {};
Class<?> fallback() default void.class;
Class<?> fallbackFactory() default void.class;
String path() default "";
boolean primary() default true;
}
1234567891011121314151617181920212223242526272829303132
FeignClient注解被@Target(ElementType.TYPE)修饰,标识FeignClient注解的作用目标在接口上。
@Retention(RetentionPolicy.RUNTIME)注解表明该注解会在Class字节码文件中存在,在运行时可以通过反射获取到。
@Documented表示该注解将被包含在Javadoc中。
@FeignClient注解用于创建声明式API接口,该接口是RESTful风格的。Feign被设计成插拔式的,可以注入其他组件和Feign一起使用。最典型的是如果Ribbon可用,Feign会和Ribbon相结合进行负载均衡。
在代码中,value()和name()一样,是被调用的服务的ServiceId。url()直接填写硬编码的Url地址。
decode404()即404是被解码,还是抛异常。
configuration()指明FeignClient的配置类,默认的配置类为FeignClientsConfiguration类,在缺省的情况下,这个类注入了默认的Decoder、Encoder和Contract等配置的Bean。
fallback()为配置熔断器的处理类。
FeignClient的配置
Feign Client默认的配置类为FeignClientsConfiguration, 这个类在spring-cloud-nettlix-core的jar包下。
打开这个类,可以发现这个类注入了很多Feign相关的配置Bean,包括FeignRetryer、FeignL oggerFactory和FormattingConversionService 等。
另外,Decoder、 Encoder 和Contract这3个类在没有Bean被注入的情况下,会自动注入默认配置的Bean,即ResponseEntityDecoder、SpringEncoder和SpringMvcContract。默认注入的配置如下。
- Decoder feignDecoder:ResponseEntityDecoder
- Decoder feignEncoder:SpringEncoder
- Logger FeignLogger:Slf4jLogger
- Contract feignContract:SpringMvcContract
- Feign.Builder feignBuilder: HystrixFeign.Builder
FeignClientsConfiguration的配置类部分代码如下,@ConditionalOnMissingBean注解表示如果没有注入该类的Bean就会默认注入一个Bean:

重写FeignClientsConfiguration类中的Bean,覆盖掉默认的配置Bean,从而达到自定义配置的目的。例如Feign默认的配置在请求失败后,重试次数为0,即不重试(Retryer.NEVERRETRY)。现在希望在请求失败后能够重试,这时需要写一个配置FeignConfig 类,在该类中注入Retryer的Bean,覆盖掉默认的Retryer的Bean,并将FeignConfig指定为FeignClient的配置类。FeignConfig 类的代码如下:
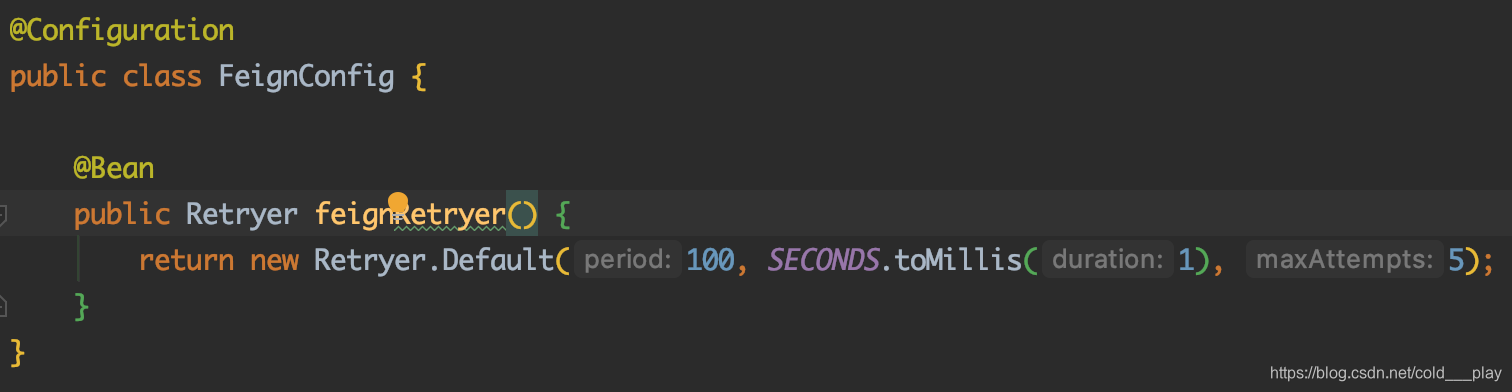
在上面的代码中,通过覆盖了默认的Retryer的Bean,更改了该FeignClient的请求失败重试策略,重试间隔为100毫秒,最大重试时间为1秒,重试次数为5次。
Http请求中Content-Type讲解以及在Spring MVC注解中produce和consumes配置详解
引言: 在Http请求中,我们每天都在使用Content-type来指定不同格式的请求信息,但是却很少有人去全面了解content-type中允许的值有多少,这里将讲解Content-Type的可用值,以及在spring MVC中如何使用它们来映射请求信息。
- Content-Type
MediaType,即是Internet Media Type,互联网媒体类型;也叫做MIME类型,在Http协议消息头中,使用Content-Type来表示具体请求中的媒体类型信息。
1. 类型格式:type/subtype(;parameter)? type
2. 主类型,任意的字符串,如text,如果是*号代表所有;
3. subtype 子类型,任意的字符串,如html,如果是*号代表所有;
4. parameter 可选,一些参数,如Accept请求头的q参数, Content-Type的 charset参数。
例如: Content-Type: text/html;charset:utf-8;
常见的媒体格式类型如下:
- text/html : HTML格式
- text/plain :纯文本格式
- text/xml : XML格式
- image/gif :gif图片格式
- image/jpeg :jpg图片格式
- image/png:png图片格式
以application开头的媒体格式类型:
- application/xhtml+xml :XHTML格式
- application/xml : XML数据格式
- application/atom+xml :Atom XML聚合格式
- application/json : JSON数据格式
- application/pdf :pdf格式
- application/msword : Word文档格式
- application/octet-stream : 二进制流数据(如常见的文件下载)
- application/x-www-form-urlencoded : <form encType=””>中默认的encType,form表单数据被编码为key/value格式发送到服务器(表单默认的提交数据的格式)
另外一种常见的媒体格式是上传文件之时使用的:
- multipart/form-data : 需要在表单中进行文件上传时,就需要使用该格式
以上就是我们在日常的开发中,经常会用到的若干content-type的内容格式。
- Spring MVC中关于关于Content-Type类型信息的使用
首先我们来看看RequestMapping中的Class定义:
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Mapping
public @interface RequestMapping {
String[] value() default {};
RequestMethod[] method() default {};
String[] params() default {};
String[] headers() default {};
String[] consumes() default {};
String[] produces() default {};
}
value: 指定请求的实际地址, 比如 /action/info之类。 method: 指定请求的method类型, GET、POST、PUT、DELETE等 consumes: 指定处理请求的提交内容类型(Content-Type),例如application/json, text/html; produces: 指定返回的内容类型,仅当request请求头中的(Accept)类型中包含该指定类型才返回 params: 指定request中必须包含某些参数值是,才让该方法处理 headers: 指定request中必须包含某些指定的header值,才能让该方法处理请求
其中,consumes, produces使用content-typ信息进行过滤信息;headers中可以使用content-type进行过滤和判断。
- 使用示例
3.1 headers
@RequestMapping(value = "/test", method = RequestMethod.GET, headers="Referer=http://www.ifeng.com/")
public void testHeaders(@PathVariable String ownerId, @PathVariable String petId) {
// implementation omitted
}
这里的Headers里面可以匹配所有Header里面可以出现的信息,不局限在Referer信息。
示例2
@RequestMapping(value = "/response/ContentType", headers = "Accept=application/json")
public void response2(HttpServletResponse response) throws IOException {
//表示响应的内容区数据的媒体类型为json格式,且编码为utf-8(客户端应该以utf-8解码)
response.setContentType("application/json;charset=utf-8");
//写出响应体内容
String jsonData = "{\"username\":\"zhang\", \"password\":\"123\"}";
response.getWriter().write(jsonData);
}
服务器根据请求头“Accept=application/json”生产json数据。
当你有如下Accept头,将遵守如下规则进行应用: ①Accept:text/html,application/xml,application/json 将按照如下顺序进行produces的匹配 ①text/html ②application/xml ③application/json ②Accept:application/xml;q=0.5,application/json;q=0.9,text/html 将按照如下顺序进行produces的匹配 ①text/html ②application/json ③application/xml 参数为媒体类型的质量因子,越大则优先权越高(从0到1) ③Accept:/,text/,text/html 将按照如下顺序进行produces的匹配 ①text/html ②text/ ③/
即匹配规则为:最明确的优先匹配。
Requests部分
| Header | 解释 | 示例 |
|---|---|---|
| Accept | 指定客户端能够接收的内容类型 | Accept: text/plain, text/html |
| Accept-Charset | 浏览器可以接受的字符编码集。 | Accept-Charset: iso-8859-5 |
| Accept-Encoding | 指定浏览器可以支持的web服务器返回内容压缩编码类型。 | Accept-Encoding: compress, gzip |
| Accept-Language | 浏览器可接受的语言 | Accept-Language: en,zh |
| Accept-Ranges | 可以请求网页实体的一个或者多个子范围字段 | Accept-Ranges: bytes |
| Authorization | HTTP授权的授权证书 | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
| Cache-Control | 指定请求和响应遵循的缓存机制 | Cache-Control: no-cache |
| Connection | 表示是否需要持久连接。(HTTP 1.1默认进行持久连接) | Connection: close |
| Cookie | HTTP请求发送时,会把保存在该请求域名下的所有cookie值一起发送给web服务器。 | Cookie: $Version=1; Skin=new; |
| Content-Length | 请求的内容长度 | Content-Length: 348 |
| Content-Type | 请求的与实体对应的MIME信息 | Content-Type: application/x-www-form-urlencoded |
| Date | 请求发送的日期和时间 | Date: Tue, 15 Nov 2010 08:12:31 GMT |
| Expect | 请求的特定的服务器行为 | Expect: 100-continue |
| From | 发出请求的用户的Email | From: user@email.com |
| Host | 指定请求的服务器的域名和端口号 | Host: www.zcmhi.com |
| If-Match | 只有请求内容与实体相匹配才有效 | If-Match: “737060cd8c284d8af7ad3082f209582d” |
| If-Modified-Since | 如果请求的部分在指定时间之后被修改则请求成功,未被修改则返回304代码 | If-Modified-Since: Sat, 29 Oct 2010 19:43:31 GMT |
| If-None-Match | 如果内容未改变返回304代码,参数为服务器先前发送的Etag,与服务器回应的Etag比较判断是否改变 | If-None-Match: “737060cd8c284d8af7ad3082f209582d” |
| If-Range | 如果实体未改变,服务器发送客户端丢失的部分,否则发送整个实体。参数也为Etag | If-Range: “737060cd8c284d8af7ad3082f209582d” |
| If-Unmodified-Since | 只在实体在指定时间之后未被修改才请求成功 | If-Unmodified-Since: Sat, 29 Oct 2010 19:43:31 GMT |
| Max-Forwards | 限制信息通过代理和网关传送的时间 | Max-Forwards: 10 |
| Pragma | 用来包含实现特定的指令 | Pragma: no-cache |
| Proxy-Authorization | 连接到代理的授权证书 | Proxy-Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
| Range | 只请求实体的一部分,指定范围 | Range: bytes=500-999 |
| Referer | 先前网页的地址,当前请求网页紧随其后,即来路 | Referer: http://www.zcmhi.com/archives/71.html |
| TE | 客户端愿意接受的传输编码,并通知服务器接受接受尾加头信息 | TE: trailers,deflate;q=0.5 |
| Upgrade | 向服务器指定某种传输协议以便服务器进行转换(如果支持) | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 |
| User-Agent | User-Agent的内容包含发出请求的用户信息 | User-Agent: Mozilla/5.0 (Linux; X11) |
| Via | 通知中间网关或代理服务器地址,通信协议 | Via: 1.0 fred, 1.1 nowhere.com (Apache/1.1) |
| Warning | 关于消息实体的警告信息 | Warn: 199 Miscellaneous warning |
Responses 部分
| Header | 解释 | 示例 |
|---|---|---|
| Accept-Ranges | 表明服务器是否支持指定范围请求及哪种类型的分段请求 | Accept-Ranges: bytes |
| Age | 从原始服务器到代理缓存形成的估算时间(以秒计,非负) | Age: 12 |
| Allow | 对某网络资源的有效的请求行为,不允许则返回405 | Allow: GET, HEAD |
| Cache-Control | 告诉所有的缓存机制是否可以缓存及哪种类型 | Cache-Control: no-cache |
| Content-Encoding | web服务器支持的返回内容压缩编码类型。 | Content-Encoding: gzip |
| Content-Language | 响应体的语言 | Content-Language: en,zh |
| Content-Length | 响应体的长度 | Content-Length: 348 |
| Content-Location | 请求资源可替代的备用的另一地址 | Content-Location: /index.htm |
| Content-MD5 | 返回资源的MD5校验值 | Content-MD5: Q2hlY2sgSW50ZWdyaXR5IQ== |
| Content-Range | 在整个返回体中本部分的字节位置 | Content-Range: bytes 21010-47021/47022 |
| Content-Type | 返回内容的MIME类型 | Content-Type: text/html; charset=utf-8 |
| Date | 原始服务器消息发出的时间 | Date: Tue, 15 Nov 2010 08:12:31 GMT |
| ETag | 请求变量的实体标签的当前值 | ETag: “737060cd8c284d8af7ad3082f209582d” |
| Expires | 响应过期的日期和时间 | Expires: Thu, 01 Dec 2010 16:00:00 GMT |
| Last-Modified | 请求资源的最后修改时间 | Last-Modified: Tue, 15 Nov 2010 12:45:26 GMT |
| Location | 用来重定向接收方到非请求URL的位置来完成请求或标识新的资源 | Location: http://www.zcmhi.com/archives/94.html |
| Pragma | 包括实现特定的指令,它可应用到响应链上的任何接收方 | Pragma: no-cache |
| Proxy-Authenticate | 它指出认证方案和可应用到代理的该URL上的参数 | Proxy-Authenticate: Basic |
| refresh | 应用于重定向或一个新的资源被创造,在5秒之后重定向(由网景提出,被大部分浏览器支持) | Refresh: 5; url=http://www.zcmhi.com/archives/94.html |
| Retry-After | 如果实体暂时不可取,通知客户端在指定时间之后再次尝试 | Retry-After: 120 |
| Server | web服务器软件名称 | Server: Apache/1.3.27 (Unix) (Red-Hat/Linux) |
| Set-Cookie | 设置Http Cookie | Set-Cookie: UserID=JohnDoe; Max-Age=3600; Version=1 |
| Trailer | 指出头域在分块传输编码的尾部存在 | Trailer: Max-Forwards |
| Transfer-Encoding | 文件传输编码 | Transfer-Encoding:chunked |
| Vary | 告诉下游代理是使用缓存响应还是从原始服务器请求 | Vary: * |
| Via | 告知代理客户端响应是通过哪里发送的 | Via: 1.0 fred, 1.1 nowhere.com (Apache/1.1) |
| Warning | 警告实体可能存在的问题 | Warning: 199 Miscellaneous warning |
| WWW-Authenticate | 表明客户端请求实体应该使用的授权方案 | WWW-Authenticate: Basic |
3.2 params的示例
@RequestMapping(value = "/test/{userId}", method = RequestMethod.GET, params="myParam=myValue")
public void findUser(@PathVariable String userId) {
// implementation omitted
}
仅处理请求中包含了名为“myParam”,值为“myValue”的请求,起到了一个过滤的作用。
3.3 consumes/produces
@Controller
@RequestMapping(value = "/users", method = RequestMethod.POST, consumes="application/json", produces="application/json")
@ResponseBody
public List<User> addUser(@RequestBody User userl) {
// implementation omitted
return List<User> users;
}
方法仅处理request Content-Type为“application/json”类型的请求. produces标识==>处理request请求中Accept头中包含了”application/json”的请求,同时暗示了返回的内容类型为application/json;
- 总结
在本文中,首先介绍了Content-Type主要支持的格式内容,然后基于@RequestMapping标注的内容介绍了主要的使用方法,其中,headers, consumes,produces,都是使用Content-Type中使用的各种媒体格式内容,可以基于这个格式内容来进行访问的控制和过滤。
参考资料:
-
HTTP中支持的Content-Type: http://tool.oschina.NET/commons
-
Media Type介绍。 http://www.iteye.com/topic/1127120
为什么要使用枚举,枚举为何被称为语法糖
为什么要用枚举呢?
在JDK1.5之前,Java有两种方式定义新类型:类和接口。对于大部分面向对象编程来说,这两种方法看起来似乎足够了。但是在一些特殊情况下,这些方法就不适合。例如,想定义一个Color类,它只能有RED、GREEN、BLUE 3种值,其他的任何值都是非法的,那么JDK1.5之前虽然可以构造这样的代码,但是要做很多的工作,就可能带来很多不安全的问题。而JDK1.5之后引入的枚举类型就能解决这些问题。
什么是枚举呢?
枚举,在数学上是指有穷序列集,就是说某一类东西,能一一列出来。比如月份,可以有一月、二月……十二月,不能再多了,星期也是一样的概念。先声明,如果只是简单的穷举,除了语义更明确,我没觉得用“枚举”来替代“一个接口定义几个常量”这种方式有什么其他优势,只有被穷举的对象有一定业务性导致其具有一定复杂性,枚举才体现其简约。
枚举还有一个特点,就是可以代表数值,比如说第一个定义的元素对应的值为0,每个枚举元素从0开始,逐一增加。此时,这个数值也代表他们本身,相当于每一个元素有两个名字。
###
什么时候使用呢
1、一周有多少天?
7天。像这样固定不变的一组数据,如果我们的程序有需要用到这“7天”的相关信息,例如:发工资分为工作日和周末,可以考虑使用枚举类型。
2、太阳系有多少个行星?
8个。当我们需要计算每个行星的表面重力的时候,像这样我们需要用到固定不变的一组信息中的每一个元素携带了不同的信息,可以考虑使用枚举类型。
3、计算器中的基础运算符。
加减乘除。像这样我们需要用到固定不变的一组信息中的每一个元素都决定了不同的行为的时候,可以考虑使用枚举类型。
4、web请求返回的状态。
比如:error为-1,success为0,未登录为-9等可以设为枚举类型。
为什么说枚举是语法糖呢?
假如我们要定义季节类,包含一个季节名称和执行计划,没有枚举之前我们也许是这样做的
定义一个父类
public abstract class Weather {
public String name;
abstract void plan();
}
定义春天
public class SpringWeather extends Weather{
public SpringWeather(String name) {
this.name=name;
}
@Override
void plan() {
System.out.println("春天");
}
}
定义夏天
public class SummerWeather extends Weather{
public SummerWeather(String name) {
this.name=name;
}
@Override
void plan() {
System.out.println("夏天");
}
}
定义秋天,定义冬天…….
如上加上我们省略掉的,要穷举季节这样一个具有一定复杂性的有穷序列集,我们要写多个类,JAVA语法真啰嗦!有了枚举之后我们可以这样写:
public enum WeatherEnum {
SPRING(1, "春天") {
@Override
void plan() {
System.out.println("春天");
}
},
SUMMER(2, "夏天") {
@Override
void plan() {
System.out.println("夏天");
}
},
AUTUMN(3, "秋天") {
@Override
void plan() {
System.out.println("秋天");
}
},
WINTER(4, "冬天") {
@Override
void plan() {
System.out.println("冬天");
}
};
private Integer num;
private String name;
private WeatherEnum(Integer num, String name) {
this.num = num;
this.name = name;
}
public Integer getNum() {
return num;
}
public void setNum(Integer num) {
this.num = num;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
abstract void plan();
@Override
public String toString() {
return "num:" + this.num + " name:" + this.name;
}
}
只需要enum关键字定义一个类就可以代替上面的多个类,确实简约!
事实上现实中的业务比季节这个概念要复杂些,没有枚举的话可能还需要更多的类定义,比如季节里面的计划,我们现在仅仅是简单地输出一句话而已。 以上便是JAVA枚举语法糖的一个优势,既然是语法糖,也就是说,只是看起来是这样子,事实上枚举定义编译后,也是被编译成了多个class。这个可以查看编译后的class文件就知道了!
可以看出,使用枚举能使我们减少类的定义,并且语义明确,使用面向对象的说法就是枚举实现了代码复用。

再查看一下反编译后的类,发现类都是被static修饰的,当我们使用enmu来定义一个枚举类型的时候,编译器会自动帮我们创建一个final类型的类,所以枚举类型不能被继承.
zuul-server
zuul 基本使用
- zuul(网关可以做什么)
- 分发服务
- 身份认证
- 过滤请求
- 监控
- 路由
- 限流
- 过滤器的执行顺序,节省计算的资源
- 网关接口容错
- 创建一个对象实现 FallbackProvider
- 生产中小技巧
- db中存储:过滤器开关
- 配合 spring-boot-starter-actuator 更清爽
- db中存储:过滤器开关
项目中遇到的问题
-
使用zuul cookie 和token 不能向后传递的问题
-
通过在yml里面配置下 ,把敏感信息制成空
zuul: # 以下配置,表示忽略下面的值向微服务传播,以下配置为空表示:所有请求头都透传到后面微服务。 # sensitive-headers: routes: # 此处名字随便取 custom-zuul-name: path: /zuul-custom-name/** service-id: service-sms
-
-
老项目改造中路由问题
- 方式一 yml配置
RibbonXXXFilter 路由到其他服务 SimpleHostRoultFilter 路由到其他url SendForewordFilter 路由到自己的路径 zuul: routes: xxx: path: /forword1/** url: forward:/myController # # 配合 风雨冷人 # xxxx: /zuul-api-driver/** ## 此处名字随便取 # custom-zuul-name: # path: /zuul-api-driver/** # url: http://localhost:8003/-
方式二,使用zuul的Filter
1.过滤器 route 2.获取请求过来的url(请求) 3.url(请求) = url(目的地)映射 4.设置RequestContext中的 serviceid url ==== 开发之前,想清楚步骤 技术和业务做选择和取舍。(100种方法,你去其中一种,出问题自己扛)
-
动态路由(根据不同的用户路由到不同的服务)
- 路由到服务
- 路由到具体地址
-
微服务404的原因
- url是从哪里拿到的
- 从eureka中拿到
- 从配置文件中拿到
- url是从哪里拿到的
微服务项目结构
项目在独立的仓库
| —online-taxi-tree |
| | — 项目A |
| | — 项目B |
单独项目
| — pom |
| — src |
| | — controller |
| | — service |
impl
接口
| | — dao |
entity
mapper
| | — manager |
| | — constant 常量 |
| | — request 接受的参数bean |
| | — response 返回的参数bean |
| — resource |
| | — mapper |
| | — xxxmapper.xml |
yml
异常
dao层的一次:必用打日志,catch,抛出去
service:打日志,详细形象,时间,参数
controller:异常包装成 状态码
公司maven私服
userBean
dto:common 二方库
接口设计规范
接口设计规范
- 协议:https:ios只能用https
- 域名: /api.yuming.com/
- 版本:v1
- 路径:/ooxx/xxoo
- 动作:
- post:新建
- put:修改(修改后的全量数据)
- patch:修改(修改哪个传哪个)
- delete:删除
- get:查询
接口安全
- CIA:保密性,完整性,可用性
- 手机号,身份证号等要脱敏
- 数据层面
-
sql注入,(id,sql)
-
select * form table where name=(变量;delete table)
-
过滤 jsoup框架
-
xss: spring-htmlUtils
- 在正常用户请求中执行了黑客提供的恶意代码, 用户数据没有过滤,转义
-
csrf(跨站伪装请求):人机交互,token
- 冒充别人的登录信息,问题出在:没有防范不信任的调用
Java对html标签的过滤和清洗 https://www.cnblogs.com/qizhelongdeyang/p/9884716.html -
referer:防盗链
-
数据权限控制
- link1链接
- A用户请求,删除 order/a1
- B用户请求,删除 order/a1
-
项目中优化的点
-
开发时用快照版本 生产环境不能用快照版本
- 通过将数据从堆移到栈中提升效率
- 常用不变的用缓存,不要用db(把内存用起来减少io ,io是瓶颈,比如网络io,磁盘io)
- 提高QPS
- 提高并发数
- 能用多线程就使用多线程
- 增加各种连接数,tomcat,mysql,redis等等
- 服务无状态:便于横向扩展,扩机器
- 让服务能力怼等(serviceUrl,打乱顺序)
- 减少相应时间
- 异步(最终一致性)
- 缓存
- 提高并发数
339 post articles, 43 pages.