二分查找
通用解题模板:
区间定义:[l, r) 左闭右开
f(m)函数满足该条件,可直接返回对应位置g(m)函数满足该条件,可移动右边界- 同理,在else中移动左边界
- 如果没有这个条件的判断就是
lowwer_bound和higher_bound.def binary_search(l, r): while l < r: m = l + (r - l) // 2 if f(m): # 判断找了没有,optional return m if g(m): r = m # new range [l, m) else: l = m + 1 # new range [m+1, r) return l # or not found
lower bound: find index of i, such that A[i] >= x
def lowwer_bound(self, nums, target):
# find in range [left, right)
left, right = 0, len(nums)
while left < right:
mid = left + (right - left) / 2
if nums[mid] < target:
left = mid + 1
else:
right = mid
return left
upper bound: find index of i, such that A[i] > x
def higher_bound(self, nums, target):
# find in range [left, right)
left, right = 0, len(nums)
while left < right:
mid = left + (right - left) / 2
if nums[mid] <= target:
left = mid + 1
else:
right = mid
return left
只要符合单调,就可以二分
- 在题目 面试题56 - I. 数组中数字出现的次数 有个很棒的概念 只要符合单调,就可以二分 下面通过例子来说明
题目1 面试题56 - I. 数组中数字出现的次数
一个整型数组 `nums` 里除两个数字之外,其他数字都出现了两次。请写程序找出这两个只出现一次的数字。要求时间复杂度是`O(n)`,空间复杂度是`O(1)`。
如果我们对所有的数字进行异或,假设只出现一次的数字分别是 p 和 q,那么最终的结果 p⊕q,此时我们不知道 p 和 q 分别是什么。但是如果我们能把 p 和 q 从 数组里面区分开来呢?假设我们知道了某个数 r,r 是介于 p 和 q 之间,那么我们可以把整个数组分成两部分 —— a<=r或 a>r
。并且,一个数组里有 p,另一个数组里有 q。那么对这两部分的数字分别求异或和,结果就变成了 p 和 q 。完美!这样就把问题转换成了我们已经解决的问题上了!
在某次消防演习中,消防员问一程序员如果公司着火要怎么办,程序员回答使用灭火器灭火。消防员再问,如果没有着火怎么办?程序员回答把公司点着,这样就把问题归结到一个已经解决的问题上了!手动划掉
我举个栗子来说一下上面的想法:
我们看下数组 [1,2,10,4,1,4,3,3],我们知道 p 和 q 是 2 和 10。
中间的数字我们假设是 3,根据 a<=3 和 a>3 划分成了[1,2,1,3,3] 和 [10,4,4]。这两个数组分别异或就是 2 和 10。
但是还没有解决,怎么找到 pp 和 qq 中间的数字 rr 呢?
二分!!!
为什么是 二分 呢?一个暴力的方法就是从数组最小的元素到最大的元素枚举所有可能的 r,然后根据 a<=r和 a>r 化成两个数组,再看两个数组的异或和是不是都不为 0,如果是,那我们就找到了 r。但是注意到,在枚举 r 的时候,两个数组的异或和是否为0这个性质是单调的!
下图是从数组最小的元素到最大的元素枚举 rr 的过程。
为了更能体现出来单调的性质,我把 r=0 和 r=11 也加进来了。
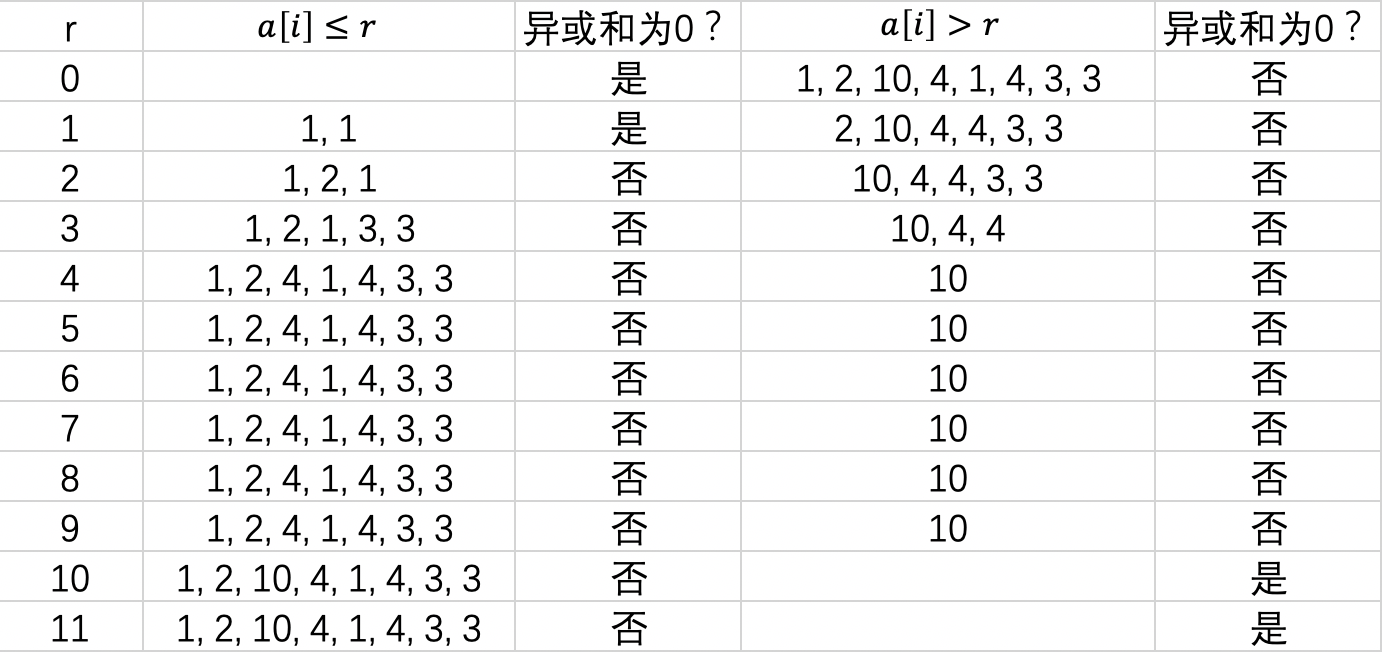
简单来说,
- 如果当前左边的数组异或和为 00, 右边不为 00,说明当前枚举的 rr 小了;
- 如果当前左边的数组异或和不为 00, 右边也不为 00,说明当前枚举的 rr 是符合要求的,左右数组异或的结果就是答案;
- 如果当前左边的数组异或和不为 00, 右边为 00,说明当前枚举的 rr 大了;
- 这就是单调的样子。所以可以二分。
记住,只要符合单调,就可以二分!!!
但是,你以为这完了吗?异或和为 0 其实并不代表 要找的元素不在这里面,因为有可能 00 只出现了 11 次! 所以这种思路需要特判一下某个数为 00 的情况。
class Solution {
public int[] singleNumbers(int[] nums) {
int sum = 0, min = Integer.MAX_VALUE, max = Integer.MIN_VALUE, zeroCount = 0;
for (int num : nums) {
if (num == 0) {
zeroCount += 1;
}
min = Math.min(min, num);
max = Math.max(max, num);
sum ^= num;
}
// 需要特判一下某个数是0的情况。
if (zeroCount == 1) {
return new int[]{sum, 0};
}
int lo = min, hi = max;
while (lo <= hi) {
// 根据 lo 的正负性来判断二分位置怎么写,防止越界。
int mid = lo < 0 ? lo + hi >> 1 : lo + (hi - lo) / 2;
int loSum = 0, hiSum = 0;
for (int num : nums) {
if (num <= mid) {
loSum ^= num;
} else {
hiSum ^= num;
}
}
if (loSum != 0 && hiSum != 0) {
// 两个都不为0,说明 p 和 q 分别落到2个数组里了。
return new int[]{loSum, hiSum};
}
if (loSum == 0) {
// 说明 p 和 q 都比 mid 大,所以比 mid 小的数的异或和变为0了。
lo = mid;
} else {
// 说明 p 和 q 都不超过 mid
hi = mid;
}
}
// 其实如果输入是符合要求的,程序不会执行到这里,为了防止compile error加一下
return null;
}
}
二分查找相关题目
参考视频
- 花花酱的二分查找专题视频:https://www.youtube.com/watch?v=v57lNF2mb_s
JPA应用中出现的Exception
java代码
public interface CheckDayInfoRepository extends JpaRepository<CheckDayInfo, Long>, JpaSpecificationExecutor<CheckDayInfo> {
List<CheckDayInfo> findAllByDate(String date);
@Query(value = "SELECT me.address as address,me.totalChecked as totalChecked,info.checked as checked,me.avatar as avatar,info.checkedTime as checkedTime," +
"info.upvoteNumber as upvoteNumber,me.username as username" +
" FROM Member me LEFT JOIN (SELECT * FROM CheckDayInfo WHERE date= ?1 ) info ON me.username=info.username WHERE me.status= 0 " +
"ORDER by info.checked DESC , info.checkedTime DESC",
countQuery = "select COUNT(*) FROM Member me LEFT JOIN (SELECT * FROM CheckDayInfo WHERE date= ?1 ) info " +
"ON me.username=info.username WHERE me.status= 0",
nativeQuery = true)
Page<CheckDayVO> selectCheckInfoByDate(String date, Pageable pageable);
// 查询条件 meusername
@Query(value = "SELECT new com.ojeveryday.backend.pojo.dto.CheckDayVO(me.address,me.totalChecked,info.checked,me.avatar,info.checkedTime,info.upvoteNumber,me.username) " +
"FROM CheckDayInfo info LEFT JOIN Member me ON info.username = me.username and me.status= 0 and info.date = ?1 ORDER by info.checked DESC, info.checkedTime ASC")
Page<CheckDayVO> selectAllByDate(String date, Pageable pageable);
1. 分页异常
错误异常,分页查询报错, Unknown column 'me' in 'field list'
解决方法 可通过自己写 countQuery = 解决
2. No converter found capable of converting from type [org.springframework.data.jpa.repository….
Hibernate: SELECT me.address as address,me.totalChecked as totalChecked,info.checked as checked,me.avatar as avatar,info.checkedTime as checkedTime,info.upvoteNumber as upvoteNumber,me.username as username FROM Member me LEFT JOIN (SELECT * FROM CheckDayInfo WHERE date= ? ) info ON me.username=info.username WHERE me.status= 0 ORDER by info.checked DESC , info.checkedTime DESC limit ?
Hibernate: select COUNT(*) FROM Member me LEFT JOIN (SELECT * FROM CheckDayInfo WHERE date= ? ) info ON me.username=info.username WHERE me.status= 0
2020-04-21 01:49:27.398 ERROR 56349 --- [p-nio-80-exec-1] c.o.b.c.handler.GlobalExceptionHandler : [everyday]-[unknown error happen]-No converter found capable of converting from type [org.springframework.data.jpa.repository.query.AbstractJpaQuery$TupleConverter$TupleBackedMap] to type [com.ojeveryday.backend.pojo.dto.CheckDayVO]
org.springframework.core.convert.ConverterNotFoundException: No converter found capable of converting from type [org.springframework.data.jpa.repository.query.AbstractJpaQuery$TupleConverter$TupleBackedMap] to type [com.ojeveryday.backend.pojo.dto.CheckDayVO]
错误原因 在 nativeQuery = true只能返回 JpaRepository<CheckDayInfo, Long> 中的 CheckDayInfo 而我的方法返回的是 CheckDayVO
3. 在nativeQuery = false 情况下可以指定实体类返回
4. org.springframework.data.mapping.PropertyReferenceException: No property xxxx found for type Xxxx
参考链接
jpa-JpaSpecificationExecutor子查询等功能使用
JpaSpecificationExecutor接口,该接口提供了如下一些方法:
public interface JpaSpecificationExecutor<T> {
T findOne(Specification<T> spec);//根据sql获取单个对象数据
List<T> findAll(Specification<T> spec);//根据sql查询所有数据
Page<T> findAll(Specification<T> spec, Pageable pageable);//根据sql分页查询数据
List<T> findAll(Specification<T> spec, Sort sort); //根据sql查询数据,并根据参数进行排序
long count(Specification<T> spec); //根据sql查询数据总数
}
Sort 的构造函数如下
//可以输入多个Sort.Order对象,在进行多个值排序时有用
public Sort(Sort.Order... orders);
//和上面的方法一样,无非把多个参数换成了一个List
public Sort(List orders);
//当排序方向固定时,使用这个比较方便,第一个参数是排序方向,第二个开始就是排序的字段.
public Sort(Sort.Direction direction, String... properties);
//第一个参数是排序方向,还有一个方法第二个参数是list,原理相同
public Sort(Direction direction, List<String> properties);
Pageable 是一个接口,提供了分页一组方法的声明,如第几页,每页多少条记录,排序信息等
int getPageNumber();
int getPageSize();
int getOffset();
Sort getSort();
Pageable next();
Pageable previousOrFirst();
Pageable first();
boolean hasPrevious();
PageRequest 它是 Pageable 的实现类,它提供三个构造方法
//这个构造方法构造出来的分页对象不具备排序功能
public PageRequest(int page, int size) {
this(page, size, (Sort)null);
}
//Direction和properties用来做排序操作
public PageRequest(int page, int size, Direction direction, String... properties) {
this(page, size, new Sort(direction, properties));
}
//此构造方法是自定义一个排序的操作
public PageRequest(int page, int size, Sort sort) {
super(page, size);
this.sort = sort;
}
Spring Data Jpa 支持 Criteria 查询方式,使用这种方式需要继承JpaSpecificationExecutor,通过实现 Specification 中的 toPredicate方法来定义动态查询,通过 CriteriaBuilder 来创建查询条件
Specification<User> specification = new Specification<User>(){
@Override
public Predicate toPredicate(Root<MessageItem> root, CriteriaQuery<?> query, CriteriaBuilder cb){
List<Predicate> predicates = new ArrayList<Predicate>();
//root.get("name")表示获取name这个字段名称,like表示执行like查询,%zt%表示值
Predicate p1 = cb.like(root.get("name"), "%ray%");
Predicate p2 = cb.greaterThan(root.get("rid"),"3");
//将两个查询条件联合起来之后返回Predicate对象
//建立子查询
//构建criteriaQuery对象
CriteriaQuery<Organization> criteriaQuery = cb.createQuery(Organization.class);
//获取子查询Subquery对象
Subquery<Organization> organizationSubQuery = criteriaQuery.subquery(Organization.class);
//构建新的子查询字段Mapping对象
Root<Organization> organizationSubRoot = organizationubQuery.from(Organization.class);
//相当于sql中的select *,如需获取一个字段可以使用organizationSubRoot.get("字段").as(String.class).
organizationSubQuery.select(organizationSubRoot);
Predicate subqueryPredicate = cb.and(cb.equal(organizationSubRoot .get("rid").as(String.class), root.get("rid").as(String.class),
cb.equal(organizationSubRoot .get("orgName").as(String.class),"部门名称"));
//构建where条件
organizationSubQuery .where(subqueryPredicate);
// exists的使用
Predicate p3 = cb.exists(organizationSubQuery);
//相当于select rid,name...
query.multiselect(root.get("rid"),root.get("name"));
Predicate p4 = cb.and(p1,p2,p3);
predicates.add(p4)
return query.where(predicates.toArray(new Predicate[predicates.size()])).getRestriction();
}
};
利用JpaSpecificationExecutor的findAl方法进行分页查询,例子如下:
Order order = new Order(Direction.ASC,"name");
Sort sort = new Sort(order);
Pageable pageable = new PageRequest(page,size,sort);//page从0开始
Page<User> resutls = UserDao.findAll(specification, pageable);
PS:其中UserDao需要继承JpaSpecificationExecutor和Repository接口。
其实也可以定义多个 Specification,然后通过 Specifications 对象将其连接起来,复杂sql可以这样做,使代码不会这么臃肿。
//第一个Specification定义了两个or的组合
Specification s1 = new Specification() {
@Override
public Predicate toPredicate(Root root, CriteriaQuery criteriaQuery, CriteriaBuilder criteriaBuilder) {
Predicate p1 = criteriaBuilder.equal(root.get("rid"),"2");
Predicate p2 = criteriaBuilder.equal(root.get("rid"),"3");
return criteriaBuilder.or(p1,p2);
}
};
//第二个Specification定义了两个or的组合
Specification s2 = new Specification() {
@Override
public Predicate toPredicate(Root root, CriteriaQuery criteriaQuery, CriteriaBuilder criteriaBuilder) {
Predicate p1 = criteriaBuilder.like(root.get("name"),"r%");
Predicate p2 = criteriaBuilder.like(root.get("name"),"a%");
return criteriaBuilder.or(p1,p2);
}
};
//通过Specifications将两个Specification连接起来,第一个条件加where,第二个是and
List userList= UserDao.findAll(Specifications.where(s1).and(s2));
这个代码生成的 SQL 是
select * from t_user where (rid='2' or rid='3') and (name like 'r%' or name like 'a%');
排序
选择排序
思路
每一轮选取未排定的部分中最小的部分交换到未排定部分的最开头,经过若干个步骤,就能排定整个数组。即:先选出最小的,再选出第 2 小的,以此类推。
参考代码
import java.util.Arrays;
public class Solution {
// 选择排序:每一轮选择最小元素交换到未排定部分的开头
public int[] sortArray(int[] nums) {
int len = nums.length;
// 循环不变量:[0, i) 有序,且该区间里所有元素就是最终排定的样子
for (int i = 0; i < len - 1; i++) {
// 选择区间 [i, len - 1] 里最小的元素的索引,交换到下标 i
int minIndex = i;
for (int j = i + 1; j < len; j++) {
if (nums[j] < nums[minIndex]) {
minIndex = j;
}
}
swap(nums, i, minIndex);
}
return nums;
}
private void swap(int[] nums, int index1, int index2) {
int temp = nums[index1];
nums[index1] = nums[index2];
nums[index2] = temp;
}
public static void main(String[] args) {
int[] nums = {5, 2, 3, 1};
Solution solution = new Solution();
int[] res = solution.sortArray(nums);
System.out.println(Arrays.toString(res));
}
}
总结:
- 算法思想 1:贪心算法:每一次决策只看当前,当前最优,则全局最优。注意:这种思想不是任何时候都适用。
-
算法思想 2:减治思想:外层循环每一次都能排定一个元素,问题的规模逐渐减少,直到全部解决,即「大而化小,小而化了」。运用「减治思想」很典型的算法就是大名鼎鼎的「二分查找」。
- 优点:交换次数最少。
「选择排序」看起来好像最没有用,但是如果在交换成本较高的排序任务中,就可以使用「选择排序」(《算法 4》相关章节课后练习题)。
依然是建议大家不要对算法带有个人色彩,在面试回答问题的时候和看待一个人和事物的时候,可以参考的回答模式是「具体问题具体分析,在什么什么情况下,用什么什么算法」。
复杂度分析:
时间复杂度:O(N^2),这里 NN 是数组的长度;
空间复杂度:O(1),使用到常数个临时变量。
插入排序(熟悉)
思路
思路:每次将一个数字插入一个有序的数组里,成为一个长度更长的有序数组,有限次操作以后,数组整体有序。
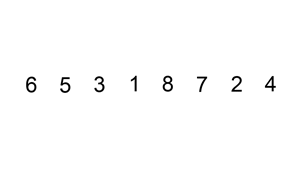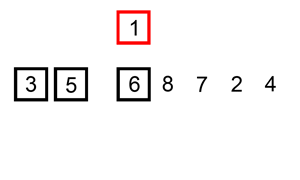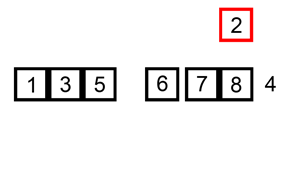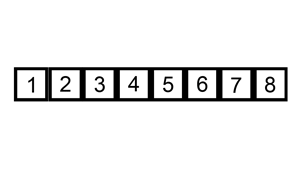
参考代码
public class Solution {
// 插入排序:稳定排序,在接近有序的情况下,表现优异
public int[] sortArray(int[] nums) {
int len = nums.length;
// 循环不变量:将 nums[i] 插入到区间 [0, i) 使之成为有序数组
for (int i = 1; i < len; i++) {
// 先暂存这个元素,然后之前元素逐个后移,留出空位
int temp = nums[i];
int j = i;
// 注意边界 j > 0
while (j > 0 && nums[j - 1] > temp) {
nums[j] = nums[j - 1];
j--;
}
nums[j] = temp;
}
return nums;
}
}
优化:
-
「将一个数字插入一个有序的数组」这一步,可以不使用逐步交换,使用先赋值给「临时变量」,然后「适当的元素」后移,空出一个位置,最后把「临时变量」赋值给这个空位的策略(就是上面那张图的意思)。编码的时候如果不小心,可能会把数组的值修改,建议多调试;
-
特点:「插入排序」可以提前终止内层循环(体现在 nums[j - 1] > temp 不满足时),在数组「几乎有序」的前提下,「插入排序」的时间复杂度可以达到 O(N)O(N);
-
由于「插入排序」在「几乎有序」的数组上表现良好,特别地,在「短数组」上的表现也很好。因为「短数组」的特点是:每个元素离它最终排定的位置都不会太远。为此,在小区间内执行排序任务的时候,可以转向使用「插入排序」。
复杂度分析:
- 时间复杂度:O(N^2),这里 NN 是数组的长度;
- 空间复杂度:O(1),使用到常数个临时变量。
VO与DTO的区别
VO与DTO的区别
既然DTO是展示层与服务层之间传递数据的对象,为什么还需要一个VO呢?对!对于绝大部分的应用场景来说,DTO和VO的属性值基本是一致的,而且他们通常都是POJO,因此没必要多此一举,但不要忘记这是实现层面的思维,对于设计层面来说,概念上还是应该存在VO和DTO,因为两者有着本质的区别,DTO代表服务层需要接收的数据和返回的数据,而VO代表展示层需要显示的数据。
用一个例子来说明可能会比较容易理解:
例如Service层有一个getUser的方法返回一个系统用户,其中有一个属性是gender(性别),对于Service层来说,它只从语义上定义:1-男性,2-女性,0-未指定,而对于展示层来说,它可能需要用“帅哥”代表男性,用“美女”代表女性,用“秘密”代表未指定。说到这里,可能你还会反驳,在服务层直接就返回“帅哥美女”不就行了吗?对于大部分应用来说,这不是问题,但设想一下,如果需求允许客户可以定制风格,而不同风格对于“性别”的表现方式不一样,又或者这个服务同时供多个客户端使用(不同门户),而不同的客户端对于表现层的要求有所不同,那么,问题就来了。再者,回到设计层面上分析,从职责单一原则来看,服务层只负责业务,与具体的表现形式无关,因此,它返回的DTO,不应该出现与表现形式的耦合。 理论归理论,这到底还是分析设计层面的思维,是否在实现层面必须这样做呢?一刀切的做法往往会得不偿失,下面我马上会分析应用中如何做出正确的选择。
VO与DTO的应用
上面只是用了一个简单的例子来说明VO与DTO在概念上的区别,本节将会告诉你如何在应用中做出正确的选择。
在以下才场景中,我们可以考虑把VO与DTO二合为一(注意:是实现层面):
当需求非常清晰稳定,而且客户端很明确只有一个的时候,没有必要把VO和DTO区分开来,这时候VO可以退隐,用一个DTO即可,为什么是VO退隐而不是DTO?回到设计层面,Service层的职责依然不应该与View层耦合,所以,对于前面的例子,你很容易理解,DTO对于“性别”来说,依然不能用“帅哥美女”,这个转换应该依赖于页面的脚本(如JavaScript)或其他机制(JSTL、EL、CSS) 即使客户端可以进行定制,或者存在多个不同的客户端,如果客户端能够用某种技术(脚本或其他机制)实现转换,同样可以让VO退隐
以下场景需要优先考虑VO、DTO并存:
因为某种技术原因,比如某个框架(如Flex)提供自动把POJO转换为UI中某些Field时,可以考虑在实现层面定义出VO,这个权衡完全取决于使用框架的自动转换能力带来的开发和维护效率提升与设计多一个VO所多做的事情带来的开发和维护效率的下降之间的比对。
如果页面出现一个“大视图”,而组成这个大视图的所有数据需要调用多个服务,返回多个DTO来组装(当然,这同样可以通过服务层提供一次性返回一个大视图的DTO来取代,但在服务层提供一个这样的方法是否合适,需要在设计层面进行权衡)。
jpa中sql常见语句使用
jpa中sql常见语句使用
- nativeQuery = true语法 表示使用原生sql
@Query(value = "select * from CheckDayInfo info where info.date = ?1 ORDER by checked ASC, checkedTime ASC", nativeQuery = true)
339 post articles, 43 pages.