724. 寻找数组的中心索引
- 难度:
简单 - 本题涉及算法:
- 思路:
前缀和 - 类似题型:
题目 724. 寻找数组的中心索引
给定一个整数类型的数组 nums,请编写一个能够返回数组“ 中心索引”的方法。
我们是这样定义数组 中心索引 的:数组中心索引的左侧所有元素相加的和等于右侧所有元素相加的和。
如果数组不存在中心索引,那么我们应该返回 -1。如果数组有多个中心索引,那么我们应该返回最靠近左边的那一个。
示例 1:
输入:
nums = [1, 7, 3, 6, 5, 6]
输出: 3
解释:
索引3 (nums[3] = 6) 的左侧数之和(1 + 7 + 3 = 11),与右侧数之和(5 + 6 = 11)相等。
同时, 3 也是第一个符合要求的中心索引。
示例 2:
输入:
nums = [1, 2, 3]
输出: -1
解释:
数组中不存在满足此条件的中心索引。
思路一 暴力
public int pivotIndex(int[] nums) {
int sum=0,sumLeft = 0,sumRight = 0;
for (int n:nums){
sum = sum + n;
}
for (int i=0;i<nums.length;i++){
if (i==0){
sumLeft = 0;
}else {
sumLeft = sumLeft + nums[i-1];
}
sumRight = sum - sumLeft - nums[i];
if (sumLeft==sumRight){
return i;
}
}
return -1;
}
思路二 前缀和
- 左求和*2+中心索引值 = 总和
java
class Solution {
public int pivotIndex(int[] nums) {
int length = nums.length;
int sum = 0, leftSum = 0;
// 获取数组元素总和
for (int num: nums) sum += num;
// 遍历自变量
for (int i = 0; i < length; i++){
if (leftSum*2 == sum - nums[i]) return i;
leftSum += nums[i];
}
return -1;
}
}
python
class Solution(object):
def pivotIndex(self, nums):
S = sum(nums)
leftsum = 0
for i, x in enumerate(nums):
if leftsum == (S - leftsum - x):
return i
leftsum += x
return -1
7. 整数反转
- 难度:
简单 - 本题涉及算法:
- 思路:
算数 - 类似题型:
题目 7. 整数反转
给出一个 32 位的有符号整数,你需要将这个整数中每位上的数字进行反转。
示例1
输入: 123
输出: 321
示例 2:
输入: -123
输出: -321
示例 3:
输入: 120
输出: 21
注意:
假设我们的环境只能存储得下 32 位的有符号整数,则其数值范围为 [−231, 231 − 1]。请根据这个假设,如果反转后整数溢出那么就返回 0。
方法一 算数
- 注意事项:
- 反转后的值可能会溢出
- 使用 python 区摸需要考虑 负数情况
- python中 取摸 取整除 需要注意 和java不一样
python 中 -1%10 = 9 , -1//10=-1 java 中 -1%10 = 1 , -1//10=0
java
public int reverse(int x) {
long n = 0;
while (x != 0) {
n = n * 10 + x % 10;
x = x / 10;
}
return (int)n == n ? (int)n:0;
}
python
class Solution(object):
def reverse(self, x):
ans = 0
flag = 1
if x <0:
x = -x;
flag = -flag
while x != 0:
cur = x % 10
ans = ans*10 + cur
x //= 10
return ans*flag if -2**31 <ans*flag <2**31 else 0
方法二 转String 在反转
java
ublic int reverse(int x) {
String a = Integer.toString(x);
int b = 1;
if(a.charAt(0) == '-') {
a = a.substring(1);
b = -1;
}
char[] chars = a.toCharArray();
char[] chars1 = new char[chars.length];
for (int i = chars.length - 1; i >= 0; i--) {
chars1[chars.length - 1 - i] = chars[i];
}
Long aLong = Long.valueOf(new String(chars1));
if(aLong > Integer.MAX_VALUE || aLong < Integer.MIN_VALUE) {
return 0;
}
return (int) (aLong * b);
}
445. 两数相加 II
- 难度:
中等 - 本题涉及算法:
栈 - 思路:
栈 - 类似题型:
题目 445. 两数相加 II
给你两个 非空 链表来代表两个非负整数。数字最高位位于链表开始位置。它们的每个节点只存储一位数字。将这两数相加会返回一个新的链表。
你可以假设除了数字 0 之外,这两个数字都不会以零开头。
示例
输入:(7 -> 2 -> 4 -> 3) + (5 -> 6 -> 4)
输出:7 -> 8 -> 0 -> 7
解题思路
- 使用堆保存链表,保存结果如[1,2,3,4]
- 通过堆的pop方法从尾部依次获取数据
- pop()函数返回栈顶的元素,并且将该栈顶元素出栈。
代码
java
class Solution {
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
Stack<Integer> stack1 = new Stack<>();
Stack<Integer> stack2 = new Stack<>();
while (l1 != null) {
stack1.push(l1.val);
l1 = l1.next;
}
while (l2 != null) {
stack2.push(l2.val);
l2 = l2.next;
}
// 很妙的两个地方 carry 的设置 和 carry >0 的判断 🌟🌟🌟🌟🌟
// 记录和大于10时 +1
// carry >0 当大于10 则向前进 1
int carry = 0;
ListNode head = null;
while (!stack1.isEmpty() || !stack2.isEmpty() || carry > 0) {
int sum = carry;
sum += stack1.isEmpty()? 0: stack1.pop();
sum += stack2.isEmpty()? 0: stack2.pop();
ListNode node = new ListNode(sum % 10);
node.next = head;
head = node;
carry = sum / 10;
}
return head;
}
}
python
class Solution:
def addTwoNumbers(self, l1: ListNode, l2: ListNode) -> ListNode:
stack1, stack2 = [], []
while l1:
stack1.append(l1.val)
l1 = l1.next
while l2:
stack2.append(l2.val)
l2 = l2.next
ans = None
carry = 0
while stack1 or stack2 or carry != 0:
sumNum = carry
sumNum += 0 if not stack1 else stack1.pop()
sumNum += 0 if not stack2 else stack2.pop()
curlNode = ListNode(sumNum % 10)
curlNode.next = ans
ans = curlNode
carry = sumNum // 10
return ans
121. 买卖股票的最佳时机
- 难度:
简单 - 本题涉及算法:
动态规划暴力 - 思路:
动态规划暴力 - 类似题型:
题目 买卖股票的最佳时机
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
如果你最多只允许完成一笔交易(即买入和卖出一支股票一次),设计一个算法来计算你所能获取的最大利润。
注意:你不能在买入股票前卖出股票。
示例 1:
输入: [7,1,5,3,6,4]
输出: 5
解释: 在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格。
示例 2:
输入: [7,6,4,3,1]
输出: 0
解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。
方法一 暴力
public lass Solution {
public int maxProfit(int[] prices) {
int res = 0;
for(int i=0;i<prices.length;i++) {
for(int j=i+1;j<prices.length;j++) {
int subtract = prices[i]-prices[j];
if(subtract<0&&subtract<res) {
res = subtract;
}
}
}
return -res;
}
}
方法二:动态规划
java
class Solution {
public int maxProfit(int[] prices) {
// 很巧妙的设计 设计最大值和最小值的比较
int minprice = Integer.MAX_VALUE;
int maxprice = 0;
for(int price:prices){
minprice = Math.min(minprice,price);
maxprice = Math.max(maxprice,price-minprice);
}
return maxprice;
}
}
python
class Solution:
def maxProfit(self,prices: List[int]) ->int:
minprice = float('inf')
maxprofit = 0
for price in prices:
minprice = min(minprice,price)
maxprofit = max(maxprofit,price-minprice)
return maxprofit
面试题29. 顺时针打印矩阵(模拟、设定边界,清晰图解)
- 难度:
简单 - 本题涉及算法:
- 思路:
- 类似题型:
题目 顺时针打印矩阵
输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字。
示例 1:
输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[1,2,3,6,9,8,7,4,5]
示例 2:
输入:matrix = [[1,2,3,4],[5,6,7,8],[9,10,11,12]]
输出:[1,2,3,4,8,12,11,10,9,5,6,7]
限制:
0 <= matrix.length <= 100
0 <= matrix[i].length <= 100
方法一
解题思路:
根据题目示例 matrix = [[1,2,3],[4,5,6],[7,8,9]] 的对应输出 [1,2,3,6,9,8,7,4,5] 可以发现,顺时针打印矩阵的顺序是 “从左向右、从上向下、从右向左、从下向上” 循环。
- 因此,考虑设定矩阵的“左、上、右、下”四个边界,模拟以上矩阵遍历顺序。

算法流程:
- 空值处理: 当 matrix 为空时,直接返回空列表 [] 即可。
- 初始化: 矩阵 左、右、上、下 四个边界 l , r , t , b ,用于打印的结果列表 res 。
- 循环打印: “从左向右、从上向下、从右向左、从下向上” 四个方向循环,每个方向打印中做以下三件事 (各方向的具体信息见下表) ;
- 1). 根据边界打印,即将元素按顺序添加至列表 res 尾部;
- 2). 边界向内收缩 11 (代表已被打印);
- 3). 判断是否打印完毕(边界是否相遇),若打印完毕则跳出。
- 返回值: 返回 res 即可。
| 打印方向 | 1. 根据边界打印 | 2. 边界向内收缩 | 3. 是否打印完毕 |
|---|---|---|---|
| 从左向右 | 左边界l ,右边界 r | 上边界 t 加 11 | 是否 t > b |
| 从上向下 | 上边界 t ,下边界b | 右边界 r 减 11 | 是否 l > r |
| 从右向左 | 右边界 r ,左边界l | 下边界 b 减 11 | 是否 t > b |
| 从下向上 | 下边界 b ,上边界t | 左边界 l 加 11 | 是否 l > r |
复杂度分析:
- 时间复杂度 O(MN)O(MN) : M, NM,N 分别为矩阵行数和列数。
- 空间复杂度 O(1)O(1) : 四个边界 l , r , t , b 使用常数大小的 额外 空间( res 为必须使用的空间)。
代码
java
class Solution {
public int[] spiralOrder(int[][] matrix) {
if(matrix.length == 0) return new int[0];
int l = 0, r = matrix[0].length - 1, t = 0, b = matrix.length - 1, x = 0;
int[] res = new int[(r + 1) * (b + 1)];
while(true) {
for(int i = l; i <= r; i++) res[x++] = matrix[t][i]; // left to right.
if(++t > b) break;
for(int i = t; i <= b; i++) res[x++] = matrix[i][r]; // top to bottom.
if(l > --r) break;
for(int i = r; i >= l; i--) res[x++] = matrix[b][i]; // right to left.
if(t > --b) break;
for(int i = b; i >= t; i--) res[x++] = matrix[i][l]; // bottom to top.
if(++l > r) break;
}
return res;
}
}
python
class Solution:
def spiralOrder(self, matrix:[[int]]) -> [int]:
if not matrix: return []
l, r, t, b, res = 0, len(matrix[0]) - 1, 0, len(matrix) - 1, []
while True:
for i in range(l, r + 1): res.append(matrix[t][i]) # left to right
t += 1
if t > b: break
for i in range(t, b + 1): res.append(matrix[i][r]) # top to bottom
r -= 1
if l > r: break
for i in range(r, l - 1, -1): res.append(matrix[b][i]) # right to left
b -= 1
if t > b: break
for i in range(b, t - 1, -1): res.append(matrix[i][l]) # bottom to top
l += 1
if l > r: break
return res
springboot自定义参数解析HandlerMethodArgumentResolver
简介
自定义解析器需要实现 HandlerMethodArgumentResolver 接口, HandlerMethodArgumentResolver 接口包含两个接口函数:
public interface HandlerMethodArgumentResolver {
boolean supportsParameter(MethodParameter var1);
@Nullable
Object resolveArgument(MethodParameter var1, @Nullable ModelAndViewContainer var2, NativeWebRequest var3, @Nullable WebDataBinderFactory var4) throws Exception;
}
自定义一个解析器CurrentUserMethodArgumentResolver
我们在解析器中返回一个固定的 UserBeannew UserBean(1L,”admin”) ,实际情况是从Session、数据库或者缓存中查。
import org.springframework.core.MethodParameter;
import org.springframework.web.bind.support.WebDataBinderFactory;
import org.springframework.web.context.request.NativeWebRequest;
import org.springframework.web.method.support.HandlerMethodArgumentResolver;
import org.springframework.web.method.support.ModelAndViewContainer;
/**
* 用于绑定@CurrentUser的方法参数解析器
*
* @author lism
*/
public class CurrentUserMethodArgumentResolver implements HandlerMethodArgumentResolver {
public CurrentUserMethodArgumentResolver() {
}
@Override
public boolean supportsParameter(MethodParameter parameter) {
if (parameter.getParameterType().isAssignableFrom(UserBean.class) && parameter.hasParameterAnnotation(CurrentUser.class)) {
return true;
}
return false;
}
@Override
public Object resolveArgument(MethodParameter parameter, ModelAndViewContainer mavContainer, NativeWebRequest webRequest, WebDataBinderFactory binderFactory) throws Exception {
CurrentUser currentUserAnnotation = parameter.getParameterAnnotation(CurrentUser.class);
//从Session 获取用户
Object object = webRequest.getAttribute(currentUserAnnotation.value(), NativeWebRequest.SCOPE_SESSION);
//从 accessToken获得用户信息
if (object == null) {
String token = webRequest.getHeader("Authorization");
if (token == null) {
token = webRequest.getParameter("accessToken");
}
//为了测试先写死用户名
//TODO: 取真实用户
return new UserBean(1L,"admin");
}
return object;
}
}
自定义注解@CurrentUser
import java.lang.annotation.*;
/**
* <p>绑定当前登录的用户</p>
* <p>不同于@ModelAttribute</p>
*
* @author lism
*/
@Target({ElementType.PARAMETER})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface CurrentUser {
/**
* 当前用户在request中的名字
*
* @return
*/
String value() default "user";
}
在控制器中使用@CurrentUser
在控制器方法上加入 @CurrentUser UserBean userBean 即可自动注入userBean的值
@RestController
@RequestMapping(value = "/test")
public class TestController {
/**
* 根据name查询
*
* @param request
* @return
*/
@RequestMapping(value = "/testCurrentUser", method = RequestMethod.POST, produces = "application/json", consumes = "application/json")
@ResponseBody
public void test(@CurrentUser UserBean userBean, @RequestBody SubjectRequest request) {
String createdBy = userBean.getUsername();
log.info(createdBy);
}
}
User实体UserBean
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class UserBean implements Serializable {
private Long id;
private String username;
}
总结
我们可以通过实现 HandlerMethodArgumentResolver 接口来实现对自定义的参数进行解析。 比如可以解析自定义的时间格式、自定义解析Map对象等这些spring原本不支持的对象格式。
198. 打家劫舍
- 难度:
简单 - 本题涉及算法:
动态规划 - 思路:
动态规划 - 类似题型:
题目 198. 打家劫舍
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你在不触动警报装置的情况下,能够偷窃到的最高金额。
示例 1:
输入: [1,2,3,1]
输出: 4
解释: 偷窃 1 号房屋 (金额 = 1) ,然后偷窃 3 号房屋 (金额 = 3)。
偷窃到的最高金额 = 1 + 3 = 4 。
示例 2:
输入: [2,7,9,3,1]
输出: 12
解释: 偷窃 1 号房屋 (金额 = 2), 偷窃 3 号房屋 (金额 = 9),接着偷窃 5 号房屋 (金额 = 1)。
偷窃到的最高金额 = 2 + 9 + 1 = 12 。
方法一 动态规划
- 如图
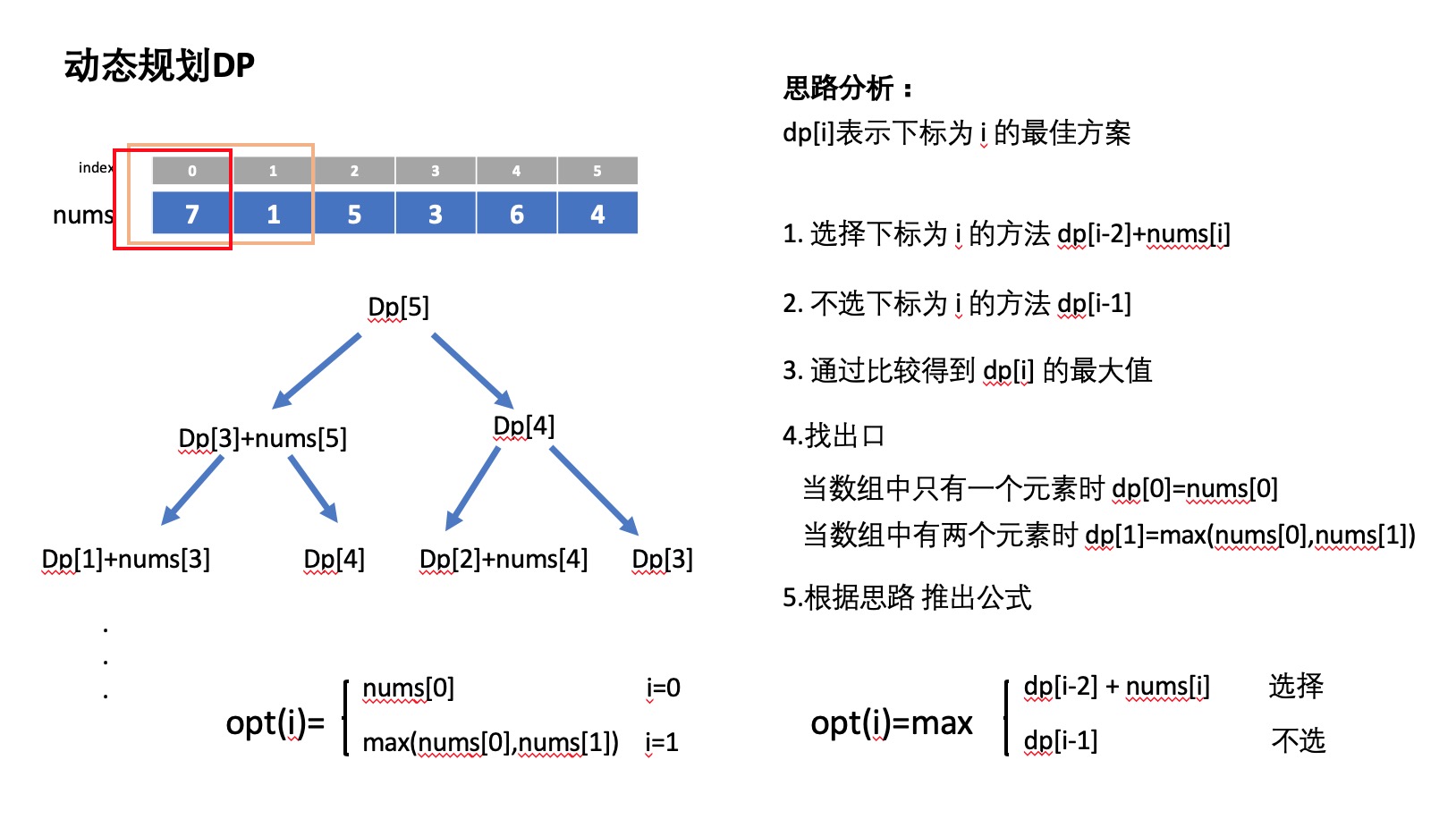
java
class Solution {
public int rob(int[] nums) {
int len = nums.length;
if (len == 0) return 0;
if (len == 1) return nums[0];
int[] dp = new int[len];
dp[0] = nums[0];
dp[1] = Math.max(nums[0], nums[1]);
for (int i = 2; i < len; i++) {
dp[i] = Math.max(dp[i - 1], dp[i - 2] + nums[i]);
}
return dp[len - 1];
}
}
python
class Solution(object):
def rob(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
len_nums = len(nums)
if not nums: # 当没有可抢房间
return 0
if len_nums == 1: # 当只有一家可抢
return nums[0]
dp = [0] * len_nums
dp[0] = nums[0]
dp[1] = max(nums[0],nums[1])
for i in range(2,len_nums):
dp[i] = max(dp[i-1],dp[i-2]+nums[i])
return dp[len_nums-1]
十二种排序算法
前言
排序算法在计算机科学入门课程中很普遍,在学习排序算法的时候,涉及到大量的各种核心算法概念,例如大O表示法,分治法,堆和二叉树之类的数据结构,随机算法,最佳、最差和平均情况分析,时空权衡以及上限和下限,本文就介绍了十二种排序算法供大家学习。
简介
排序算法是用来根据元素对应的比较运算符重新排列给定的数组的算法,输出的数组是一个根据比较符从小到大或者从大到小依次排列的数组。比较运算符是用于确定相应数据结构中元素的新顺序,比如在整数数组里面,对应的比较符号就是大于或者小于号,用户也可以自己定义对应的比较运算符。
比如如果输入是 [4,2,3,1],按照从小到大输出,结果应该是 [1,2,3,4]
特性
稳定性
如果在数组中有两个元素是相等的,在经过某个排序算法之后,原来在前面的的那个元素仍然在另一个元素的前面,那么我们就说这个排序算法是稳定的。

如果在排序之后,原来的两个相等元素中在前面的一个元素被移到了后面,那么这个算法就是不稳定的。
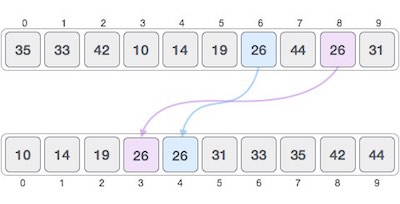
比如排序之前数组为 [3(a),2,3(b)](其中a和b分别代表两个不同的3),经过某个排序算法之后是 [2,3(a),3(b)],那么这个算法就是稳定的;如果变成了 [2,3(b),3(a)],那么这个算法是不稳定的。
再比如在按照身高排队去食堂打饭的过程中,小明和小刚的身高都是170,原来小明在小刚前面,但是经过排序之后小明发现小刚到了他前面了,这样小明肯定对这个不稳定的排序有意见。
时间复杂度
时间复杂度反映了算法的排序效率,通常用大O表示法来表示,通常暗示这个算法需要的最多操作次数的量级,比如O(n)O(n)表示最多需要进行nn量级操作。
空间复杂度
空间复杂度反映了算法需要消耗的空间,比如O(1)O(1)表示只需要常数量级的空间,不会随着数组大小的变化而变化。
如果一个排序算法不需要额外的存储空间,可以直接在原来的数组完成排序操作,这个算法可以被称之为原地算法,空间复杂度是O(1)O(1)
比较排序、非比较排序
如果一个算法需要在排序的过程中使用比较操作来判断两个元素的大小关系,那么这个排序算法就是比较排序,大部分排序算法都是比较排序,比如冒泡排序、插入排序、堆排序等等,这种排序算法的平均时间复杂度最快也只能是O(nlogn)O(nlogn)。
非比较排序比较典型的有计数排序、桶排序和基数排序,这类排序能够脱离比较排序时间复杂度的束缚,达到O(n)O(n)级别的效率。
算法
首先定义基本的交换数组元素的基本方法,节省后面的代码量。
private void swap(int[] nums, int i, int j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
冒泡排序
冒泡排序是从左到右依次比较相邻的两个元素,如果前一个元素比较大,就把前一个元素和后一个交换位置,遍历数组之后保证最后一个元素相对于前面的永远是最大的。然后让最后一个保持不变,重新遍历前n-1个元素,保证第n-1个元素在前n-1个元素里面是最大的。依此规律直到第2个元素是前2个元素里面最大的,排序就结束了。
因为这个排序的过程很像冒泡泡,找到最大的元素不停的移动到最后端,所以这个排序算法就叫冒泡排序。
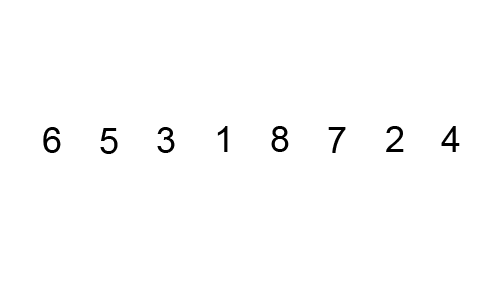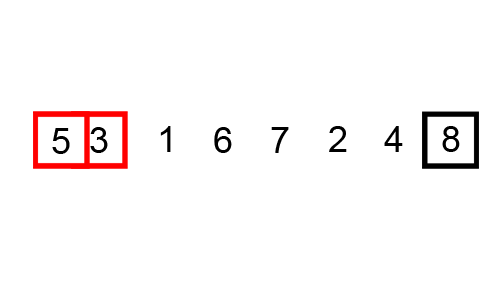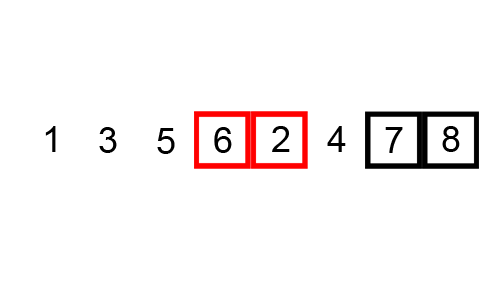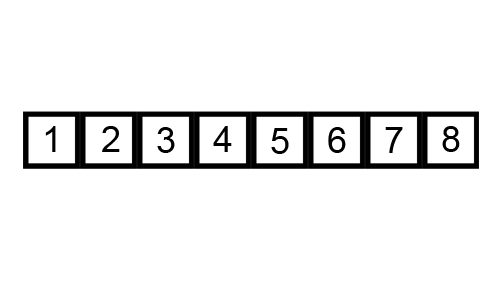
private void bubbleSort(int[] nums) {
for (int i = nums.length - 1; i >= 1; i--) { // 冒泡得到n-1个最大值
for (int j = 1; j <= i; j++) {
if (nums[j-1]>nums[j])
swap(nums, j, j-1); // 交换得到较大值
}
}
}
冒泡排序的最大特点就是代码简单,短短的五行代码就能完成整个排序的操作。
时间复杂度比较稳定不管怎样都需要O(n^2)次比较,所以是O(n^2)的时间复杂度。
空间复杂度是O(1)O(1),所有操作在原来的数组完成就可以了,不需要额外的空间。
算法是稳定的,在冒泡的过程中如果两个元素相等,那么他们的位置是不会交换的。
选择排序
选择排序的思路比较简单,先找到前n个元素中最大的值,然后和最后一个元素交换,这样保证最后一个元素一定是最大的,然后找到前n-1个元素中的最大值,和第n-1个元素进行交换,然后找到前n-2个元素中最大值,和第n-2个元素交换,依次类推到第2个元素,这样就得到了最后的排序数组。
其实整个过程和冒泡排序差不多,都是要找到最大的元素放到最后,不同点是冒泡排序是不停的交换元素,而选择排序只需要在每一轮交换一次。

代码实现:
private void selectionSort(int[] nums) {
for (int i = nums.length - 1; i > 0; i--) {
int maxIndex = 0; // 最大元素的位置
for (int j = 0; j <= i; j++) {
if (nums[maxIndex]<nums[j]) {
maxIndex = j;
}
}
swap(nums, maxIndex, i); // 把这个最大的元素移到最后
}
}
时间复杂度和冒泡排序一样比较稳定,都需要O(n^2)次比较,所以时间复杂度是O(n^2)
空间复杂度是O(1)O(1),不需要额外空间,是原地算法。
选择排序最简单的版本是不稳定的,比如数组 [1,3,2,2],表示为 [1,3,2(a),2(b)],在经过一轮遍历之后变成了 [1,2(b),2(a),3],两个2之间的顺序因为第一个2和3的调换而颠倒了,所以不是稳定排序。
不过可以改进一下选择排序变成稳定的。原来不稳定是因为交换位置导致的,现在如果改成 插入操作(不是使用数组而是链表,把最大的元素插入到最后)的话,就能变成稳定排序。比如 [1,3,2(a),2(b)],在第一轮中变成了 [1,2(a),2(b),3],这样就能够保持相对位置,变成稳定排序。
插入排序
插入排序的核心思想是遍历整个数组,保持当前元素左侧始终是排序后的数组,然后将当前元素插入到前面排序完成的数组的对应的位置,使其保持排序状态。有点动态规划的感觉,类似于先把前i-1个元素排序完成,再插入第i个元素,构成i个元素的有序数组。

简单代码实现:
private void insertionSort(int[] nums) {
for (int i = 1; i < nums.length; i++) { // 从第二个元素开始遍历
int j = i;
while (j>0&&nums[j]<nums[j-1]) { // 将当前元素移动到合适的位置
swap(nums, j, j-1);
j--;
}
}
}
时间复杂度上,插入排序在最好的情况,也就是数组已经排好序的时候,复杂度是O(n),在其他情况下都是O(n^2)。
空间复杂度是O(1),不需要额外的空间,是原地算法。
插入排序是稳定排序,每次交换都是相邻元素的交换,不会有选择排序的那种跳跃式交换元素。
希尔排序
希尔排序可以看作是一个冒泡排序或者插入排序的变形。希尔排序在每次的排序的时候都把数组拆分成若干个序列,一个序列的相邻的元素索引相隔的固定的距离gap,每一轮对这些序列进行冒泡或者插入排序,然后再缩小gap得到新的序列一一排序,直到gap为0
比如对于数组 [5,2,4,3,1,2],第一轮gap=3拆分成[5,3]、[2,1]和[4,2]三个数组进行插入排序得到 [3,1,2,5,2,4];第二轮gap=1,拆分成 [3,2,2] 和 [1,5,4] 进行插入排序得到 [2,1,2,4,3,5];最后gap=0,全局插入排序得到 [1,2,2,3,4,5]
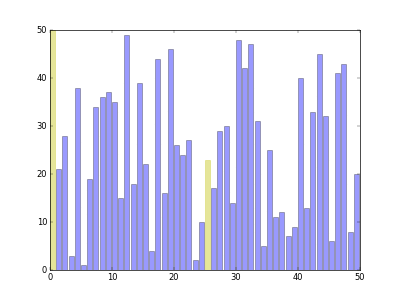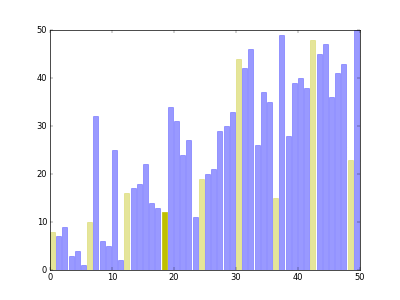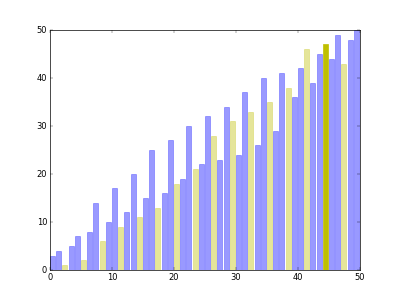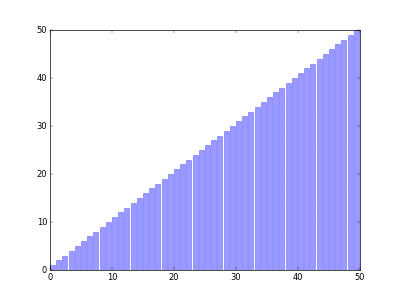
简单代码实现:
private void shellSor2(int[] nums) {
int gap = nums.length >> 1;
while (gap > 0) {
for (int i = 0; i < gap; i++) { // 对每个子序列进行排序
for (int j = i+gap; j < nums.length; j+=gap) { // 插入排序的部分
int temp = j;
while (temp > i && nums[temp] < nums[temp-gap]) {
swap(nums, temp, temp-gap);
temp -= gap;
}
}
}
gap >>= 1;
}
}
Donald Shell于1959年发布了这种排序算法,运行时间在很大程度上取决于它使用的间隔,在实际使用中,其时间复杂度仍然是一个悬而未决的问题,基本在O(n^2)和O(n^{4/3})之间。
空间复杂度是O(1),是原地算法。
这个算法是不稳定的,里面有很多不相邻元素的交换操作。
归并排序
归并排序是典型的使用 分治思想(divide-and-conquer)解决问题的案例。在排序的过程中,把原来的数组变成左右两个数组,然后分别进行排序,当左右的子数组排序完毕之后,再合并这两个子数组形成一个新的排序数组。整个过程递归进行,当只剩下一个元素或者没有元素的时候就直接返回。

代码如下:
private void mergeSort(int[] nums, int left, int right) { // 需要左右边界确定排序范围
if (left >= right) return;
int mid = (left+right) / 2;
mergeSort(nums, left, mid); // 先对左右子数组进行排序
mergeSort(nums, mid+1, right);
int[] temp = new int[right-left+1]; // 临时数组存放合并结果
int i=left,j=mid+1;
int cur = 0;
while (i<=mid&&j<=right) { // 开始合并数组
if (nums[i]<=nums[j]) temp[cur] = nums[i++];
else temp[cur] = nums[j++];
cur++;
}
while (i<=mid) temp[cur++] = nums[i++];
while (j<=right) temp[cur++] = nums[j++];
for (int k = 0; k < temp.length; k++) { // 合并数组完成,拷贝到原来的数组中
nums[left+k] = temp[k];
}
}
时间复杂度上归并排序能够稳定在O(nlogn)的水平,在每一级的合并排序数组过程中总的操作次数是n,总的层级数是logn,相乘得到最后的结果就是O(nlogn)
空间复杂度是O(n),因为在合并的过程中需要使用临时数组来存放临时排序结果。
归并排序是稳定排序,保证原来相同的元素能够保持相对的位置。
快速排序
快速排序(有时称为分区交换排序)是一种高效的排序算法。由英国计算机科学家Tony Hoare于1959年开发并于1961年发表,它在现在仍然是一种常用的排序算法。如果实现方法恰当,它可以比主要竞争对手(归并排序和堆排序)快两到三倍。
其核心的思路是取第一个元素(或者最后一个元素)作为分界点,把整个数组分成左右两侧,左边的元素小于或者等于分界点元素,而右边的元素大于分界点元素,然后把分界点移到中间位置,对左右子数组分别进行递归,最后就能得到一个排序完成的数组。当子数组只有一个或者没有元素的时候就结束这个递归过程。
其中最重要的是将整个数组根据分界点元素划分成左右两侧的逻辑,目前有两种算法,图片展示的是第一种。

第一种实现,也是图片中的排序逻辑的实现:
private void quickSort(int[] nums, int left, int right) {
if (left >= right) return;
int lo = left+1; // 小于分界点元素的最右侧的指针
int hi = right; // 大于分界点元素的最左侧的指针
while (lo<=hi) {
if (nums[lo]>nums[left]) { // 交换元素确保左侧指针指向元素小于分界点元素
swap(nums, lo, hi);
hi--;
} else {
lo++;
}
}
lo--; // 回到小于分界点元素数组的最右侧
swap(nums, left, lo); // 将分界点元素移到左侧数组最右侧
quickSort2(nums, left, lo-1);
quickSort2(nums, lo+1, right);
}
第二种,不用hi来标记大于分界点元素的最右侧,而是只用一个lo来标记最左侧。在遍历整个数组的过程中,如果发现了一个小于等于分界点元素的元素,就和lo+1位置的元素交换,然后lo自增,这样可以保证lo的左侧一定都是小于等于分界点元素的,遍历到最后lo的位置就是新的分界点位置,和最开始的分界点元素位置互换。
private void quickSort(int[] nums, int left, int right) {
if (left>=right) return;
int cur = left + 1; // 从左侧第二个元素开始
int lo = left; // 分界点为第一个元素
while (cur <= right) {
if (nums[cur] <= nums[left]) { // 交换位置保证lo的左侧都是小于num[left]
swap(nums, lo+1, cur);
lo ++;
}
cur++;
}
swap(nums, left, lo); // 把分界点元素移动到新的分界位置
quickSort(nums, left, lo-1);
quickSort(nums, lo+1, right);
}
时间复杂度在最佳情况是O(nlogn),但是如果分界点元素选择不当可能会恶化到O(n^2),但是这种情况比较少见(比如数组完全逆序),如果随机选择分界点的话,时间复杂度能够稳定在O(nlogn)。另外如果元素中相同元素数量比较多的话,也会降低排序性能。
空间复杂度在O(logn)水平,属于堆栈调用,在最坏的情况下空间复杂度还是O(n),平均情况下复杂度是O(logn)
快速排序是不稳定的,因为包含跳跃式交换元素位置。
堆排序
堆排序是一个效率要高得多的选择排序,首先把整个数组变成一个最大堆,然后每次从堆顶取出最大的元素,这样依次取出的最大元素就形成了一个排序的数组。堆排序的核心分成两个部分,第一个是新建一个堆,第二个是弹出堆顶元素后重建堆。
新建堆不需要额外的空间,而是使用原来的数组,一个数组在另一个维度上可以当作一个完全二叉树(除了最后一层之外其他的每一层都被完全填充,并且所有的节点都向左对齐),对于下标为i的元素,他的子节点是2i+1和2i+2(前提是没有超出边界)。在新建堆的时候从左向右开始遍历,当遍历到一个元素的时候,重新排列从这个元素节点到根节点的所有元素,保证满足最大堆的要求(父节点比子节点要大)。遍历完整个数组的时候,这个最大堆就完成了。
在弹出根节点之后(把根节点的元素和树的最底层最右侧的元素互换),堆被破坏,需要重建。从根节点开始和两个子节点比较,如果父节点比最大的子节点小,那么就互换父节点和最大的子节点,然后把互换后在子节点位置的父节点当作新的父节点,和它的子节点比较,如此往复直到最后一层,这样最大堆就重建完毕了。

简单java代码:
private void heapSort(int[] nums) {
heapify(nums); // 新建一个最大堆
for (int i = nums.length - 1; i >= 1; i--) {
swap(nums, 0, i); // 弹出最大堆的堆顶放在最后
rebuildHeap(nums, 0,i-1); // 重建最大堆
}
}
private void heapify(int[] nums) {
for (int i = 1; i < nums.length; i++) {
int par = (i-1)>>1; // 找到父节点
int child = i; // 定义子节点
while (child>0&&nums[par]<nums[child]) { // 从子节点到根节点构建最大堆
swap(nums, par, child);
child = par;
par = (par-1) >> 1;
}
}
}
private void rebuildHeap(int[] nums, int par, int last) {
int left = 2*par+1; // 左子节点
int right = 2*par+2; // 右子节点
int maxIndex = left;
if (right<=last && nums[right]>nums[left]) { // 找到最大子节点
maxIndex = right;
}
if (left<=last && nums[par] < nums[maxIndex]) {// 和最大子节点比较
swap(nums, par, maxIndex); // 互换到最大子节点
rebuildHeap(nums, maxIndex, last); // 重建最大子节点代表的子树
}
}
时间复杂度稳定在O(nlogn),因为在构建堆的时候时间遍历数组对于每个元素需要进行O(logn)次比较,时间复杂度是O(nlogn)。在弹出每个元素重建堆需要O(logn)的复杂度,时间复杂度也是O(nlogn),所以整体的时间复杂度是O(nlogn)
空间复杂度是O(1),在原数组进行所有操作就可以了。
堆排序是不稳定,堆得构建和重建的过程都会打乱元素的相对位置。
堆排序的代码量相对于其他的排序算法来说是比较多的,理解上也比较难,涉及到最大堆和二叉树等相关概念。虽然在实际使用中相对于快速排序不是那么好用,但是最坏情况下的O(nlogn)的时间复杂度也是优于快排的。空间使用是恒定的,是优于归并排序。
二叉搜索树排序
二叉树搜索排序用数组内的所有元素构建一个搜索二叉树,然后用中序遍历重新将所有的元素填充回原来的数组中。因为搜索二叉树不能用数组来表示,所以必须使用额外的数据结构来构建二叉树。

简单代码如下
private int[] bstSort(int[] nums) {
TreeNode root = new TreeNode(nums[0]); // 构建根节点
for (int i = 1; i < nums.length; i++) { // 将所有的元素插入到二叉搜索树中
buildTree(root, nums[i]);
}
inorderTraversal(root, nums, new int[1]);// 中序遍历获取二叉树中的所有节点
return nums;
}
private void inorderTraversal(TreeNode node, int[] nums, int[] pos) {
if (node == null) return;
inorderTraversal(node.left, nums, pos);
nums[pos[0]++] = node.val;
inorderTraversal(node.right, nums, pos);
}
private void buildTree(TreeNode node, int num) {
if (node == null) return;
if (num >= node.val) { // 插入到右子树中
if (node.right == null) {
node.right = new TreeNode(num);
} else {
buildTree(node.right, num);
}
} else { // 插入到左子树中
if (node.left == null) {
node.left = new TreeNode(num);
} else {
buildTree(node.left, num);
}
}
}
static class TreeNode { // 树节点的数据结构
int val;
TreeNode left;
TreeNode right;
public TreeNode(int val) {
this.val = val;
}
}
时间复杂度上面根据原数组变化比较大,最差情况是整个数组是已经排好序的,这样二叉树会变成一个链表结构,时间复杂度退化到了O(n^2),但是最优和平均情况下时间复杂度在O(nlogn)水平。
空间复杂度是O(n),因为要构建一个包含n个元素的二叉搜索树。
这个算法是稳定,在构建二叉树的过程中能够保证元素顺序的一致性。
计数排序
计数排序是一个最基本的非比较排序,能够将时间复杂度提高到O(n)O(n)的水平,但是使用上比较有局限性,通常只能应用在键的变化范围比较小的情况下,如果键的变化范围特别大,建议使用基数排序。
计数排序的过程是创建一个长度为数组中最小和最大元素之差的数组,分别对应数组中的每个元素,然后用这个新的数组来统计每个元素出现的频率,然后遍历新的数组,根据每个元素出现的频率把元素放回到老的数组中,得到已经排好序的数组。

简单代码实现:
private void countSort(int[] nums) {
int min = Integer.MAX_VALUE;
int max = Integer.MIN_VALUE;
for (int num : nums) { // 找到最大最小值
min = Math.min(min, num);
max = Math.max(max, num);
}
int[] count = new int[max-min+1]; // 建立新数组
for (int num : nums) { // 统计每个元素出现频率
count[num-min]++;
}
int cur = 0;
for (int i = 0; i < count.length; i++) { // 根据出现频率把计数数组中的元素放回到旧数组中
while (count[i]>0) {
nums[cur++] = i+min;
count[i]--;
}
}
}
计数排序能够将时间复杂度降低到O(n+r)(r为数组元素变化范围),不过这是对于数组元素的变化范围不是特别大。随着范围的变大,计数排序的性能就会逐渐降低。
空间复杂度为O(n+r),随着数组元素变化范围的增大,空间复杂度也会变大。
计数排序是稳定的,原来排在前面的相同在计数的时候,仍然是排在每个计数位置的前面,在最后复原的时候也是从每个计数位的前面开始复原,所以最后相对位置还是相同的。
桶排序
桶排序是将所有的元素分布到一系列的区间(也可以称之为桶)里面,然后对每个桶里面的所有元素分别进行排序的算法。
首先新建一个桶的数组,每个桶的规则需要提前制定好,比如元素在0~9为一个桶、10~19为一个桶。然后遍历整个待排序的数组,把元素分配到对应的桶里面。接下来单独对每个桶里面的元素进行排序,排序算法可以选择比较排序或者非比较排序,得到排序后的数组。最后把所有的桶内的元素还原到原数组里面得到最后的排序数组。
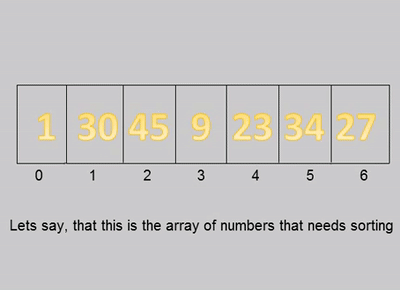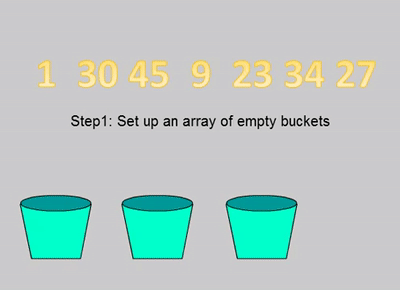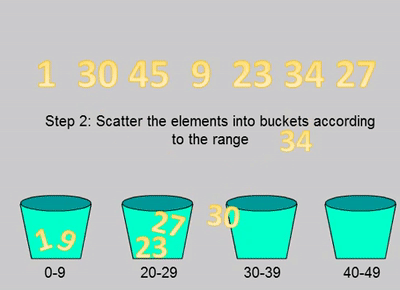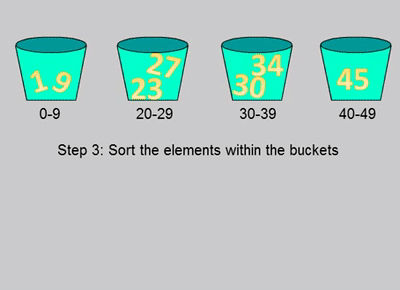
private void bucketSort(int[] nums) {
int INTERVAL = 100; // 定义桶的大小
int min = Integer.MAX_VALUE;
int max = Integer.MIN_VALUE;
for (int num : nums) { // 找到数组元素的范围
min = Math.min(min, num);
max = Math.max(max, num);
}
int count = (max - min + 1); // 计算出桶的数量
int bucketSize = (count % INTERVAL == 0) ?( count / INTERVAL) : (count / INTERVAL+1);
List<Integer>[] buckets = new List[bucketSize];
for (int num : nums) { // 把所有元素放入对应的桶里面
int quotient = (num-min) / INTERVAL;
if (buckets[quotient] == null) buckets[quotient] = new ArrayList<>();
buckets[quotient].add(num);
}
int cur = 0;
for (List<Integer> bucket : buckets) {
if (bucket != null) {
bucket.sort(null); // 对每个桶进行排序
for (Integer integer : bucket) { // 还原桶里面的元素到原数组
nums[cur++] = integer;
}
}
}
}
时间复杂度上桶排序和计数排序一样,是O(n+r)的水平,但是随着数据元素范围的增大,时间消耗也在增大。
空间复杂度也是O(n+r),需要额外的空间来保存所有的桶和桶里面的元素。
桶排序是稳定的(前提是桶内排序的逻辑是稳定的),和计数排序的逻辑类似,遍历过程插入桶的过程中没有改变相同元素的相对位置,排序也没有改变,最后的还原也没有改变。
基数排序
基数排序和桶排序有点相似,基数排序中需要把元素送入对应的桶中,不过规则是根据所有数字的某一位上面的数字来分类。
假设当前数组的所有元素都是正数,桶的数量就固定在了10个,然后计算出最大元素的位数。首先根据每个元素的最低位进行分组,比如1就放入1这个桶,13就放入3这个桶,111也放入1这个桶,然后把所有的数字根据桶的顺序取出来,依次还原到原数组里面。在第二轮从第二位开始分组,比如1(看作01)放入0这个桶,13放入1这个桶,111也放入1这个桶,再把所有的元素从桶里面依次取出放入原数组。经过最大元素位数次的这样的操作之后,还原得到的数组就是一个已经排好序的数组。

考虑到数组里面还有负数的情况,可以把桶的大小扩大到19个,分别代表对应位在-9~9之间的数字,代码如下:
private void radixSort(int[] nums) {
int max = -1;
int min = 1;
for (int num : nums) { // 计算最大最小值
max = Math.max(max, num);
min = Math.min(min, num);
}
max = Math.max(max, -min); // 求得绝对值最大的值
int digits = 0;
while (max > 0) { // 计算绝对值最大的值的位数
max /= 10;
digits++;
}
List<Integer>[] buckets = new List[19]; // 建一个包含所有位数的数组
for (int i = 0; i < buckets.length; i++) {
buckets[i] = new ArrayList<>();
}
int pos;
int cur;
for (int i = 0, mod = 1; i < digits; i++, mod*=10) { // 对十进制每一位进行基数排序
for (int num : nums) { // 扫描数组将值放入对应的桶
pos = (num / mod) % 10;
buckets[pos+9].add(num);
}
cur = 0;
for (List<Integer> bucket : buckets) { // 将桶内元素放回到数组里面
if (bucket!=null) {
for (Integer integer : bucket) {
nums[cur++] = integer;
}
bucket.clear(); // 将桶清空
}
}
}
}
时间复杂度基本在O(n*k/d)水平,其中kk为key的总数量,dd为绝对值最大的数字的十进制位数。
空间复杂度是O(n+2^d)。
基数排序是一个稳定排序算法,在排序添加元素的过程中没有改变相同元素的相互位置。
TimSort
Timsort是由Tim Peters在2002年实现的,自Python 2.3以来,它一直是Python的标准排序算法。Java在JDK中使用Timsort对非基本类型进行排序。Android平台和GNU Octave还将其用作默认排序算法。
Timsort是一种稳定的混合排序算法,同时应用了二分插入排序和归并排序的思想,在时间上击败了其他所有排序算法。它在最坏情况下的时间复杂度为O(nlogn)优于快速排序;最佳情况的时间复杂度为O(n),优于归并排序和堆排序。
由于使用了归并排序,使用额外的空间保存数据,TimSort空间复杂度是O(n)
由于篇幅原因,TimSort的具体实现过程暂且就不讲了,会有一篇专门的文章来介绍TimSort。
总结
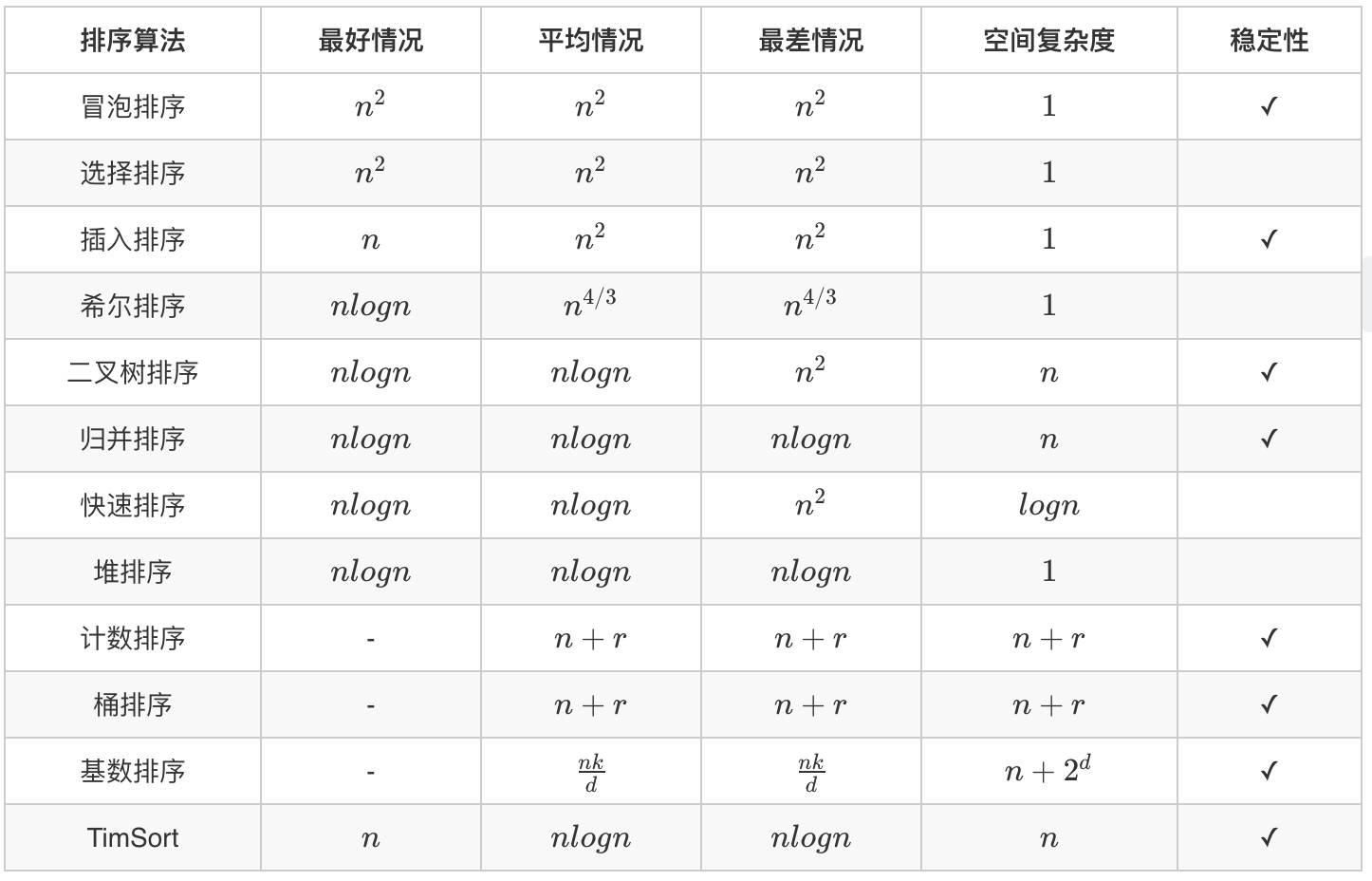
备注:rr为排序数字的范围,dd是数字总位数,kk是数字总个数
上面的表格总结了讲到的排序算法的时间和空间复杂度以及稳定性等,在实际应用中会有各种排序算法变形的问题,都可以通过优化排序算法来达到优化算法的目的。
如果对时间复杂度要求比较高并且键的分布范围比较广,可以使用归并排序、快速排序和堆排序。
如果不能使用额外的空间,那么快速排序和堆排序都是不错的选择。
如果规定了排序的键的范围,可以优先考虑使用桶排序。
如果不想写太多的代码同时时间复杂度没有太高的要求,可以考虑冒泡排序、选择排序和插入排序。
如果排序的过程中没有复杂的额外操作,直接使用编程语言内置的排序算法就行了。
339 post articles, 43 pages.